-
 @ 9727846a:00a18d90
2025-04-13 09:16:41
@ 9727846a:00a18d90
2025-04-13 09:16:41李承鹏:什么加税导致社会巨变,揭竿而起……都不说三千年饿殍遍野,易子而食,只要给口吃的就感谢皇恩浩荡。就说本朝,借口苏修卡我们脖子,几亿人啃了三年树皮,民兵端着枪守在村口,偷摸逃出去的都算勇士。
也不说98年总理大手一挥,一句“改革”,六千万工人下岗,基本盘稳得很。就像电影《钢的琴》里那群东北下岗工人,有的沦落街头,有的拉起乐队在婚礼火葬场做红白喜事,有的靠倒卖废弃钢材被抓,有的当小偷撬门溜锁,还有卖猪肉的,有去当小姐的……但人们按着中央的话语,说这叫“解放思想”。
“工人要替国家想,我不下岗谁下岗”,这是1999年春晚黄宏的小品,你现在觉得反人性,那时台下一片掌声,民间也很亢奋,忽然觉得自己有了力量。人们很容易站在国家立场把自己当炮灰,人民爱党爱国,所以操心什么加税,川普还能比斯大林同志赫鲁晓夫同志更狠吗,生活还能比毛主席时代更糟吗。不就是农产品啊牛肉啊芯片贵些,股票跌些,本来就生存艰难的工厂关的多些,大街上发呆眼神迷茫的人多些,跳楼的年轻人密集些,河里总能捞出不明来历的浮尸……但十五亿人民,会迅速稀释掉这些人和事。比例极小,信心极大,我们祖祖辈辈在从人到猪的生活转换适应力上,一直为世间翘楚。
民心所向,正好武统。
这正是想要的。没有一个帝王会关心你的生活质量,他只关心权力和帝国版图是否稳当。
而这莫名其妙又会和人民的想法高度契合,几千年来如此。所以聊一会儿就会散的,一定散的,只是会在明年春晚以另一种高度正能量的形式展现。
您保重。 25年4月9日
-
@ f7f4e308:b44d67f4
2025-04-09 02:12:18
https://sns-video-hw.xhscdn.com/stream/1/110/258/01e7ec7be81a85850103700195f3c4ba45_258.mp4
-
@ 04c915da:3dfbecc9
2025-03-12 15:30:46
Recently we have seen a wave of high profile X accounts hacked. These attacks have exposed the fragility of the status quo security model used by modern social media platforms like X. Many users have asked if nostr fixes this, so lets dive in. How do these types of attacks translate into the world of nostr apps? For clarity, I will use X’s security model as representative of most big tech social platforms and compare it to nostr.
The Status Quo
On X, you never have full control of your account. Ultimately to use it requires permission from the company. They can suspend your account or limit your distribution. Theoretically they can even post from your account at will. An X account is tied to an email and password. Users can also opt into two factor authentication, which adds an extra layer of protection, a login code generated by an app. In theory, this setup works well, but it places a heavy burden on users. You need to create a strong, unique password and safeguard it. You also need to ensure your email account and phone number remain secure, as attackers can exploit these to reset your credentials and take over your account. Even if you do everything responsibly, there is another weak link in X infrastructure itself. The platform’s infrastructure allows accounts to be reset through its backend. This could happen maliciously by an employee or through an external attacker who compromises X’s backend. When an account is compromised, the legitimate user often gets locked out, unable to post or regain control without contacting X’s support team. That process can be slow, frustrating, and sometimes fruitless if support denies the request or cannot verify your identity. Often times support will require users to provide identification info in order to regain access, which represents a privacy risk. The centralized nature of X means you are ultimately at the mercy of the company’s systems and staff.
Nostr Requires Responsibility
Nostr flips this model radically. Users do not need permission from a company to access their account, they can generate as many accounts as they want, and cannot be easily censored. The key tradeoff here is that users have to take complete responsibility for their security. Instead of relying on a username, password, and corporate servers, nostr uses a private key as the sole credential for your account. Users generate this key and it is their responsibility to keep it safe. As long as you have your key, you can post. If someone else gets it, they can post too. It is that simple. This design has strong implications. Unlike X, there is no backend reset option. If your key is compromised or lost, there is no customer support to call. In a compromise scenario, both you and the attacker can post from the account simultaneously. Neither can lock the other out, since nostr relays simply accept whatever is signed with a valid key.
The benefit? No reliance on proprietary corporate infrastructure.. The negative? Security rests entirely on how well you protect your key.
Future Nostr Security Improvements
For many users, nostr’s standard security model, storing a private key on a phone with an encrypted cloud backup, will likely be sufficient. It is simple and reasonably secure. That said, nostr’s strength lies in its flexibility as an open protocol. Users will be able to choose between a range of security models, balancing convenience and protection based on need.
One promising option is a web of trust model for key rotation. Imagine pre-selecting a group of trusted friends. If your account is compromised, these people could collectively sign an event announcing the compromise to the network and designate a new key as your legitimate one. Apps could handle this process seamlessly in the background, notifying followers of the switch without much user interaction. This could become a popular choice for average users, but it is not without tradeoffs. It requires trust in your chosen web of trust, which might not suit power users or large organizations. It also has the issue that some apps may not recognize the key rotation properly and followers might get confused about which account is “real.”
For those needing higher security, there is the option of multisig using FROST (Flexible Round-Optimized Schnorr Threshold). In this setup, multiple keys must sign off on every action, including posting and updating a profile. A hacker with just one key could not do anything. This is likely overkill for most users due to complexity and inconvenience, but it could be a game changer for large organizations, companies, and governments. Imagine the White House nostr account requiring signatures from multiple people before a post goes live, that would be much more secure than the status quo big tech model.
Another option are hardware signers, similar to bitcoin hardware wallets. Private keys are kept on secure, offline devices, separate from the internet connected phone or computer you use to broadcast events. This drastically reduces the risk of remote hacks, as private keys never touches the internet. It can be used in combination with multisig setups for extra protection. This setup is much less convenient and probably overkill for most but could be ideal for governments, companies, or other high profile accounts.
Nostr’s security model is not perfect but is robust and versatile. Ultimately users are in control and security is their responsibility. Apps will give users multiple options to choose from and users will choose what best fits their need.
-
@ eb35d9c0:6ea2b8d0
2025-03-02 00:55:07
I had a ton of fun making this episode of Midnight Signals. It taught me a lot about the haunting of the Bell family and the demise of John Bell. His death was attributed to the Bell Witch making Tennessee the only state to recognize a person's death to the supernatural.
If you enjoyed the episode, visit the Midnight Signals site. https://midnightsignals.net
Show Notes
Journey back to the early 1800s and the eerie Bell Witch haunting that plagued the Bell family in Adams, Tennessee. It began with strange creatures and mysterious knocks, evolving into disembodied voices and violent attacks on young Betsy Bell. Neighbors, even Andrew Jackson, witnessed the phenomena, adding to the legend. The witch's identity remains a mystery, sowing fear and chaos, ultimately leading to John Bell's tragic demise. The haunting waned, but its legacy lingers, woven into the very essence of the town. Delve into this chilling story of a family's relentless torment by an unseen force.
Transcript
Good evening, night owls. I'm Russ Chamberlain, and you're listening to midnight signals, the show, where we explore the darkest corners of our collective past. Tonight, our signal takes us to the early 1800s to a modest family farm in Adams, Tennessee. Where the Bell family encountered what many call the most famous haunting in American history.
Make yourself comfortable, hush your surroundings, and let's delve into this unsettling tale. Our story begins in 1804, when John Bell and his wife Lucy made their way from North Carolina to settle along the Red River in northern Tennessee. In those days, the land was wide and fertile, mostly unspoiled with gently rolling hills and dense woodland.
For the Bells, John, Lucy, and their children, The move promised prosperity. They arrived eager to farm the rich soil, raise livestock, and find a peaceful home. At first, life mirrored [00:01:00] that hope. By day, John and his sons worked tirelessly in the fields, planting corn and tending to animals, while Lucy and her daughters managed the household.
Evenings were spent quietly, with scripture readings by the light of a flickering candle. Neighbors in the growing settlement of Adams spoke well of John's dedication and Lucy's gentle spirit. The Bells were welcomed into the Fold, a new family building their future on the Tennessee Earth. In those early years, the Bells likely gave little thought to uneasy rumors whispered around the region.
Strange lights seen deep in the woods, soft cries heard by travelers at dusk, small mysteries that most dismissed as product of the imagination. Life on the frontier demanded practicality above all else, leaving little time to dwell on spirits or curses. Unbeknownst to them, events on their farm would soon dominate not only their lives, but local lore for generations to come.[00:02:00]
It was late summer, 1817, when John Bell's ordinary routines took a dramatic turn. One evening, in the waning twilight, he spotted an odd creature near the edge of a tree line. A strange beast resembling part dog, part rabbit. Startled, John raised his rifle and fired, the shot echoing through the fields. Yet, when he went to inspect the spot, nothing remained.
No tracks, no blood, nothing to prove the creature existed at all. John brushed it off as a trick of falling light or his own tired eyes. He returned to the house, hoping for a quiet evening. But in the days that followed, faint knocking sounds began at the windows after sunset. Soft scratching rustled against the walls as if curious fingers or claws tested the timbers.
The family's dog barked at shadows, growling at the emptiness of the yard. No one considered it a haunting at first. Life on a rural [00:03:00] farm was filled with pests, nocturnal animals, and the countless unexplained noises of the frontier. Yet the disturbances persisted, night after night, growing a little bolder each time.
One evening, the knocking on the walls turned so loud it woke the entire household. Lamps were lit, doors were open, the ground searched, but the land lay silent under the moon. Within weeks, the unsettling taps and scrapes evolved into something more alarming. Disembodied voices. At first, the voices were faint.
A soft murmur in rooms with no one in them. Betsy Bell, the youngest daughter, insisted she heard her name called near her bed. She ran to her mother and her father trembling, but they found no intruder. Still, The voice continued, too low for them to identify words, yet distinct enough to chill the blood.
Lucy Bell began to fear they were facing a spirit, an unclean presence that had invaded their home. She prayed for divine [00:04:00] protection each evening, yet sometimes the voice seemed to mimic her prayers, twisting her words into a derisive echo. John Bell, once confident and strong, grew unnerved. When he tried reading from the Bible, the voice mocked him, imitating his tone like a cruel prankster.
As the nights passed, disturbances gained momentum. Doors opened by themselves, chairs shifted with no hand to move them, and curtains fluttered in a room void of drafts. Even in daytime, Betsy would find objects missing, only for them to reappear on the kitchen floor or a distant shelf. It felt as if an unseen intelligence roamed the house, bent on sowing chaos.
Of all the bells, Betsy suffered the most. She was awakened at night by her hair being yanked hard enough to pull her from sleep. Invisible hands slapped her cheeks, leaving red prints. When she walked outside by day, she heard harsh whispers at her ear, telling her she would know [00:05:00] no peace. Exhausted, she became withdrawn, her once bright spirit dulled by a ceaseless fear.
Rumors spread that Betsy's torment was the worst evidence of the haunting. Neighbors who dared spend the night in the Bell household often witnessed her blankets ripped from the bed, or watched her clutch her bruised arms in distress. As these accounts circulated through the community, people began referring to the presence as the Bell Witch, though no one was certain if it truly was a witch's spirit or something else altogether.
In the tightly knit town of Adams, word of the strange happenings at the Bell Farm soon reached every ear. Some neighbors offered sympathy, believing wholeheartedly that the family was besieged by an evil force. Others expressed skepticism, guessing there must be a logical trick behind it all. John Bell, ordinarily a private man, found himself hosting visitors eager to witness the so called witch in action.
[00:06:00] These visitors gathered by the parlor fireplace or stood in darkened hallways, waiting in tense silence. Occasionally, the presence did not appear, and the disappointed guests left unconvinced. More often, they heard knocks vibrating through the walls or faint moans drifting between rooms. One man, reading aloud from the Bible, found his words drowned out by a rasping voice that repeated the verses back at him in a warped, sing song tone.
Each new account that left the bell farm seemed to confirm the unearthly intelligence behind the torment. It was no longer mere noises or poltergeist pranks. This was something with a will and a voice. Something that could think and speak on its own. Months of sleepless nights wore down the Bell family.
John's demeanor changed. The weight of the haunting pressed on him. Lucy, steadfast in her devotion, prayed constantly for deliverance. The [00:07:00] older Bell children, seeing Betsy attacked so frequently, tried to shield her but were powerless against an enemy that slipped through walls. Farming tasks were delayed or neglected as the family's time and energy funneled into coping with an unseen assailant.
John Bell began experiencing health problems that no local healer could explain. Trembling hands, difficulty swallowing, and fits of dizziness. Whether these ailments arose from stress or something darker, they only reinforced his sense of dread. The voice took to mocking him personally, calling him by name and snickering at his deteriorating condition.
At times, he woke to find himself pinned in bed, unable to move or call out. Despite it all, Lucy held the family together. Soft spoken and gentle, she soothed Betsy's tears and administered whatever remedies she could to John. Yet the unrelenting barrage of knocks, whispers, and violence within her own home tested her faith [00:08:00] daily.
Amid the chaos, Betsy clung to one source of joy, her engagement to Joshua Gardner, a kind young man from the area. They hoped to marry and begin their own life, perhaps on a parcel of the Bell Land or a new farmstead nearby. But whenever Joshua visited the Bell Home, The unseen spirit raged. Stones rattled against the walls, and the door slammed as if in warning.
During quiet walks by the river, Betsy heard the voice hiss in her ear, threatening dire outcomes if she ever were to wed Joshua. Night after night, Betsy lay awake, her tears soaked onto her pillow as she wrestled with the choice between her beloved fiancé and this formidable, invisible foe. She confided in Lucy, who offered comfort but had no solution.
For a while, Betsy and Joshua resolved to stand firm, but the spirit's fury only escalated. Believing she had no alternative, Betsy broke off the engagement. Some thought the family's [00:09:00] torment would subside if the witches demands were met. In a cruel sense, it seemed to succeed. With Betsy's engagement ended, the spirit appeared slightly less focused on her.
By now, the Bell Witch was no longer a mere local curiosity. Word of the haunting spread across the region and reached the ears of Andrew Jackson, then a prominent figure who would later become president. Intrigued, or perhaps skeptical, he traveled to Adams with a party of men to witness the phenomenon firsthand.
According to popular account, the men found their wagon inexplicably stuck on the road near the Bell property, refusing to move until a disembodied voice commanded them to proceed. That night, Jackson's men sat in the Bell parlor, determined to uncover fraud if it existed. Instead, they found themselves subjected to jeering laughter and unexpected slaps.
One boasted of carrying a special bullet that could kill any spirit, only to be chased from the house in terror. [00:10:00] By morning, Jackson reputedly left, shaken. Although details vary among storytellers, the essence of his experience only fueled the legend's fire. Some in Adams took to calling the presence Kate, suspecting it might be the spirit of a neighbor named Kate Batts.
Rumors pointed to an old feud or land dispute between Kate Batts and John Bell. Whether any of that was true, or Kate Batts was simply an unfortunate scapegoat remains unclear. The entity itself, at times, answered to Kate when addressed, while at other times denying any such name. It was a puzzle of contradictions, claiming multiple identities.
A wayward spirit, a demon, or a lost soul wandering in malice. No single explanation satisfied everyone in the community. With Betsy's engagement to Joshua broken, the witch devoted increasing attention to John Bell. His health declined rapidly in 1820, marked by spells of near [00:11:00] paralysis and unremitting pain.
Lucy tended to him day and night. Their children worried and exhausted, watched as their patriarch grew weaker, his once strong presence withering under an unseen hand. In December of that year, John Bell was found unconscious in his bed. A small vial of dark liquid stood nearby. No one recognized its contents.
One of his sons put a single drop on the tongue of the family cat, which died instantly. Almost immediately, the voice shrieked in triumph, boasting that it had given John a final, fatal dose. That same day, John Bell passed away without regaining consciousness, leaving his family both grief stricken and horrified by the witch's brazen gloating.
The funeral drew a large gathering. Many came to mourn the respected farmer. Others arrived to see whether the witch would appear in some dreadful form. As pallbearers lowered John Bell's coffin, A jeering laughter rippled across the [00:12:00] mourners, prompting many to look wildly around for the source. Then, as told in countless retellings, the voice broke into a rude, mocking song, echoing among the gravestones and sending shudders through the crowd.
In the wake of John Bell's death, life on the farm settled into an uneasy quiet. Betsy noticed fewer night time assaults. And the daily havoc lessened. People whispered that the witch finally achieved its purpose by taking John Bell's life. Then, just as suddenly as it had arrived, the witch declared it would leave the family, though it promised to return in seven years.
After a brief period of stillness, the witch's threat rang true. Around 1828, a few of the Bells claimed to hear light tapping or distant murmurs echoing in empty rooms. However, these new incidents were mild and short lived compared to the previous years of torment. Soon enough, even these faded, leaving the bells [00:13:00] with haunted memories, but relative peace.
Near the bell property stood a modest cave by the Red River, a spot often tied to the legend. Over time, people theorized that cave's dark recesses, though the bells themselves rarely ventured inside. Later visitors and locals would tell of odd voices whispering in the cave or strange lights gliding across the damp stone.
Most likely, these stories were born of the haunting's lingering aura. Yet, they continued to fuel the notion that the witch could still roam beyond the farm, hidden beneath the earth. Long after the bells had ceased to hear the witch's voice, the story lived on. Word traveled to neighboring towns, then farther, into newspapers and traveler anecdotes.
The tale of the Tennessee family plagued by a fiendish, talkative spirit captured the imagination. Some insisted the Bell Witch was a cautionary omen of what happens when old feuds and injustices are left [00:14:00] unresolved. Others believed it was a rare glimpse of a diabolical power unleashed for reasons still unknown.
Here in Adams, people repeated the story around hearths and campfires. Children were warned not to wander too far near the old bell farm after dark. When neighbors passed by at night, they might hear a faint rustle in the bush or catch a flicker of light among the trees, prompting them to walk faster.
Hearts pounding, minds remembering how once a family had suffered greatly at the hands of an unseen force. Naturally, not everyone agreed on what transpired at the Bell farm. Some maintained it was all too real, a case of a vengeful spirit or malignant presence carrying out a personal vendetta. Others whispered that perhaps a member of the Bell family had orchestrated the phenomenon with cunning trickery, though that failed to explain the bruises on Betsy, the widespread witnesses, or John's mysterious death.
Still, others pointed to the possibility of an [00:15:00] unsettled spirit who had attached itself to the land for reasons lost to time. What none could deny was the tangible suffering inflicted on the Bells. John Bell's slow decline and Betsy's bruises were impossible to ignore. Multiple guests, neighbors, acquaintances, even travelers testified to hearing the same eerie voice that threatened, teased and recited scripture.
In an age when the supernatural was both feared and accepted, the Bell Witch story captured hearts and sparked endless speculation. After John Bell's death, the family held onto the farm for several years. Betsy, robbed of her engagement to Joshua, eventually found a calmer path through life, though the memory of her tormented youth never fully left her.
Lucy, steadfast and devout to the end, kept her household as best as she could, unwilling to surrender her faith even after all she had witnessed. Over time, the children married and started families of their own, [00:16:00] quietly distancing themselves from the tragedy that had defined their upbringing.
Generations passed, the farm changed hands, the Bell House was repurposed and renovated, and Adams itself transformed slowly from a frontier settlement into a more established community. Yet the name Bellwitch continued to slip into conversation whenever strange knocks were heard late at night or lonely travelers glimpsed inexplicable lights in the distance.
The story refused to fade, woven into the identity of the land itself. Even as the first hand witnesses to the haunting aged and died, their accounts survived in letters, diaries, and recollections passed down among locals. Visitors to Adams would hear about the famed Bell Witch, about the dreadful death of John Bell, the heartbreak of Betsy's broken engagement, and the brazen voice that filled nights with fear.
Some folks approached the story with reverence, others with skepticism. But no one [00:17:00] denied that it shaped the character of the town. In the hush of a moonlit evening, one might stand on that old farmland, fields once tilled by John Bell's callous hands, now peaceful beneath the Tennessee sky. And imagine the entire family huddled in the house, listening with terrified hearts for the next knock on the wall.
It's said that if you pause long enough, you might sense a faint echo of their dread, carried on a stray breath of wind. The Bell Witch remains a singular chapter in American folklore, a tale of a family besieged by something unseen, lethal, and uncannily aware. However one interprets the events, whether as vengeful ghosts, demonic presence, or some other unexplainable force, the Bell Witch.
Its resonance lies in the very human drama at its core. Here was a father undone by circumstances he could not control. A daughter tormented in her own home, in a close knit household tested by relentless fear. [00:18:00] In the end, the Bell Witch story offers a lesson in how thin the line between our daily certainties and the mysteries that defy them.
When night falls, and the wind rattles the shutters in a silent house, we remember John Bell and his family, who discovered that the safe haven of home can become a battlefield against forces beyond mortal comprehension. I'm Russ Chamberlain, and you've been listening to Midnight Signals. May this account of the Bell Witch linger with you as a reminder that in the deepest stillness of the night, Anything seems possible.
Even the unseen tapping of a force that seeks to make itself known. Sleep well, if you dare.
-
@ 460c25e6:ef85065c
2025-02-25 15:20:39
If you don't know where your posts are, you might as well just stay in the centralized Twitter. You either take control of your relay lists, or they will control you. Amethyst offers several lists of relays for our users. We are going to go one by one to help clarify what they are and which options are best for each one.
Public Home/Outbox Relays
Home relays store all YOUR content: all your posts, likes, replies, lists, etc. It's your home. Amethyst will send your posts here first. Your followers will use these relays to get new posts from you. So, if you don't have anything there, they will not receive your updates.
Home relays must allow queries from anyone, ideally without the need to authenticate. They can limit writes to paid users without affecting anyone's experience.
This list should have a maximum of 3 relays. More than that will only make your followers waste their mobile data getting your posts. Keep it simple. Out of the 3 relays, I recommend: - 1 large public, international relay: nos.lol, nostr.mom, relay.damus.io, etc. - 1 personal relay to store a copy of all your content in a place no one can delete. Go to relay.tools and never be censored again. - 1 really fast relay located in your country: paid options like http://nostr.wine are great
Do not include relays that block users from seeing posts in this list. If you do, no one will see your posts.
Public Inbox Relays
This relay type receives all replies, comments, likes, and zaps to your posts. If you are not getting notifications or you don't see replies from your friends, it is likely because you don't have the right setup here. If you are getting too much spam in your replies, it's probably because your inbox relays are not protecting you enough. Paid relays can filter inbox spam out.
Inbox relays must allow anyone to write into them. It's the opposite of the outbox relay. They can limit who can download the posts to their paid subscribers without affecting anyone's experience.
This list should have a maximum of 3 relays as well. Again, keep it small. More than that will just make you spend more of your data plan downloading the same notifications from all these different servers. Out of the 3 relays, I recommend: - 1 large public, international relay: nos.lol, nostr.mom, relay.damus.io, etc. - 1 personal relay to store a copy of your notifications, invites, cashu tokens and zaps. - 1 really fast relay located in your country: go to nostr.watch and find relays in your country
Terrible options include: - nostr.wine should not be here. - filter.nostr.wine should not be here. - inbox.nostr.wine should not be here.
DM Inbox Relays
These are the relays used to receive DMs and private content. Others will use these relays to send DMs to you. If you don't have it setup, you will miss DMs. DM Inbox relays should accept any message from anyone, but only allow you to download them.
Generally speaking, you only need 3 for reliability. One of them should be a personal relay to make sure you have a copy of all your messages. The others can be open if you want push notifications or closed if you want full privacy.
Good options are: - inbox.nostr.wine and auth.nostr1.com: anyone can send messages and only you can download. Not even our push notification server has access to them to notify you. - a personal relay to make sure no one can censor you. Advanced settings on personal relays can also store your DMs privately. Talk to your relay operator for more details. - a public relay if you want DM notifications from our servers.
Make sure to add at least one public relay if you want to see DM notifications.
Private Home Relays
Private Relays are for things no one should see, like your drafts, lists, app settings, bookmarks etc. Ideally, these relays are either local or require authentication before posting AND downloading each user\'s content. There are no dedicated relays for this category yet, so I would use a local relay like Citrine on Android and a personal relay on relay.tools.
Keep in mind that if you choose a local relay only, a client on the desktop might not be able to see the drafts from clients on mobile and vice versa.
Search relays:
This is the list of relays to use on Amethyst's search and user tagging with @. Tagging and searching will not work if there is nothing here.. This option requires NIP-50 compliance from each relay. Hit the Default button to use all available options on existence today: - nostr.wine - relay.nostr.band - relay.noswhere.com
Local Relays:
This is your local storage. Everything will load faster if it comes from this relay. You should install Citrine on Android and write ws://localhost:4869 in this option.
General Relays:
This section contains the default relays used to download content from your follows. Notice how you can activate and deactivate the Home, Messages (old-style DMs), Chat (public chats), and Global options in each.
Keep 5-6 large relays on this list and activate them for as many categories (Home, Messages (old-style DMs), Chat, and Global) as possible.
Amethyst will provide additional recommendations to this list from your follows with information on which of your follows might need the additional relay in your list. Add them if you feel like you are missing their posts or if it is just taking too long to load them.
My setup
Here's what I use: 1. Go to relay.tools and create a relay for yourself. 2. Go to nostr.wine and pay for their subscription. 3. Go to inbox.nostr.wine and pay for their subscription. 4. Go to nostr.watch and find a good relay in your country. 5. Download Citrine to your phone.
Then, on your relay lists, put:
Public Home/Outbox Relays: - nostr.wine - nos.lol or an in-country relay. -
.nostr1.com Public Inbox Relays - nos.lol or an in-country relay -
.nostr1.com DM Inbox Relays - inbox.nostr.wine -
.nostr1.com Private Home Relays - ws://localhost:4869 (Citrine) -
.nostr1.com (if you want) Search Relays - nostr.wine - relay.nostr.band - relay.noswhere.com
Local Relays - ws://localhost:4869 (Citrine)
General Relays - nos.lol - relay.damus.io - relay.primal.net - nostr.mom
And a few of the recommended relays from Amethyst.
Final Considerations
Remember, relays can see what your Nostr client is requesting and downloading at all times. They can track what you see and see what you like. They can sell that information to the highest bidder, they can delete your content or content that a sponsor asked them to delete (like a negative review for instance) and they can censor you in any way they see fit. Before using any random free relay out there, make sure you trust its operator and you know its terms of service and privacy policies.
-
@ 09fbf8f3:fa3d60f0
2025-02-17 15:23:11
🌟 深度探索:在Cloudflare上免费部署DeepSeek-R1 32B大模型
🌍 一、 注册或登录Cloudflare平台(CF老手可跳过)
1️⃣ 进入Cloudflare平台官网:
。www.cloudflare.com/zh-cn/
登录或者注册账号。
2️⃣ 新注册的用户会让你选择域名,无视即可,直接点下面的Start building。
3️⃣ 进入仪表盘后,界面可能会显示英文,在右上角切换到[简体中文]即可。
🚀 二、正式开始部署Deepseek API项目。
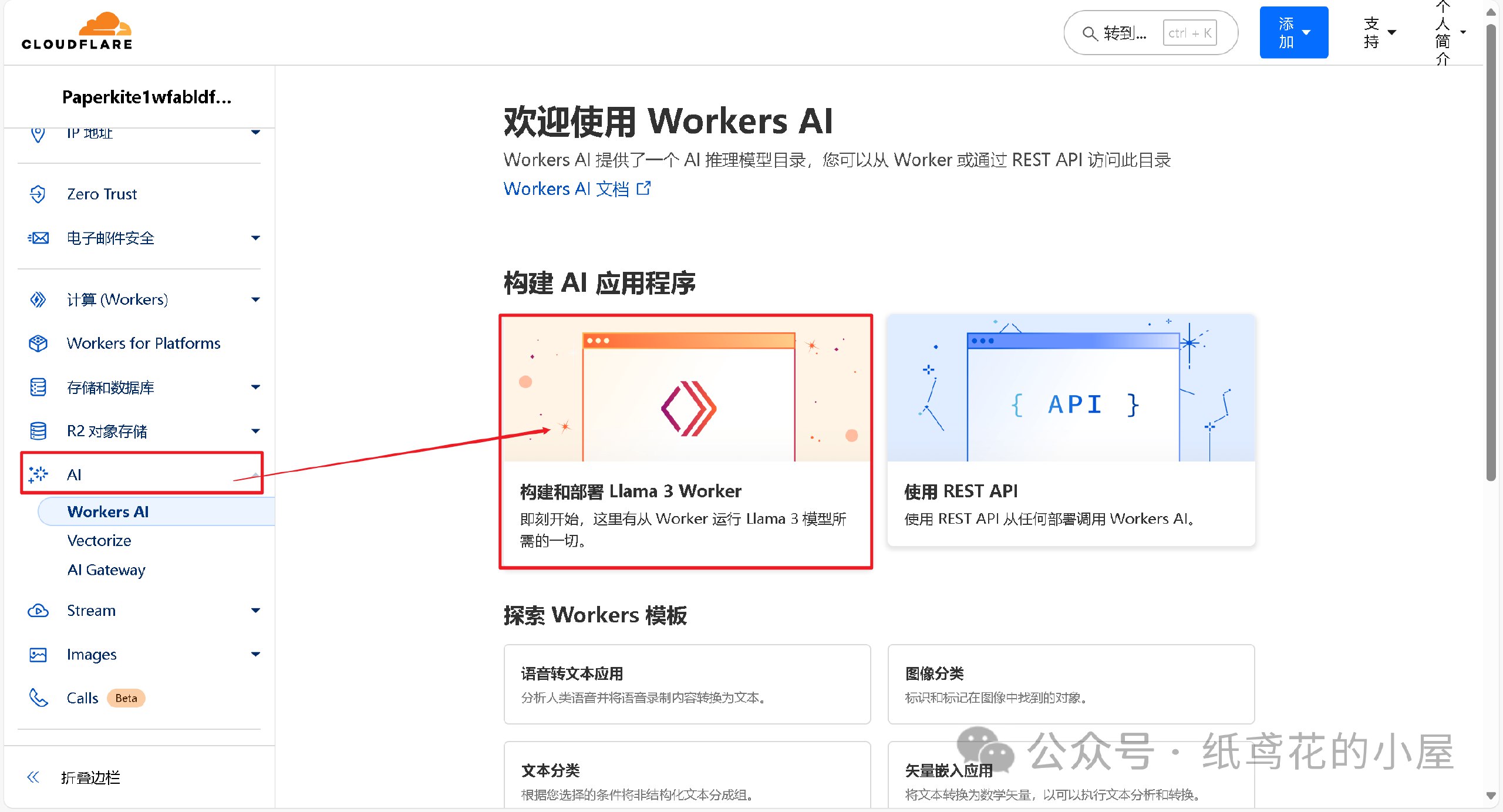
1️⃣ 首先在左侧菜单栏找到【AI】下的【Wokers AI】,选择【Llama 3 Woker】。
2️⃣ 为项目取一个好听的名字,后点击部署即可。
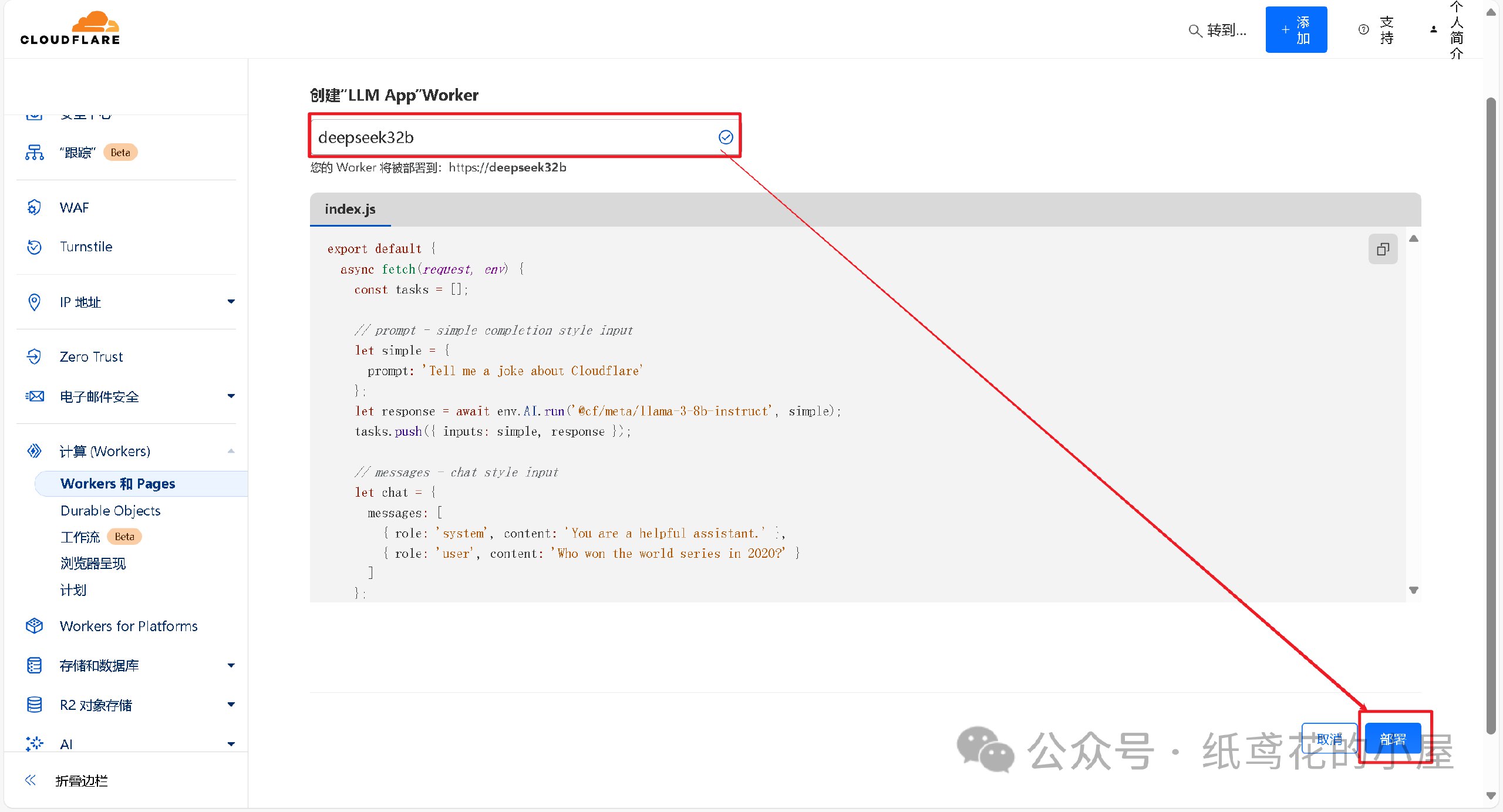
3️⃣ Woker项目初始化部署好后,需要编辑替换掉其原代码。
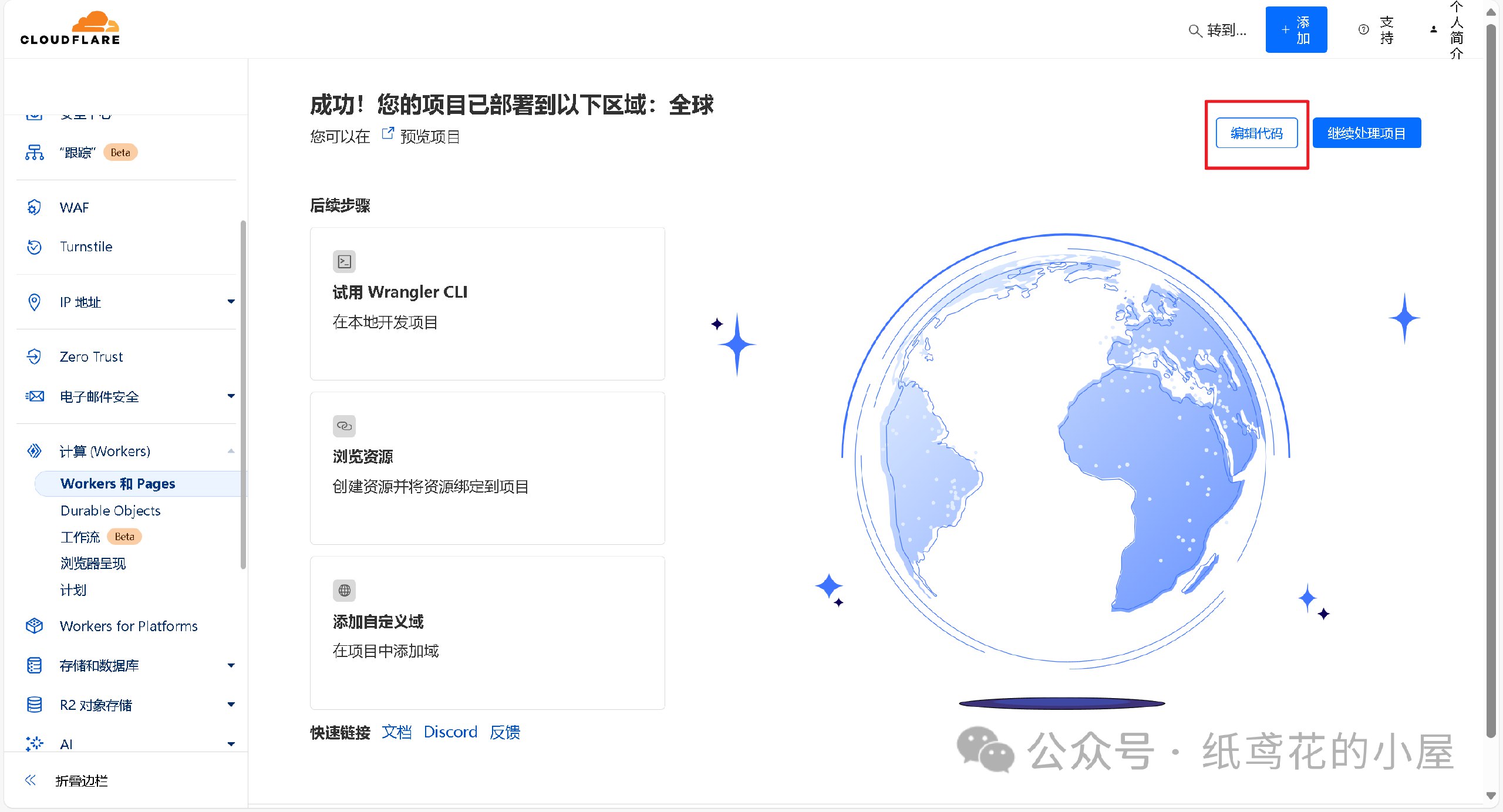
4️⃣ 解压出提供的代码压缩包,找到【32b】的部署代码,将里面的文本复制出来。
5️⃣ 接第3步,将项目里的原代码清空,粘贴第4步复制好的代码到编辑器。
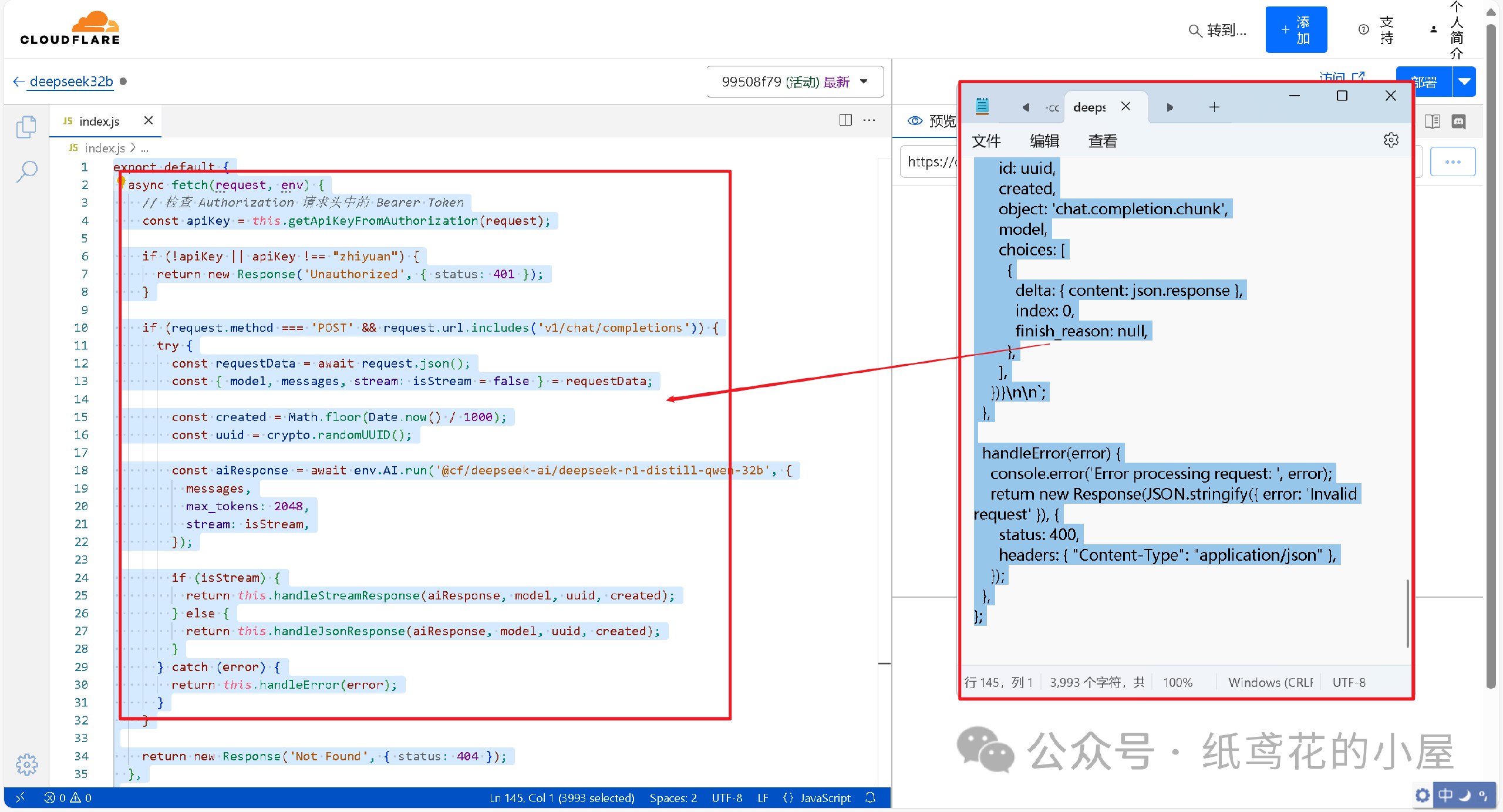
6️⃣ 代码粘贴完,即可点击右上角的部署按钮。
7️⃣ 回到仪表盘,点击部署完的项目名称。
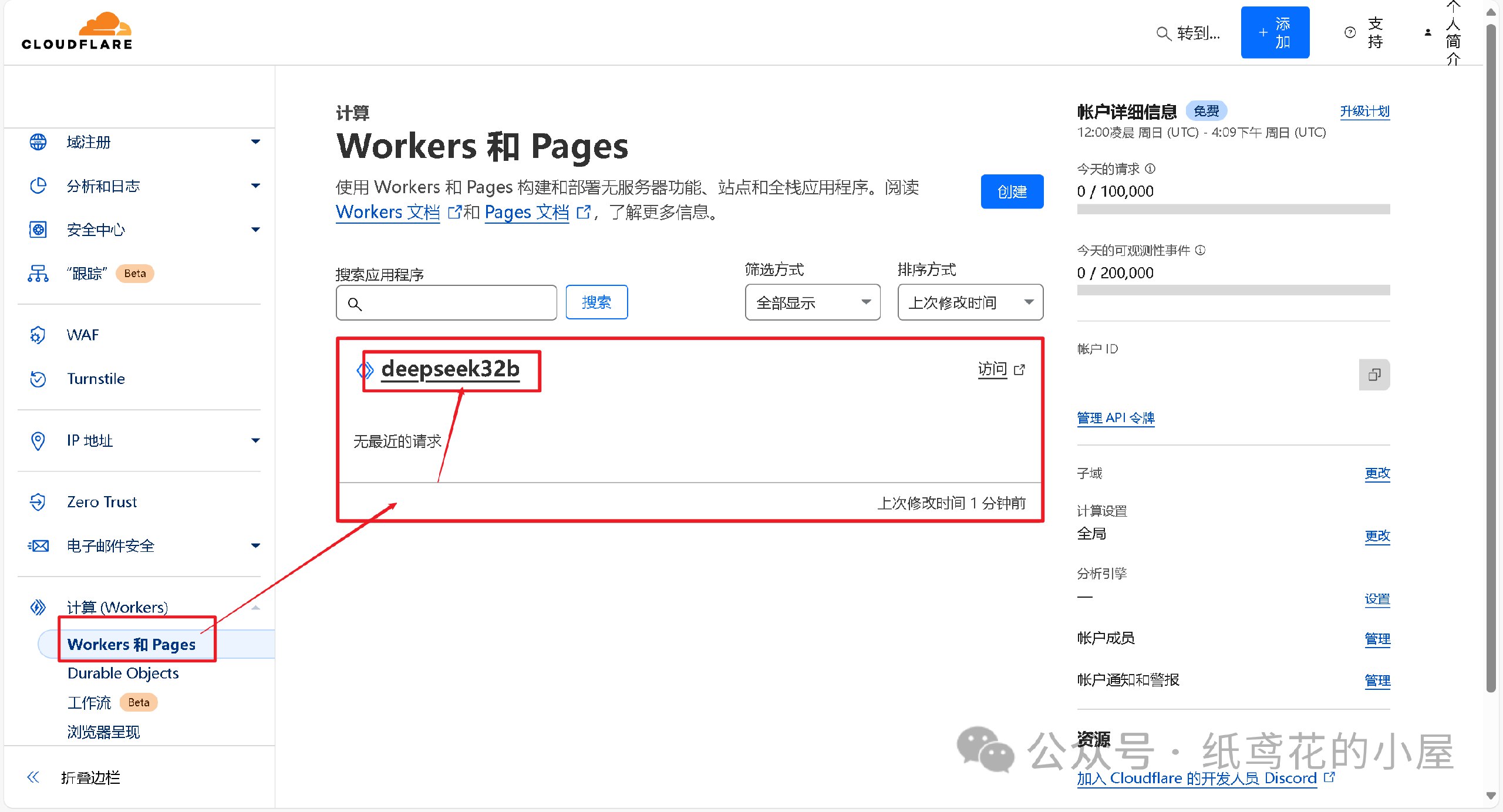
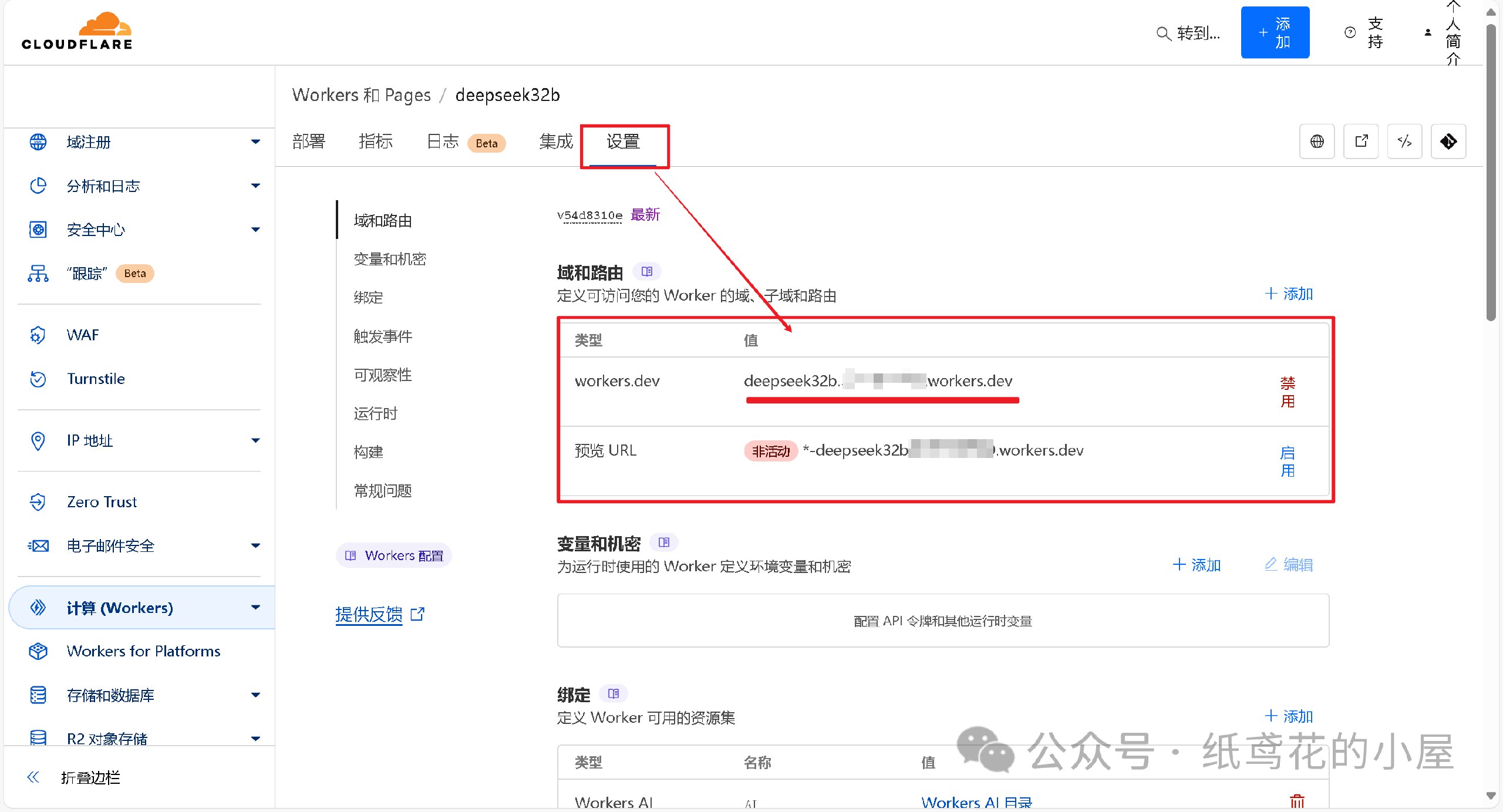
8️⃣ 查看【设置】,找到平台分配的项目网址,复制好备用。
💻 三、选择可用的UI软件,这边使用Chatbox AI演示。
1️⃣ 根据自己使用的平台下载对应的安装包,博主也一并打包好了全平台的软件安装包。
2️⃣ 打开安装好的Chatbox,点击左下角的设置。
3️⃣ 选择【添加自定义提供方】。
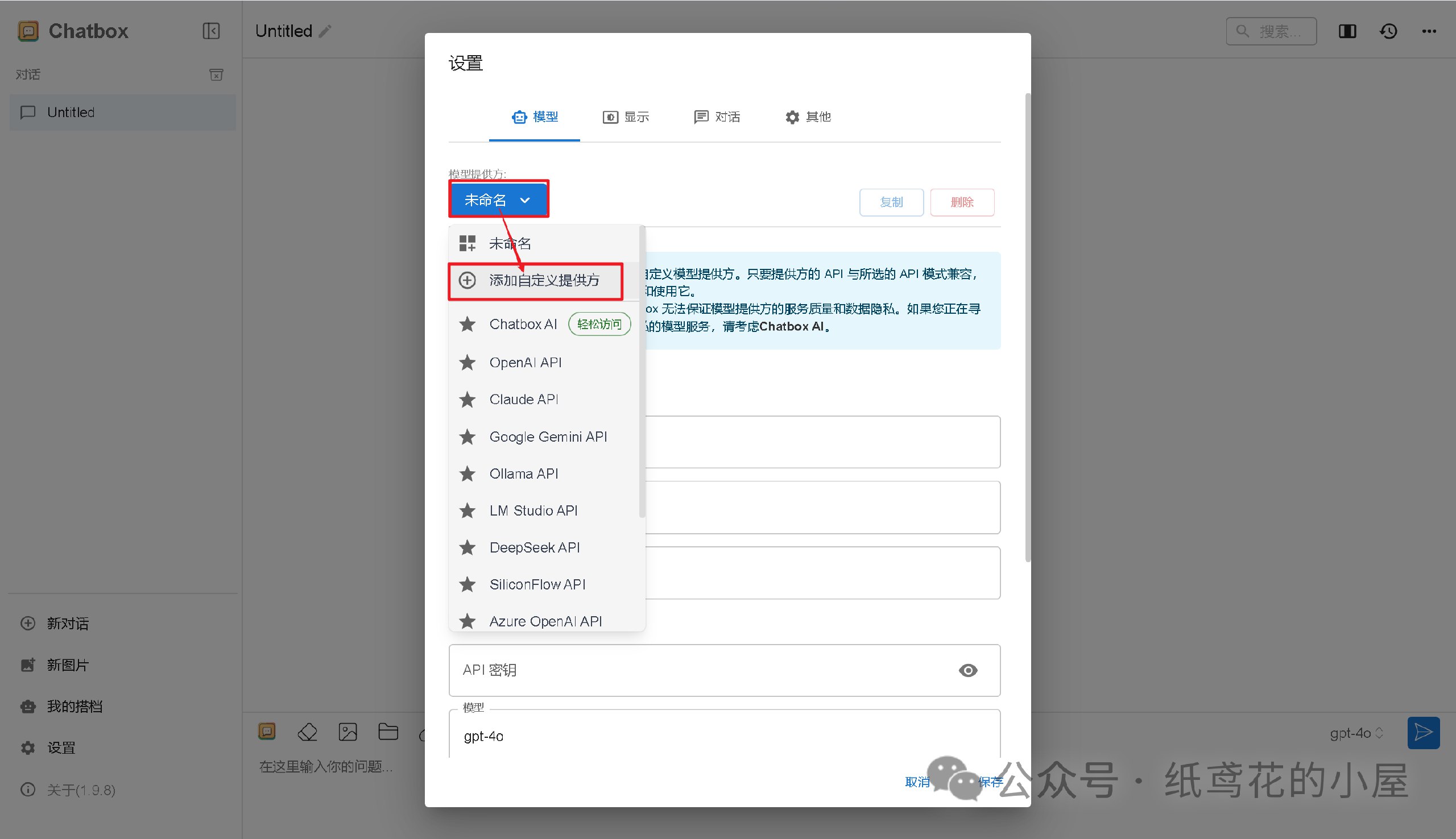
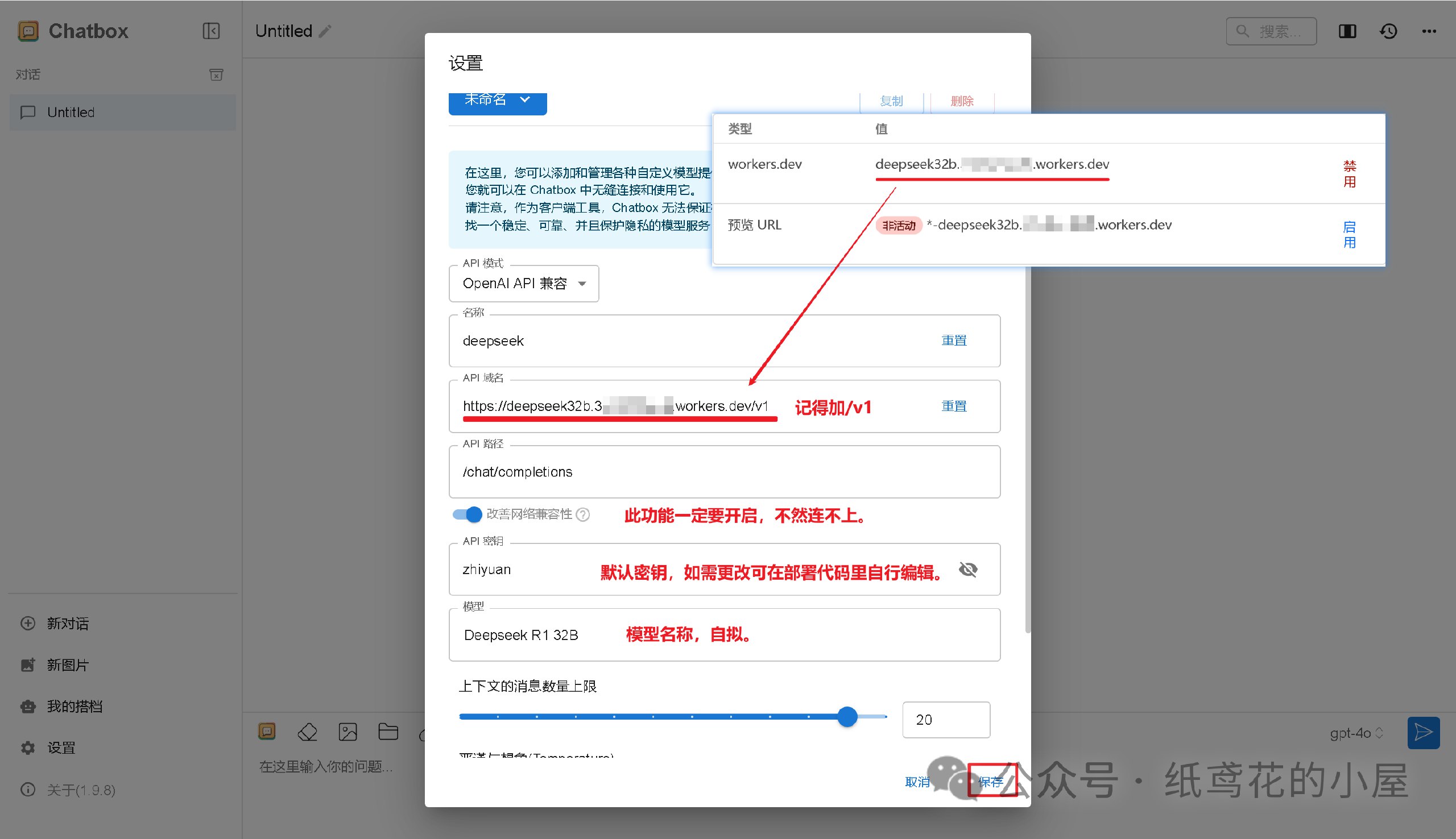
4️⃣ 按照图片说明填写即可,【API域名】为之前复制的项目网址(加/v1);【改善网络兼容性】功能务必开启;【API密钥】默认为”zhiyuan“,可自行修改;填写完毕后保存即可。
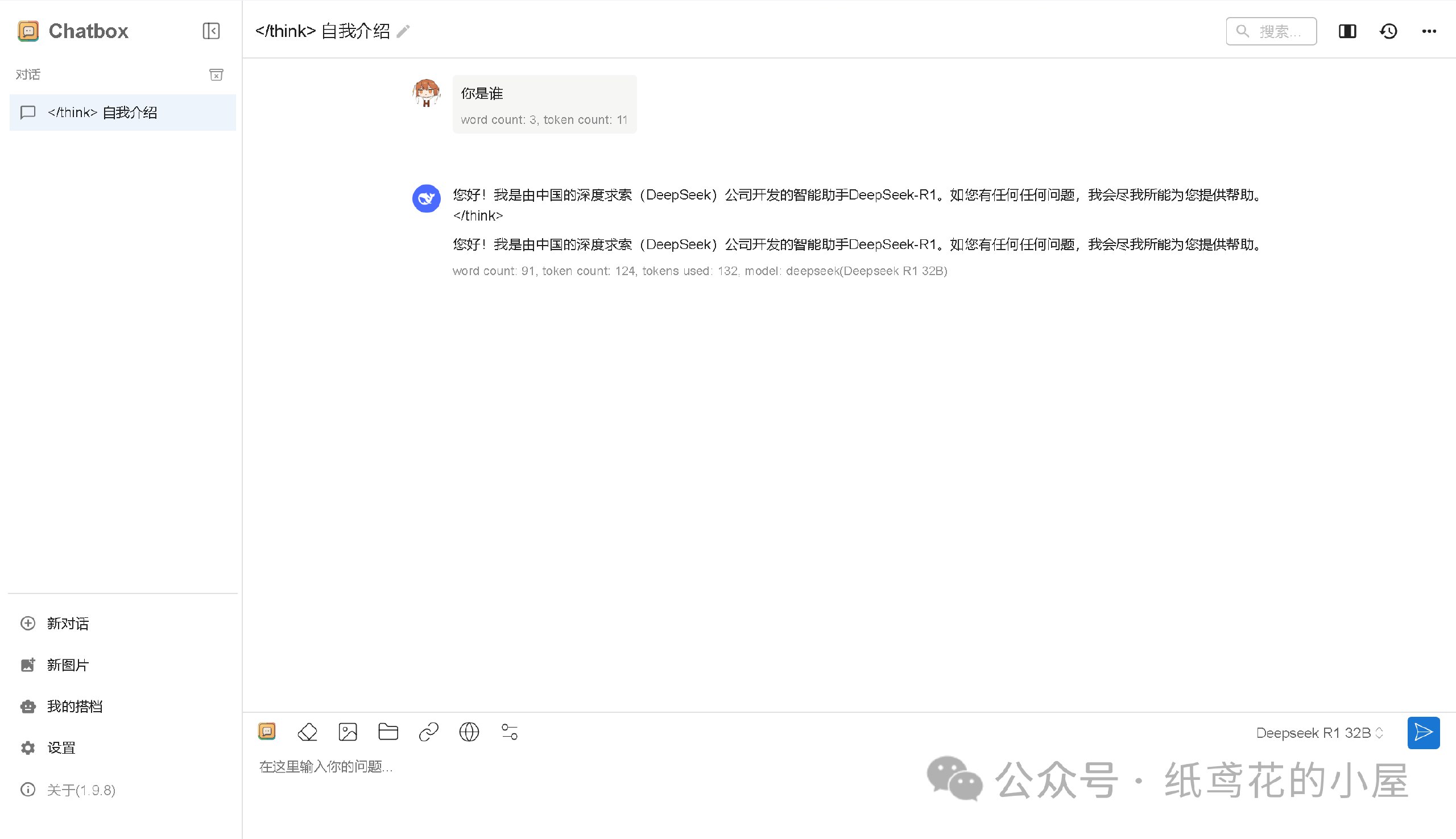
5️⃣ Cloudflare项目部署好后,就能正常使用了,接口仿照OpenAI API具有较强的兼容性,能导入到很多支持AI功能的软件或插件中。
6️⃣ Cloudflare的域名默认被墙了,需要自己准备一个域名设置。
转自微信公众号:纸鸢花的小屋
推广:低调云(梯子VPN)
。www.didiaocloud.xyz -
@ a296b972:e5a7a2e8
2025-05-05 22:45:01
Zur Gründung der Bundesrepublik Deutschland wurde infolge der Auswirkungen des 2. Weltkriegs auf einem Teil des ehemaligen Deutschen Reiches (nicht des 3. Reiches!) auf Initiative der westlichen Alliierten, federführend die USA als stärkste Kraft, eine demokratische Grundordnung erarbeitet, die wir als das Grundgesetz für die Bundesrepublik Deutschland kennen und schätzen gelernt haben. Da man zum damaligen Zeitpunkt, im Gegensatz zu heute, noch sehr genau mit der Sprache war, hat das Wort „für“ größere Bedeutung, als ihm heute zugesprochen wird. Hätte der unter westlich-alliierter Besatzung stehende Rumpf des Deutschen Reiches eigenständig eine Verfassung erstellen können, wäre es nicht Grundgesetz (das laut Definition einen provisorischen Charakter hat) genannt worden, sondern eben Verfassung. Und hätte diese Verfassung eigenständig erarbeitet werden können, hätte sie geheißen: Verfassung der Bundesrepublik Deutschland.
Es heißt zum Beispiel auch: Costituzione della Repubblica Italiana. also Konstitution der Republik Italien, und nicht Costituzione per La Repubblica Italiana.
Es ist nachvollziehbar, dass die Bedenken der westlichen Alliierten aufgrund der Nazi-Zeit so groß waren, dass man den „Deutschen“ nicht zutraute, selbständig eine Verfassung zu erstellen.
Zum vorbeugenden Schutz, es sollte verunmöglicht werden, dass ein Regime noch einmal in der Lage sei, die Macht zu ergreifen, wurde als Kontrollinstanz der Verfassungsschutz gegründet. Dieser ist dem Innenministerium gegenüber weisungsgebunden. Die jüngste Aussage, auf den letzten Metern der Innenministerin Faeser, der Verfassungsschutz sei selbständig, ist eine manipulative Beschreibung, die davon ablenken soll, dass das Innenministerium dem Verfassungsschutz sehr wohl übergeordnet ist. Das Wort „selbständig“ soll Eigenständigkeit vorgaukeln, hat aber in der Hierarchie keinerlei Bedeutung.
Im Jahre 1949 herrschte ein anderer Zeitgeist. Werte wie Ehrlichkeit, Redlichkeit und Anständigkeit hatten noch eine andere Bedeutung als heute. Politiker waren noch von einem anderen Schlag und hatten weitgehend den Anspruch zum Wohle des Volkes zu entscheiden und zu handeln. Diese Werte reichten noch mindestens bis in das Agieren des Bundeskanzlers Helmut Schmidt hinein.
Niemand konnte sich deshalb zum damaligen Zeitpunkt vorstellen, dass dieser eigentlich als Kontrollinstanz gedachte Verfassungsschutz einmal von der Politik missbraucht werden könnte, um oppositionelle Kräfte auszuschalten zu versuchen, wie es mit der Einstufung der AfD als gesichert rechtsextrem geschehen ist. Rechtlich hat das noch keine Konsequenzen, aber es geht in erster Linie darum, dem Image der AfD zu schaden, um weiteren Zulauf zu verhindern. Diese Art von Durchtriebenheit kam in den Gedanken und dem Ehrgefühl der damals verantwortlichen Politiker noch nicht vor.
Die ehemaligen Volksparteien, man kann auch sagen, die Alt-Parteien, sehen ihre Felle schon seit einiger Zeit davonschwimmen. Die Opposition hat derzeit die Zustimmung einer ehemaligen Volkspartei überholt und ist sogar stärkste Kraft geworden. Sie repräsentiert aktuell rund 10 Millionen der Wähler. Tendenz steigend. Und das die folglich auch gesichert rechtsextrem gewählt haben, oder gar gesichert rechtsextrem sind, wird ihnen vielleicht nicht besonders schmeicheln.
Parallel dazu haben die Alt-Parteien die Medienlandschaft gekapert und versuchen mit Einschränkungen der Meinungsfreiheit, sofern sich Kritik gegen sie richtet und durch selbstermächtigte Entscheidung über das, was Wahrheit und Lüge ist, unliebsame Stimmen mundtot zu machen, um unter allen Umständen an der Macht zu bleiben.
Diese Vorgehensweise widerspricht dem demokratischen Verständnis, das aus dem, wenn auch „nur“ Grundgesetz, statt Verfassung, hervorgeht und die Nachkriegsgenerationen im besten Sinne beeinflusst und demokratisch geprägt hat.
Aus dieser Sicht können die Aktivitäten der Alt-Parteien nur als Angriff auf die Demokratie, wie sie diese Generationen verstehen, gesehen werden.
Daher führt jeder Angriff der Alt-Parteien auf die Demokratie dazu, dass die Opposition immer mehr an Stimmen gewinnt und wohl weiterhin gewinnen wird.
Es erschließt sich nicht, warum die Alt-Parteien nicht auf die denkbar einfachste Lösung kommen, Vertrauen in ihre Politik zurückzugewinnen, in dem sie eine Politik machen würden, die dem Willen der Bürger entspricht. Mit dem Gegenteil machen sich die Volksvertreter zu Vertretern ohne den Rückhalt vom Volk, und man muss sich fragen, wessen Interessen sie derzeit wirklich vertreten. Bestenfalls die eigenen, schlimmstenfalls die des global agierenden Tiefen Staates, der ihnen ins Ohr flüstert, was sie zu tun haben.
Mit jeder vernunftbegabten Entscheidung, die dem Willen des Souveräns entspräche, würden sie die Opposition zunehmend schwächen. Da dies nicht geschieht, kann man nur zu der Schlussfolgerung kommen, dass sich hier auch selbstzerstörerische, suizidale Kräfte festgesetzt haben. Es ist wie eine Sucht, von der man nicht mehr loslassen kann.
Solange die Alt-Parteien nicht in der Lage sind, die Unzufriedenheit in der Bevölkerung wahr- und ernst zu nehmen, werden sie die Opposition stärken und zu immer rigideren Maßnahmen greifen müssen, um ihre Macht zu erhalten und sich damit immer mehr von demokratischen Verhältnissen entfernen, und zwar genau in die Richtung vor der die Alt-Parteien in ihrer ideologischen Verirrung warnen.
Seitens der Opposition gibt es in der Gesamtschau keine Anzeichen dafür, dass die Demokratie abgeschafft werden soll, im Gegenteil, es wird für mehr Bürgerbeteiligung plädiert, was ein sicheres Merkmal für demokratische Absichten ist.
Aus Sicht der Alt-Parteien macht die Brandmauer Sinn, weil sie sie vor ihrem eigenen Machtverlust schützt. Der Fall der Berliner Mauer sollte ihnen eigentlich eine Warnung sein.
Fairerweise darf nicht unterschlagen werden, dass es in der Opposition einige Verirrte gibt, wobei noch interessant wäre zu erfahren, welche davon als V-Männer des Verfassungsschutzes eingeschleust wurden. Diese jedoch zum Anlass zu nehmen, die Opposition unter Generalverdacht zu stellen, steht einem demokratischen Handeln diametral entgegen.
Das Grundgesetz wird so nicht geschützt, sondern bis kurz vor der Sollbruchstelle verbogen.
Die Einstufung der Opposition als gesichert rechts-extrem beruht auf einem mutmaßlich 1000 Seiten starken Papier, das offensichtlich nur ein erlesener Kreis zu sehen bekommen soll. Dazu gehört nicht die Bevölkerung, die sicher nur einmal mehr nicht zu Teilen verunsichert werden soll. Und selbstverständlich schon gar nicht diejenigen, die es betrifft, nämlich die Opposition.
Eine eindeutige Fragwürdigkeit der Aktivitäten des Verfassungsschutzes wäre schwerer festzustellen, wenn es gleichwohl Parteien gäbe, die als gesichert links-extrem oder zumindest als links-extremer Verdachtsfall eingestuft würden. Nicht ganz unberechtigte Gründe hierfür könnten schon gefunden werden, wenn der politische Wille es wollte.
Auch die seltsam-umstrittene Installierung des Präsidenten des Bundesamtes für Verfassungsschutz (genau genommen für Grundgesetzschutz) lässt Fragen offen.
Generell müsste es eine unabhängige Überprüfung geben, ob die Gewaltenteilung in Deutschland noch gewährleistet ist, da es durch das augenscheinliche Zusammenspiel in der Richterschaft, der Gesetzgebung und der vierten Gewalt, den Medien, Anlass zu Zweifel gibt.
Diese Zweifel sind nicht demokratiegefährdend, sondern im Gegenteil, es ist demokratische Pflicht, den Verantwortlichen kritisch auf die Finger zu schauen, ob im Sinne des Souveräns entschieden und gehandelt wird. Zweifel könnte man dadurch ausräumen, in dem eindeutig bewiesen würde, das alles seine Richtigkeit hat.
Das wäre vornehmlich die Aufgabe der Alt-Medien, die derzeit durch Totalversagen glänzen, weil alles mit allem zusammenhängt, jeder jeden kennt und man es sich über Jahre so eingerichtet hat, dass man gerne unter sich bleibt und Pöstchen-Hüpfen von einem Lager ins andere spielt.
Vielleicht ist es sogar nötig, dass zur unabhängigen Überprüfung, die Alliierten, inklusive Russland, noch einmal, nach rund 80 Jahren, auf den Plan gerufen werden müssen, um sozusagen eine Zwischenbilanz zu ziehen, inwieweit sich das einst etablierte, demokratische System bewährt hat, und ob es derzeit noch im ursprünglichen Sinne umgesetzt und gelebt wird. Es ist anzunehmen, dass hier ein gewaltiges Optimierungspotenzial zum Vorschein kommen könnte.
Viele Bürger in Deutschland haben den Wunsch, wieder in einer Demokratie zu leben, die ihre Namen auch verdient hat. Sie wollen wieder frei ihre Meinung jeglicher Art aussprechen können, miteinander diskutieren, auch einmal Unsinn reden, ohne, dass sie der Blockwart gleich bei einem Denunzierungsportal anschwärzt, oder sie Gefahr laufen, dass ihr Konto gekündigt wird, oder sie morgens um 6 Uhr Besuch bekommen, der noch nicht einmal frische Semmeln mitbringt.
Dieser Artikel wurde mit dem Pareto-Client geschrieben
* *
(Bild von pixabay)
-
@ daa41bed:88f54153
2025-02-09 16:50:04
There has been a good bit of discussion on Nostr over the past few days about the merits of zaps as a method of engaging with notes, so after writing a rather lengthy article on the pros of a strategic Bitcoin reserve, I wanted to take some time to chime in on the much more fun topic of digital engagement.
Let's begin by defining a couple of things:
Nostr is a decentralized, censorship-resistance protocol whose current biggest use case is social media (think Twitter/X). Instead of relying on company servers, it relies on relays that anyone can spin up and own their own content. Its use cases are much bigger, though, and this article is hosted on my own relay, using my own Nostr relay as an example.
Zap is a tip or donation denominated in sats (small units of Bitcoin) sent from one user to another. This is generally done directly over the Lightning Network but is increasingly using Cashu tokens. For the sake of this discussion, how you transmit/receive zaps will be irrelevant, so don't worry if you don't know what Lightning or Cashu are.
If we look at how users engage with posts and follows/followers on platforms like Twitter, Facebook, etc., it becomes evident that traditional social media thrives on engagement farming. The more outrageous a post, the more likely it will get a reaction. We see a version of this on more visual social platforms like YouTube and TikTok that use carefully crafted thumbnail images to grab the user's attention to click the video. If you'd like to dive deep into the psychology and science behind social media engagement, let me know, and I'd be happy to follow up with another article.
In this user engagement model, a user is given the option to comment or like the original post, or share it among their followers to increase its signal. They receive no value from engaging with the content aside from the dopamine hit of the original experience or having their comment liked back by whatever influencer they provide value to. Ad revenue flows to the content creator. Clout flows to the content creator. Sales revenue from merch and content placement flows to the content creator. We call this a linear economy -- the idea that resources get created, used up, then thrown away. Users create content and farm as much engagement as possible, then the content is forgotten within a few hours as they move on to the next piece of content to be farmed.
What if there were a simple way to give value back to those who engage with your content? By implementing some value-for-value model -- a circular economy. Enter zaps.

Unlike traditional social media platforms, Nostr does not actively use algorithms to determine what content is popular, nor does it push content created for active user engagement to the top of a user's timeline. Yes, there are "trending" and "most zapped" timelines that users can choose to use as their default, but these use relatively straightforward engagement metrics to rank posts for these timelines.
That is not to say that we may not see clients actively seeking to refine timeline algorithms for specific metrics. Still, the beauty of having an open protocol with media that is controlled solely by its users is that users who begin to see their timeline gamed towards specific algorithms can choose to move to another client, and for those who are more tech-savvy, they can opt to run their own relays or create their own clients with personalized algorithms and web of trust scoring systems.
Zaps enable the means to create a new type of social media economy in which creators can earn for creating content and users can earn by actively engaging with it. Like and reposting content is relatively frictionless and costs nothing but a simple button tap. Zaps provide active engagement because they signal to your followers and those of the content creator that this post has genuine value, quite literally in the form of money—sats.

I have seen some comments on Nostr claiming that removing likes and reactions is for wealthy people who can afford to send zaps and that the majority of people in the US and around the world do not have the time or money to zap because they have better things to spend their money like feeding their families and paying their bills. While at face value, these may seem like valid arguments, they, unfortunately, represent the brainwashed, defeatist attitude that our current economic (and, by extension, social media) systems aim to instill in all of us to continue extracting value from our lives.
Imagine now, if those people dedicating their own time (time = money) to mine pity points on social media would instead spend that time with genuine value creation by posting content that is meaningful to cultural discussions. Imagine if, instead of complaining that their posts get no zaps and going on a tirade about how much of a victim they are, they would empower themselves to take control of their content and give value back to the world; where would that leave us? How much value could be created on a nascent platform such as Nostr, and how quickly could it overtake other platforms?
Other users argue about user experience and that additional friction (i.e., zaps) leads to lower engagement, as proven by decades of studies on user interaction. While the added friction may turn some users away, does that necessarily provide less value? I argue quite the opposite. You haven't made a few sats from zaps with your content? Can't afford to send some sats to a wallet for zapping? How about using the most excellent available resource and spending 10 seconds of your time to leave a comment? Likes and reactions are valueless transactions. Social media's real value derives from providing monetary compensation and actively engaging in a conversation with posts you find interesting or thought-provoking. Remember when humans thrived on conversation and discussion for entertainment instead of simply being an onlooker of someone else's life?
If you've made it this far, my only request is this: try only zapping and commenting as a method of engagement for two weeks. Sure, you may end up liking a post here and there, but be more mindful of how you interact with the world and break yourself from blind instinct. You'll thank me later.

-
@ 127d3bf5:466f416f
2025-02-09 03:31:22
I can see why someone would think that buying some other crypto is a reasonable idea for "diversification" or even just for a bit of fun gambling, but it is not.
There are many reasons you should stick to Bitcoin only, and these have been proven correct every cycle. I've outlined these before but will cut and paste below as a summary.
The number one reason, is healthy ethical practice:
- The whole point of Bitcoin is to escape the trappings and flaws of traditional systems. Currency trading and speculative investing is a Tradfi concept, and you will end up back where you started. Sooner or later this becomes obvious to everyone. Bitcoin is the healthy and ethical choice for yourself and everyone else.
But...even if you want to be greedy, hold your horses:
- There is significant risk in wallets, defi, and cefi exchanges. Many have lost all their funds in these through hacks and services getting banned or going bankrupt.
- You get killed in exchange fees even when buying low and selling high. This is effectively a transaction tax which is often hidden (sometimes they don't show the fee, just mark up the exchange rate). Also true on defi exchanges.
- You are up against traders and founders with insider knowledge and much more sophisticated prediction models that will fleece you eventually. You cannot time the market better than they can, and it is their full-time to job to beat you and suck as much liquidity out of you as they can. House always wins.
- Every crypto trade is a taxable event, so you will be taxed on all gains anyway in most countries. So not only are the traders fleecing you, the govt is too.
- It ruins your quality of life constantly checking prices and stressing about making the wrong trade.
The best option, by far, is to slowly DCA into Bitcoin and take this off exchanges into your own custody. In the long run this strategy works out better financially, ethically, and from a quality-of-life perspective. Saving, not trading.
I've been here since 2014 and can personally attest to this.

-
@ ec42c765:328c0600
2025-02-05 23:38:12
カスタム絵文字とは
任意のオリジナル画像を絵文字のように文中に挿入できる機能です。
また、リアクション(Twitterの いいね のような機能)にもカスタム絵文字を使えます。

カスタム絵文字の対応状況(2025/02/06)

カスタム絵文字を使うためにはカスタム絵文字に対応したクライアントを使う必要があります。
※表は一例です。クライアントは他にもたくさんあります。
使っているクライアントが対応していない場合は、クライアントを変更する、対応するまで待つ、開発者に要望を送る(または自分で実装する)などしましょう。
対応クライアント
ここではnostterを使って説明していきます。
準備
カスタム絵文字を使うための準備です。
- Nostrエクステンション(NIP-07)を導入する
- 使いたいカスタム絵文字をリストに登録する
Nostrエクステンション(NIP-07)を導入する
Nostrエクステンションは使いたいカスタム絵文字を登録する時に必要になります。
また、環境(パソコン、iPhone、androidなど)によって導入方法が違います。
Nostrエクステンションを導入する端末は、実際にNostrを閲覧する端末と違っても構いません(リスト登録はPC、Nostr閲覧はiPhoneなど)。
Nostrエクステンション(NIP-07)の導入方法は以下のページを参照してください。
ログイン拡張機能 (NIP-07)を使ってみよう | Welcome to Nostr! ~ Nostrをはじめよう! ~
少し面倒ですが、これを導入しておくとNostr上の様々な場面で役立つのでより快適になります。
使いたいカスタム絵文字をリストに登録する
以下のサイトで行います。
右上のGet startedからNostrエクステンションでログインしてください。
例として以下のカスタム絵文字を導入してみます。
実際より絵文字が少なく表示されることがありますが、古い状態のデータを取得してしまっているためです。その場合はブラウザの更新ボタンを押してください。

- 右側のOptionsからBookmarkを選択

これでカスタム絵文字を使用するためのリストに登録できます。
カスタム絵文字を使用する
例としてブラウザから使えるクライアント nostter から使用してみます。
nostterにNostrエクステンションでログイン、もしくは秘密鍵を入れてログインしてください。
文章中に使用
- 投稿ボタンを押して投稿ウィンドウを表示
- 顔😀のボタンを押し、絵文字ウィンドウを表示
- *タブを押し、カスタム絵文字一覧を表示
- カスタム絵文字を選択
- : 記号に挟まれたアルファベットのショートコードとして挿入される

この状態で投稿するとカスタム絵文字として表示されます。
カスタム絵文字対応クライアントを使っている他ユーザーにもカスタム絵文字として表示されます。
対応していないクライアントの場合、ショートコードのまま表示されます。

ショートコードを直接入力することでカスタム絵文字の候補が表示されるのでそこから選択することもできます。

リアクションに使用
- 任意の投稿の顔😀のボタンを押し、絵文字ウィンドウを表示
- *タブを押し、カスタム絵文字一覧を表示
- カスタム絵文字を選択

カスタム絵文字リアクションを送ることができます。

カスタム絵文字を探す
先述したemojitoからカスタム絵文字を探せます。
例えば任意のユーザーのページ emojito ロクヨウ から探したり、 emojito Browse all からnostr全体で最近作成、更新された絵文字を見たりできます。
また、以下のリンクは日本語圏ユーザーが作ったカスタム絵文字を集めたリストです(2025/02/06)
※漏れがあるかもしれません
各絵文字セットにあるOpen in emojitoのリンクからemojitoに飛び、使用リストに追加できます。
以上です。
次:Nostrのカスタム絵文字の作り方
Yakihonneリンク Nostrのカスタム絵文字の作り方
Nostrリンク nostr:naddr1qqxnzdesxuunzv358ycrgveeqgswcsk8v4qck0deepdtluag3a9rh0jh2d0wh0w9g53qg8a9x2xqvqqrqsqqqa28r5psx3
仕様
-
@ b7274d28:c99628cb
2025-02-04 05:31:13
For anyone interested in the list of essential essays from nostr:npub14hn6p34vegy4ckeklz8jq93mendym9asw8z2ej87x2wuwf8werasc6a32x (@anilsaidso) on Twitter that nostr:npub1h8nk2346qezka5cpm8jjh3yl5j88pf4ly2ptu7s6uu55wcfqy0wq36rpev mentioned on Read 856, here it is. I have compiled it with as many of the essays as I could find, along with the audio versions, when available. Additionally, if the author is on #Nostr, I have tagged their npub so you can thank them by zapping them some sats.
All credit for this list and the graphics accompanying each entry goes to nostr:npub14hn6p34vegy4ckeklz8jq93mendym9asw8z2ej87x2wuwf8werasc6a32x, whose original thread can be found here: Anil's Essential Essays Thread
1.

History shows us that the corruption of monetary systems leads to moral decay, social collapse, and slavery.
Essay: https://breedlove22.medium.com/masters-and-slaves-of-money-255ecc93404f
Audio: https://fountain.fm/episode/RI0iCGRCCYdhnMXIN3L6
2.

The 21st century emergence of Bitcoin, encryption, the internet, and millennials are more than just trends; they herald a wave of change that exhibits similar dynamics as the 16-17th century revolution that took place in Europe.
Author: nostr:npub13l3lyslfzyscrqg8saw4r09y70702s6r025hz52sajqrvdvf88zskh8xc2
Essay: https://casebitcoin.com/docs/TheBitcoinReformation_TuurDemeester.pdf
Audio: https://fountain.fm/episode/uLgBG2tyCLMlOp3g50EL
3.

There are many men out there who will parrot the "debt is money WE owe OURSELVES" without acknowledging that "WE" isn't a static entity, but a collection of individuals at different points in their lives.
Author: nostr:npub1guh5grefa7vkay4ps6udxg8lrqxg2kgr3qh9n4gduxut64nfxq0q9y6hjy
Essay: https://www.tftc.io/issue-754-ludwig-von-mises-human-action/
Audio: https://fountain.fm/episode/UXacM2rkdcyjG9xp9O2l
4.
If Bitcoin exists for 20 years, there will be near-universal confidence that it will be available forever, much as people believe the Internet is a permanent feature of the modern world.
Essay: https://vijayboyapati.medium.com/the-bullish-case-for-bitcoin-6ecc8bdecc1
Audio: https://fountain.fm/episode/jC3KbxTkXVzXO4vR7X3W
As you are surely aware, Vijay has expanded this into a book available here: The Bullish Case for Bitcoin Book
There is also an audio book version available here: The Bullish Case for Bitcoin Audio Book
5.

This realignment would not be traditional right vs left, but rather land vs cloud, state vs network, centralized vs decentralized, new money vs old, internationalist/capitalist vs nationalist/socialist, MMT vs BTC,...Hamilton vs Satoshi.
Essay: https://nakamoto.com/bitcoin-becomes-the-flag-of-technology/
Audio: https://fountain.fm/episode/tFJKjYLKhiFY8voDssZc
6.
I became convinced that, whether bitcoin survives or not, the existing financial system is working on borrowed time.
Essay: https://nakamotoinstitute.org/mempool/gradually-then-suddenly/
Audio: https://fountain.fm/episode/Mf6hgTFUNESqvdxEIOGZ
Parker Lewis went on to release several more articles in the Gradually, Then Suddenly series. They can be found here: Gradually, Then Suddenly Series
nostr:npub1h8nk2346qezka5cpm8jjh3yl5j88pf4ly2ptu7s6uu55wcfqy0wq36rpev has, of course, read all of them for us. Listing them all here is beyond the scope of this article, but you can find them by searching the podcast feed here: Bitcoin Audible Feed
Finally, Parker Lewis has refined these articles and released them as a book, which is available here: Gradually, Then Suddenly Book
7.

Bitcoin is a beautifully-constructed protocol. Genius is apparent in its design to most people who study it in depth, in terms of the way it blends math, computer science, cyber security, monetary economics, and game theory.
Author: nostr:npub1a2cww4kn9wqte4ry70vyfwqyqvpswksna27rtxd8vty6c74era8sdcw83a
Essay: https://www.lynalden.com/invest-in-bitcoin/
Audio: https://fountain.fm/episode/axeqKBvYCSP1s9aJIGSe
8.

Bitcoin offers a sweeping vista of opportunity to re-imagine how the financial system can and should work in the Internet era..
Essay: https://archive.nytimes.com/dealbook.nytimes.com/2014/01/21/why-bitcoin-matters/
9.

Using Bitcoin for consumer purchases is akin to driving a Concorde jet down the street to pick up groceries: a ridiculously expensive waste of an astonishing tool.
Author: nostr:npub1gdu7w6l6w65qhrdeaf6eyywepwe7v7ezqtugsrxy7hl7ypjsvxksd76nak
Essay: https://nakamotoinstitute.org/mempool/economics-of-bitcoin-as-a-settlement-network/
Audio: https://fountain.fm/episode/JoSpRFWJtoogn3lvTYlz
10.

The Internet is a dumb network, which is its defining and most valuable feature. The Internet’s protocol (..) doesn’t offer “services.” It doesn’t make decisions about content. It doesn’t distinguish between photos, text, video and audio.
Essay: https://fee.org/articles/decentralization-why-dumb-networks-are-better/
Audio: https://fountain.fm/episode/b7gOEqmWxn8RiDziffXf
11.

Most people are only familiar with (b)itcoin the electronic currency, but more important is (B)itcoin, with a capital B, the underlying protocol, which encapsulates and distributes the functions of contract law.
I was unable to find this essay or any audio version. Clicking on Anil's original link took me to Naval's blog, but that particular entry seems to have been removed.
12.

Bitcoin can approximate unofficial exchange rates which, in turn, can be used to detect both the existence and the magnitude of the distortion caused by capital controls & exchange rate manipulations.
Essay: https://papers.ssrn.com/sol3/Papers.cfm?abstract_id=2714921
13.

You can create something which looks cosmetically similar to Bitcoin, but you cannot replicate the settlement assurances which derive from the costliness of the ledger.
Essay: https://medium.com/@nic__carter/its-the-settlement-assurances-stupid-5dcd1c3f4e41
Audio: https://fountain.fm/episode/5NoPoiRU4NtF2YQN5QI1
14.

When we can secure the most important functionality of a financial network by computer science... we go from a system that is manual, local, and of inconsistent security to one that is automated, global, and much more secure.
Essay: https://nakamotoinstitute.org/library/money-blockchains-and-social-scalability/
Audio: https://fountain.fm/episode/VMH9YmGVCF8c3I5zYkrc
15.

The BCB enforces the strictest deposit regulations in the world by requiring full reserves for all accounts. ..money is not destroyed when bank debts are repaid, so increased money hoarding does not cause liquidity traps..
Author: nostr:npub1hxwmegqcfgevu4vsfjex0v3wgdyz8jtlgx8ndkh46t0lphtmtsnsuf40pf
Essay: https://nakamotoinstitute.org/mempool/the-bitcoin-central-banks-perfect-monetary-policy/
Audio: https://fountain.fm/episode/ralOokFfhFfeZpYnGAsD
16.

When Satoshi announced Bitcoin on the cryptography mailing list, he got a skeptical reception at best. Cryptographers have seen too many grand schemes by clueless noobs. They tend to have a knee jerk reaction.
Essay: https://nakamotoinstitute.org/library/bitcoin-and-me/
Audio: https://fountain.fm/episode/Vx8hKhLZkkI4cq97qS4Z
17.

No matter who you are, or how big your company is, 𝙮𝙤𝙪𝙧 𝙩𝙧𝙖𝙣𝙨𝙖𝙘𝙩𝙞𝙤𝙣 𝙬𝙤𝙣’𝙩 𝙥𝙧𝙤𝙥𝙖𝙜𝙖𝙩𝙚 𝙞𝙛 𝙞𝙩’𝙨 𝙞𝙣𝙫𝙖𝙡𝙞𝙙.
Essay: https://nakamotoinstitute.org/mempool/bitcoin-miners-beware-invalid-blocks-need-not-apply/
Audio: https://fountain.fm/episode/bcSuBGmOGY2TecSov4rC
18.

Just like a company trying to protect itself from being destroyed by a new competitor, the actions and reactions of central banks and policy makers to protect the system that they know, are quite predictable.
Author: nostr:npub1s05p3ha7en49dv8429tkk07nnfa9pcwczkf5x5qrdraqshxdje9sq6eyhe
Essay: https://medium.com/the-bitcoin-times/the-greatest-game-b787ac3242b2
Audio Part 1: https://fountain.fm/episode/5bYyGRmNATKaxminlvco
Audio Part 2: https://fountain.fm/episode/92eU3h6gqbzng84zqQPZ
19.

Technology, industry, and society have advanced immeasurably since, and yet we still live by Venetian financial customs and have no idea why. Modern banking is the legacy of a problem that technology has since solved.
Author: nostr:npub1sfhflz2msx45rfzjyf5tyj0x35pv4qtq3hh4v2jf8nhrtl79cavsl2ymqt
Essay: https://allenfarrington.medium.com/bitcoin-is-venice-8414dda42070
Audio: https://fountain.fm/episode/s6Fu2VowAddRACCCIxQh
Allen Farrington and Sacha Meyers have gone on to expand this into a book, as well. You can get the book here: Bitcoin is Venice Book
And wouldn't you know it, Guy Swann has narrated the audio book available here: Bitcoin is Venice Audio Book
20.

The rich and powerful will always design systems that benefit them before everyone else. The genius of Bitcoin is to take advantage of that very base reality and force them to get involved and help run the system, instead of attacking it.
Author: nostr:npub1trr5r2nrpsk6xkjk5a7p6pfcryyt6yzsflwjmz6r7uj7lfkjxxtq78hdpu
Essay: https://quillette.com/2021/02/21/can-governments-stop-bitcoin/
Audio: https://fountain.fm/episode/jeZ21IWIlbuC1OGnssy8
21.

In the realm of information, there is no coin-stamping without time-stamping. The relentless beating of this clock is what gives rise to all the magical properties of Bitcoin.
Author: nostr:npub1dergggklka99wwrs92yz8wdjs952h2ux2ha2ed598ngwu9w7a6fsh9xzpc
Essay: https://dergigi.com/2021/01/14/bitcoin-is-time/
Audio: https://fountain.fm/episode/pTevCY2vwanNsIso6F6X
22.

You can stay on the Fiat Standard, in which some people get to produce unlimited new units of money for free, just not you. Or opt in to the Bitcoin Standard, in which no one gets to do that, including you.
Essay: https://casebitcoin.com/docs/StoneRidge_2020_Shareholder_Letter.pdf
Audio: https://fountain.fm/episode/PhBTa39qwbkwAtRnO38W
23.

Long term investors should use Bitcoin as their unit of account and every single investment should be compared to the expected returns of Bitcoin.
Essay: https://nakamotoinstitute.org/mempool/everyones-a-scammer/
Audio: https://fountain.fm/episode/vyR2GUNfXtKRK8qwznki
24.

When you’re in the ivory tower, you think the term “ivory tower” is a silly misrepresentation of your very normal life; when you’re no longer in the ivory tower, you realize how willfully out of touch you were with the world.
Essay: https://www.citadel21.com/why-the-yuppie-elite-dismiss-bitcoin
Audio: https://fountain.fm/episode/7do5K4pPNljOf2W3rR2V
You might notice that many of the above essays are available from the Satoshi Nakamoto Institute. It is a veritable treasure trove of excellent writing on subjects surrounding #Bitcoin and #AustrianEconomics. If you find value in them keeping these written works online for the next wave of new Bitcoiners to have an excellent source of education, please consider donating to the cause.
-
@ 0d97beae:c5274a14
2025-01-11 16:52:08
This article hopes to complement the article by Lyn Alden on YouTube: https://www.youtube.com/watch?v=jk_HWmmwiAs
The reason why we have broken money
Before the invention of key technologies such as the printing press and electronic communications, even such as those as early as morse code transmitters, gold had won the competition for best medium of money around the world.
In fact, it was not just gold by itself that became money, rulers and world leaders developed coins in order to help the economy grow. Gold nuggets were not as easy to transact with as coins with specific imprints and denominated sizes.
However, these modern technologies created massive efficiencies that allowed us to communicate and perform services more efficiently and much faster, yet the medium of money could not benefit from these advancements. Gold was heavy, slow and expensive to move globally, even though requesting and performing services globally did not have this limitation anymore.
Banks took initiative and created derivatives of gold: paper and electronic money; these new currencies allowed the economy to continue to grow and evolve, but it was not without its dark side. Today, no currency is denominated in gold at all, money is backed by nothing and its inherent value, the paper it is printed on, is worthless too.
Banks and governments eventually transitioned from a money derivative to a system of debt that could be co-opted and controlled for political and personal reasons. Our money today is broken and is the cause of more expensive, poorer quality goods in the economy, a larger and ever growing wealth gap, and many of the follow-on problems that have come with it.
Bitcoin overcomes the "transfer of hard money" problem
Just like gold coins were created by man, Bitcoin too is a technology created by man. Bitcoin, however is a much more profound invention, possibly more of a discovery than an invention in fact. Bitcoin has proven to be unbreakable, incorruptible and has upheld its ability to keep its units scarce, inalienable and counterfeit proof through the nature of its own design.
Since Bitcoin is a digital technology, it can be transferred across international borders almost as quickly as information itself. It therefore severely reduces the need for a derivative to be used to represent money to facilitate digital trade. This means that as the currency we use today continues to fare poorly for many people, bitcoin will continue to stand out as hard money, that just so happens to work as well, functionally, along side it.
Bitcoin will also always be available to anyone who wishes to earn it directly; even China is unable to restrict its citizens from accessing it. The dollar has traditionally become the currency for people who discover that their local currency is unsustainable. Even when the dollar has become illegal to use, it is simply used privately and unofficially. However, because bitcoin does not require you to trade it at a bank in order to use it across borders and across the web, Bitcoin will continue to be a viable escape hatch until we one day hit some critical mass where the world has simply adopted Bitcoin globally and everyone else must adopt it to survive.
Bitcoin has not yet proven that it can support the world at scale. However it can only be tested through real adoption, and just as gold coins were developed to help gold scale, tools will be developed to help overcome problems as they arise; ideally without the need for another derivative, but if necessary, hopefully with one that is more neutral and less corruptible than the derivatives used to represent gold.
Bitcoin blurs the line between commodity and technology
Bitcoin is a technology, it is a tool that requires human involvement to function, however it surprisingly does not allow for any concentration of power. Anyone can help to facilitate Bitcoin's operations, but no one can take control of its behaviour, its reach, or its prioritisation, as it operates autonomously based on a pre-determined, neutral set of rules.
At the same time, its built-in incentive mechanism ensures that people do not have to operate bitcoin out of the good of their heart. Even though the system cannot be co-opted holistically, It will not stop operating while there are people motivated to trade their time and resources to keep it running and earn from others' transaction fees. Although it requires humans to operate it, it remains both neutral and sustainable.
Never before have we developed or discovered a technology that could not be co-opted and used by one person or faction against another. Due to this nature, Bitcoin's units are often described as a commodity; they cannot be usurped or virtually cloned, and they cannot be affected by political biases.
The dangers of derivatives
A derivative is something created, designed or developed to represent another thing in order to solve a particular complication or problem. For example, paper and electronic money was once a derivative of gold.
In the case of Bitcoin, if you cannot link your units of bitcoin to an "address" that you personally hold a cryptographically secure key to, then you very likely have a derivative of bitcoin, not bitcoin itself. If you buy bitcoin on an online exchange and do not withdraw the bitcoin to a wallet that you control, then you legally own an electronic derivative of bitcoin.
Bitcoin is a new technology. It will have a learning curve and it will take time for humanity to learn how to comprehend, authenticate and take control of bitcoin collectively. Having said that, many people all over the world are already using and relying on Bitcoin natively. For many, it will require for people to find the need or a desire for a neutral money like bitcoin, and to have been burned by derivatives of it, before they start to understand the difference between the two. Eventually, it will become an essential part of what we regard as common sense.
Learn for yourself
If you wish to learn more about how to handle bitcoin and avoid derivatives, you can start by searching online for tutorials about "Bitcoin self custody".
There are many options available, some more practical for you, and some more practical for others. Don't spend too much time trying to find the perfect solution; practice and learn. You may make mistakes along the way, so be careful not to experiment with large amounts of your bitcoin as you explore new ideas and technologies along the way. This is similar to learning anything, like riding a bicycle; you are sure to fall a few times, scuff the frame, so don't buy a high performance racing bike while you're still learning to balance.
-
@ 37fe9853:bcd1b039
2025-01-11 15:04:40
yoyoaa
-
@ c9badfea:610f861a
2025-05-05 22:36:34
- Install SherpaTTS (it's free and open source)
- Launch the app and download the first AI model for your language (see recommendations below)
- Tap the + icon below the language selection to add more models
- Enjoy offline text-to-speech synthesis
Model Recommendations
- English:
en_US-ryan-medium - Chinese:
zh-CN-huayan-medium - German:
de_DE-thorsten-medium - Spanish:
es_ES-sharvard-medium - Portuguese:
pt_BR-faber-medium - French:
fr_FR-tom-medium - Dutch:
nl_BE-rdh-medium - Russian:
ru_RU-dmitri-medium - Arabic:
ar-JO-kareem-medium - Romanian:
ro_RO-mihai-medium - Bulgarian:
bg-cv - Turkish:
tr_TR-fahrettin-medium
ℹ️ An internet connection is only needed for the initial download
ℹ️ You can use TTS Util to read text and files aloud
-
@ f1989a96:bcaaf2c1
2025-05-01 15:50:38
Good morning, readers!
This week, we bring pressing news from Belarus, where the regime’s central bank is preparing to launch its central bank digital currency in close collaboration with Russia by the end of 2026. Since rigging the 2020 election, President Alexander Lukashenko has ruled through brute force and used financial repression to crush civil society and political opposition. A Central Bank Digital Currency (CBDC) in the hands of such an authoritarian leader is a recipe for greater control over all aspects of financial activity.
Meanwhile, Russia is planning to further restrict Bitcoin access for ordinary citizens. This time, the Central Bank of Russia and the Ministry of Finance announced joint plans to launch a state-regulated cryptocurrency exchange available exclusively to “super-qualified investors.” Access would be limited to those meeting previously defined thresholds of $1.2 million in assets or an annual income above $580,000. This is a blatant attempt by the Kremlin to dampen the accessibility and impact of Bitcoin for those who need it most.
In freedom tech news, we spotlight Samiz. This new tool allows users to create a Bluetooth mesh network over nostr, allowing users' messages and posts to pass through nearby devices on the network even while offline. When a post reaches someone with an Internet connection, it is broadcast across the wider network. While early in development, Mesh networks like Samiz hold the potential to disseminate information posted by activists and human rights defenders even when authoritarian regimes in countries like Pakistan, Venezuela, or Burma try to restrict communications and the Internet.
We end with a reading of our very own Financial Freedom Report #67 on the Bitcoin Audible podcast, where host Guy Swann reads the latest news on plunging currencies, CBDCs, and new Bitcoin freedom tools. We encourage our readers to give it a listen and stay tuned for future readings of HRF’s Financial Freedom Report on Bitcoin Audible. We also include an interview with HRF’s global bitcoin adoption lead, Femi Longe, who shares insights on Bitcoin’s growing role as freedom money for those who need it most.
Now, let’s see what’s in store this week!
SUBSCRIBE HERE
GLOBAL NEWS
Belarus | Launching CBDC in Late 2026
Belarus is preparing to launch its CBDC, the digital ruble, into public circulation by late 2026. Roman Golovchenko, the chairman of the National Bank of the Republic of Belarus (and former prime minister), made the regime’s intent clear: “For the state, it is very important to be able to trace how digital money moves along the entire chain.” He added that Belarus was “closely cooperating with Russia regarding the development of the CBDC.” The level of surveillance and central control that the digital ruble would embed into Belarus’s financial system would pose existential threats to what remains of civil society in the country. Since stealing the 2020 election, Belarusian President Alexander Lukashenko has ruled through sheer force, detaining over 35,000 people, labeling dissidents and journalists as “extremists,” and freezing the bank accounts of those who challenge his authority. In this context, a CBDC would not be a modern financial tool — it would be a means of instant oppression, granting the regime real-time insight into every transaction and the ability to act on it directly.
Russia | Proposes Digital Asset Exchange Exclusively for Wealthy Investors
A month after proposing a framework that would restrict the trading of Bitcoin to only the country’s wealthiest individuals (Russians with over $1.2 million in assets or an annual income above $580,000), Russia’s Ministry of Finance and Central Bank have announced plans to launch a government-regulated cryptocurrency exchange available exclusively to “super-qualified investors.” Under the plan, only citizens meeting the previously stated wealth and income thresholds (which may be subject to change) would be allowed to trade digital assets on the platform. This would further entrench financial privilege for Russian oligarchs while cutting ordinary Russians off from alternative financial tools and the financial freedom they offer. Finance Minister Anton Siluanov claims this will bring digital asset operations “out of the shadows,” but in reality, it suppresses grassroots financial autonomy while exerting state control over who can access freedom money.
Cuba | Ecash Brings Offline Bitcoin Payments to Island Nation in the Dark
As daily blackouts and internet outages continue across Cuba, a new development is helping Cubans achieve financial freedom: Cashu ecash. Cashu is an ecash protocol — a form of digital cash backed by Bitcoin that enables private, everyday payments that can also be done offline — a powerful feature for Cubans experiencing up to 20-hour daily blackouts. However, ecash users must trust mints (servers operated by individuals or groups that issue and redeem ecash tokens) not to disappear with user funds. To leverage this freedom tech to its fullest, the Cuban Bitcoin community launched its own ecash mint, mint.cubabitcoin.org. This minimizes trust requirements for Cubans to transact with ecash and increases its accessibility by running the mint locally. Cuba Bitcoin also released a dedicated ecash resource page, helping expand accessibility to freedom through financial education. For an island nation where the currency has lost more than 90% of its value, citizens remain locked out of their savings, and remittances are often hijacked by the regime, tools like ecash empower Cubans to preserve their financial privacy, exchange value freely, and resist the financial repression that has left so many impoverished.
Zambia | Introduces Cyber Law to Track and Intercept Digital Communications
Zambia’s government passed two new cyber laws granting officials sweeping powers to track and intercept digital communications while increasing surveillance over Zambians' online activity. Officials insist it will help combat cybercrime. Really, it gives the president absolute control over the direction of a new surveillance agency — a powerful tool to crush dissent. This follows earlier plans to restrict the use of foreign currency in the economy to fight inflation, which effectively trapped Zambians in a financial system centered around the volatile “kwacha” currency (which reached a record low earlier this year with inflation above 16%). For activists, journalists, and everyday Zambians, the new laws over online activity threaten the ability to organize and speak freely while potentially hampering access to freedom tech.
India | Central Bank Deputy Governor Praises CBDC Capabilities
At the Bharat Inclusion Summit in Bengaluru, India, the deputy governor of the Reserve Bank of India (RBI), Rabi Sankar, declared, “I have so far not seen any use case that potentially can solve the problem of cross-border money transfer; only CBDC has the ability to solve it.” Yet — seemingly unbeknownst to Sankar, Bitcoin has served as an effective remittance tool for more than a decade at low cost, fast speed, and with no central point of control. Sankar’s remarks follow a growing push to normalize state-controlled, surveillance-based digital money as a natural progression of currency. The RBI’s digital rupee CBDC, currently in pilot phase, is quickly growing into one of the most advanced CBDCs on the planet. It is being embedded into the government’s UPI payment system and offered through existing financial institutions and platforms. Decentralized alternatives like Bitcoin can achieve financial inclusion and payment efficiency too — but without sacrificing privacy, autonomy, or basic rights over to the state.
Tanzania | Opposition Party Excluded From Election Amid Financial Repression
Last week, the Tanzanian regime banned the use of foreign currency in transactions, leaving Tanzanians to rely solely on the rapidly depreciating Tanzanian shilling. Now, Tanzania's ruling party has taken a decisive step to eliminate political opposition ahead of October’s general elections by barring the CHADEMA party from participation under the pretense of treason against their party leader, Tundu Lissu. Law enforcement arrested Lissu at a public rally where he was calling for electoral reforms. This political repression is not happening in isolation. Last year, the Tanzanian regime blocked access to X, detained hundreds of opposition members, and disappeared dissidents. These developments suggest a broader strategy to silence criticism and electoral competition through arrests, censorship, and economic coercion.
BITCOIN AND FREEDOM TECH NEWS
Samiz | Create a Bluetooth Mesh Network with Nostr
Samiz, an app for creating a Bluetooth mesh network over nostr, is officially available for testing. Mesh networks, where interconnected computers relay data to one another, can provide offline access to nostr if enough users participate. For example, when an individual is offline but has Samiz enabled, their device can connect to other nearby devices through Bluetooth, allowing nostr messages to hop locally from phone to phone until reaching someone with internet access, who can then broadcast the message to the wider nostr network. Mesh networks like this hold powerful implications for activists and communities facing censorship, Internet shutdowns, or surveillance. In places with restricted finances and organization, Samiz, while early in development, can potentially offer a way to distribute information through nostr without relying on infrastructure that authoritarian regimes can shut down.
Spark | New Bitcoin Payments Protocol Now Live
Lightspark, a company building on the Bitcoin Lightning Network, officially released Spark, a new payment protocol built on Bitcoin to make transactions faster, cheaper, and more privacy-protecting. Spark leverages a technology called statechains to enable self-custodial and off-chain Bitcoin transactions for users by transferring the private keys associated with their bitcoin rather than signing and sending a transaction with said keys. Spark also supports stablecoins (digital tokens pegged to fiat currency) and allows users to receive payments while offline. While these are promising developments, in its current state, Spark is not completely trustless; therefore, it is advisable only to hold a small balance of funds on the protocol as this new payment technology gets off the ground. You can learn more about Spark here.
Boltz | Now Supports Nostr Zaps
Boltz, a non-custodial bridge for swapping between different Bitcoin layers, released a new feature called Zap Swaps, enabling users to make Lightning payments as low as 21 satoshis (small units of bitcoin). This feature enables bitcoin microtransactions like nostr zaps, which are use cases that previously required workaround solutions. With the release, users of Boltz-powered Bitcoin wallets like Misty Breez can now leverage their wallets for zaps on nostr. These small, uncensorable bitcoin payments are a powerful tool for supporting activists, journalists, and dissidents — offering a permissionless way to support free speech and financial freedom worldwide. HRF is pleased to see this past HRF grantee add support for the latest freedom tech features.
Coinswap | Adds Support for Coin Selection
Coinswap, an in-development protocol that enables users to privately swap Bitcoin with one another, added support for coin selection, boosting the protocol’s privacy capabilities. Coin selection allows Bitcoin users to choose which of their unspent transaction outputs (UTXOs) to spend, giving them granular control over their transactions and the information they choose to reveal. For activists, journalists, and anyone operating under financial surveillance and repression, this addition (when fully implemented and released) can strengthen Bitcoin’s ability to resist censorship and protect human rights. HRF’s first Bitcoin Development Fund (BDF) grant was to Coinswap, and we are glad to see the continued development of the protocol.
bitcoin++ | Upcoming Bitcoin Developer Conference
The next bitcoin++ conference, a global, bitcoin-only developer series organized by Bitcoin educator Lisa Neigut, will occur in Austin, Texas, from May 7 to 9, 2025. A diverse group of privacy advocates, developers, and freedom tech enthusiasts will convene to learn about the mempool (the queue of pending and unconfirmed transactions in a Bitcoin node). Attendees will learn how Bitcoin transactions are sorted into blocks, mempool policies, and how transactions move through time and space to reach the next block. These events offer an incredible opportunity to connect with the technical Bitcoin community, who are ultimately many of the figures building the freedom tools that are helping individuals preserve their rights and freedoms in the face of censorship. Get your tickets here.
OpenSats | Announces 11th Wave of Nostr Grants
OpenSats, a nonprofit organization supporting open-source software and projects, announced its 11th round of grants for nostr, a decentralized protocol that enables uncensorable communications. Two projects stand out for their potential impact on financial freedom and activism: HAMSTR, which enables nostr messaging over ham radio that keeps information and payments flowing in off-grid or censored environments, and Nostr Double Ratchet, which brings end-to-end encrypted private messaging to nostr clients, safeguarding activists from surveillance. These tools help dissidents stay connected, coordinate securely, and transact privately, making them powerful assets for those resisting authoritarian control. Read the full list of grants here.
Bitcoin Design Community | Organizes Designathon for Open-Source UX Designers
The Bitcoin Design Community is hosting its next Designathon between May 4 and 18, 2025, inviting designers of all levels and backgrounds to creatively explore ideas to advance Bitcoin’s user experience and interface. Unlike traditional hackathons, this event centers specifically on design, encouraging open collaboration on projects that improve usability, accessibility, and innovation in open-source Bitcoin tools. Participants can earn monetary prizes, rewards, and recognition for their work. Anyone can join or start a project. Learn more here.
RECOMMENDED CONTENT
Plunging Currencies, CBDCs, and New Bitcoin Freedom Tools with Guy Swann
In this reading on the Bitcoin Audible podcast, host Guy Swan reads HRF’s Financial Freedom Report #67, offering listeners a front-row view into the latest developments in financial repression and resistance. He unpacks how collapsing currencies, rising inflation, and CBDC rollouts tighten state control in Turkey, Russia, and Nigeria. But he also highlights the tools for pushing back, from the first Stratum V2 mining pool to Cashu’s new Tap-to-Pay ecash feature. If you’re a reader of the Financial Freedom Report, we encourage you to check out the Bitcoin Audible podcast, where Guy Swan will be doing monthly readings of our newsletter. Listen to the full recording here.
Bitcoin Beyond Capital: Freedom Money for the Global South with Femi Longe
In this interview at the 2025 MIT Bitcoin Expo, journalist Frank Corva speaks with Femi Longe, HRF’s global bitcoin lead, who shares insights on Bitcoin’s growing role as freedom money for those living under authoritarian regimes. The conversation highlights the importance of building Bitcoin solutions that center on the specific problems faced by communities rather than the technology itself. Longe commends projects like Tando in Kenya and Bit.Spenda in Ghana, which integrate Bitcoin and Lightning into familiar financial channels, making Bitcoin more practical and accessible for everyday payments and saving. You can watch the interview here and catch the livestreams of the full 2025 MIT Bitcoin Expo here.
If this article was forwarded to you and you enjoyed reading it, please consider subscribing to the Financial Freedom Report here.
Support the newsletter by donating bitcoin to HRF’s Financial Freedom program via BTCPay.\ Want to contribute to the newsletter? Submit tips, stories, news, and ideas by emailing us at ffreport @ hrf.org
The Bitcoin Development Fund (BDF) is accepting grant proposals on an ongoing basis. The Bitcoin Development Fund is looking to support Bitcoin developers, community builders, and educators. Submit proposals here.
-
@ 62033ff8:e4471203
2025-01-11 15:00:24
收录的内容中 kind=1的部分,实话说 质量不高。 所以我增加了kind=30023 长文的article,但是更新的太少,多个relays 的服务器也没有多少长文。
所有搜索nostr如果需要产生价值,需要有高质量的文章和新闻。 而且现在有很多机器人的文章充满着浪费空间的作用,其他作用都用不上。
https://www.duozhutuan.com 目前放的是给搜索引擎提供搜索的原材料。没有做UI给人类浏览。所以看上去是粗糙的。 我并没有打算去做一个发microblog的 web客户端,那类的客户端太多了。
我觉得nostr社区需要解决的还是应用。如果仅仅是microblog 感觉有点够呛
幸运的是npub.pro 建站这样的,我觉得有点意思。
yakihonne 智能widget 也有意思
我做的TaskQ5 我自己在用了。分布式的任务系统,也挺好的。
-
@ 23b0e2f8:d8af76fc
2025-01-08 18:17:52
Necessário
- Um Android que você não use mais (a câmera deve estar funcionando).
- Um cartão microSD (opcional, usado apenas uma vez).
- Um dispositivo para acompanhar seus fundos (provavelmente você já tem um).
Algumas coisas que você precisa saber
- O dispositivo servirá como um assinador. Qualquer movimentação só será efetuada após ser assinada por ele.
- O cartão microSD será usado para transferir o APK do Electrum e garantir que o aparelho não terá contato com outras fontes de dados externas após sua formatação. Contudo, é possível usar um cabo USB para o mesmo propósito.
- A ideia é deixar sua chave privada em um dispositivo offline, que ficará desligado em 99% do tempo. Você poderá acompanhar seus fundos em outro dispositivo conectado à internet, como seu celular ou computador pessoal.
O tutorial será dividido em dois módulos:
- Módulo 1 - Criando uma carteira fria/assinador.
- Módulo 2 - Configurando um dispositivo para visualizar seus fundos e assinando transações com o assinador.
No final, teremos:
- Uma carteira fria que também servirá como assinador.
- Um dispositivo para acompanhar os fundos da carteira.

Módulo 1 - Criando uma carteira fria/assinador
-
Baixe o APK do Electrum na aba de downloads em https://electrum.org/. Fique à vontade para verificar as assinaturas do software, garantindo sua autenticidade.
-
Formate o cartão microSD e coloque o APK do Electrum nele. Caso não tenha um cartão microSD, pule este passo.

- Retire os chips e acessórios do aparelho que será usado como assinador, formate-o e aguarde a inicialização.

- Durante a inicialização, pule a etapa de conexão ao Wi-Fi e rejeite todas as solicitações de conexão. Após isso, você pode desinstalar aplicativos desnecessários, pois precisará apenas do Electrum. Certifique-se de que Wi-Fi, Bluetooth e dados móveis estejam desligados. Você também pode ativar o modo avião.\ (Curiosidade: algumas pessoas optam por abrir o aparelho e danificar a antena do Wi-Fi/Bluetooth, impossibilitando essas funcionalidades.)

- Insira o cartão microSD com o APK do Electrum no dispositivo e instale-o. Será necessário permitir instalações de fontes não oficiais.
- No Electrum, crie uma carteira padrão e gere suas palavras-chave (seed). Anote-as em um local seguro. Caso algo aconteça com seu assinador, essas palavras permitirão o acesso aos seus fundos novamente. (Aqui entra seu método pessoal de backup.)

Módulo 2 - Configurando um dispositivo para visualizar seus fundos e assinando transações com o assinador.
-
Criar uma carteira somente leitura em outro dispositivo, como seu celular ou computador pessoal, é uma etapa bastante simples. Para este tutorial, usaremos outro smartphone Android com Electrum. Instale o Electrum a partir da aba de downloads em https://electrum.org/ ou da própria Play Store. (ATENÇÃO: O Electrum não existe oficialmente para iPhone. Desconfie se encontrar algum.)
-
Após instalar o Electrum, crie uma carteira padrão, mas desta vez escolha a opção Usar uma chave mestra.

- Agora, no assinador que criamos no primeiro módulo, exporte sua chave pública: vá em Carteira > Detalhes da carteira > Compartilhar chave mestra pública.

-
Escaneie o QR gerado da chave pública com o dispositivo de consulta. Assim, ele poderá acompanhar seus fundos, mas sem permissão para movimentá-los.
-
Para receber fundos, envie Bitcoin para um dos endereços gerados pela sua carteira: Carteira > Addresses/Coins.
-
Para movimentar fundos, crie uma transação no dispositivo de consulta. Como ele não possui a chave privada, será necessário assiná-la com o dispositivo assinador.

- No assinador, escaneie a transação não assinada, confirme os detalhes, assine e compartilhe. Será gerado outro QR, desta vez com a transação já assinada.

- No dispositivo de consulta, escaneie o QR da transação assinada e transmita-a para a rede.
Conclusão
Pontos positivos do setup:
- Simplicidade: Basta um dispositivo Android antigo.
- Flexibilidade: Funciona como uma ótima carteira fria, ideal para holders.
Pontos negativos do setup:
- Padronização: Não utiliza seeds no padrão BIP-39, você sempre precisará usar o electrum.
- Interface: A aparência do Electrum pode parecer antiquada para alguns usuários.
Nesse ponto, temos uma carteira fria que também serve para assinar transações. O fluxo de assinar uma transação se torna: Gerar uma transação não assinada > Escanear o QR da transação não assinada > Conferir e assinar essa transação com o assinador > Gerar QR da transação assinada > Escanear a transação assinada com qualquer outro dispositivo que possa transmiti-la para a rede.
Como alguns devem saber, uma transação assinada de Bitcoin é praticamente impossível de ser fraudada. Em um cenário catastrófico, você pode mesmo que sem internet, repassar essa transação assinada para alguém que tenha acesso à rede por qualquer meio de comunicação. Mesmo que não queiramos que isso aconteça um dia, esse setup acaba por tornar essa prática possível.
-
@ 069c4a92:ce7df3ed
2025-05-05 20:57:23
The Flash USDT Generator is responsible for producing and storing Flash USDT tokens with a flexible daily limit. It ensures a consistent supply of tokens for transactions while managing distribution securely and efficiently. Our Flash USDT offers a unique, temporary cryptocurrency that lasts for 90 days before expiring. This innovative solution allows for seamlesstrading and transferring of funds. Notably, the Flash Bitcoin and USDT can be transferred to 12 different wallets, including prominent platforms like Binance and Trust Wallet.
Features Adjustable Daily Limit: Customizable settings allow for modifying the token generation cap. Automated Distribution: Ensures quick and secure token transfers to user wallets. Minimal Latency: Prevents blockchain congestion issues for seamless transfers. Real-Time Transaction Verification: Each transaction is immediately verified on the respective blockchain explorer to confirm accuracy and validity. Temporary Nature: One of the most distinctive characteristics of USDT FLASH Generator is that it generates flash coin that is designed to disappear from any wallet after a period of ninety days. This unique feature ensures that any assets received in USDT FLASH will not linger indefinitely, creating a dynamic and engaging transaction experience.
Kindly visit globalfashexperts.com for more information Contact Information For more information or to make a purchase, please contact us through the following channels:
Email: globalfashexperts@gmail.com Flash USDT:https://globalfashexperts.com/product/flash-usdt/ Flash USDT: https://globalfashexperts.com/product/flash-usdt-generator-software/The Flash USDT Generator is responsible for producing and storing Flash USDT tokens with a flexible daily limit. It ensures a consistent supply of tokens for transactions while managing distribution securely and efficiently. Our Flash USDT offers a unique, temporary cryptocurrency that lasts for 90 days before expiring. This innovative solution allows for seamlesstrading and transferring of funds. Notably, the Flash Bitcoin and USDT can be transferred to 12 different wallets, including prominent platforms like Binance and Trust Wallet.
Features
- Adjustable Daily Limit: Customizable settings allow for modifying the token generation cap.
- Automated Distribution: Ensures quick and secure token transfers to user wallets.
- Minimal Latency: Prevents blockchain congestion issues for seamless transfers.
- Real-Time Transaction Verification: Each transaction is immediately verified on the respective blockchain explorer to confirm accuracy and validity.
- Temporary Nature: One of the most distinctive characteristics of USDT FLASH Generator is that it generates flash coin that is designed to disappear from any wallet after a period of ninety days. This unique feature ensures that any assets received in USDT FLASH will not linger indefinitely, creating a dynamic and engaging transaction experience.
 Kindly visit globalfashexperts.com for more information
Kindly visit globalfashexperts.com for more informationContact Information
For more information or to make a purchase, please contact us through the following channels:
- Email: globalfashexperts@gmail.com
- Flash USDT:https://globalfashexperts.com/product/flash-usdt/
- Flash USDT: https://globalfashexperts.com/product/flash-usdt-generator-software/
-
@ 207ad2a0:e7cca7b0
2025-01-07 03:46:04
Quick context: I wanted to check out Nostr's longform posts and this blog post seemed like a good one to try and mirror. It's originally from my free to read/share attempt to write a novel, but this post here is completely standalone - just describing how I used AI image generation to make a small piece of the work.
Hold on, put your pitchforks down - outside of using Grammerly & Emacs for grammatical corrections - not a single character was generated or modified by computers; a non-insignificant portion of my first draft originating on pen & paper. No AI is ~~weird and crazy~~ imaginative enough to write like I do. The only successful AI contribution you'll find is a single image, the map, which I heavily edited. This post will go over how I generated and modified an image using AI, which I believe brought some value to the work, and cover a few quick thoughts about AI towards the end.
Let's be clear, I can't draw, but I wanted a map which I believed would improve the story I was working on. After getting abysmal results by prompting AI with text only I decided to use "Diffuse the Rest," a Stable Diffusion tool that allows you to provide a reference image + description to fine tune what you're looking for. I gave it this Microsoft Paint looking drawing:

and after a number of outputs, selected this one to work on:
The image is way better than the one I provided, but had I used it as is, I still feel it would have decreased the quality of my work instead of increasing it. After firing up Gimp I cropped out the top and bottom, expanded the ocean and separated the landmasses, then copied the top right corner of the large landmass to replace the bottom left that got cut off. Now we've got something that looks like concept art: not horrible, and gets the basic idea across, but it's still due for a lot more detail.
The next thing I did was add some texture to make it look more map like. I duplicated the layer in Gimp and applied the "Cartoon" filter to both for some texture. The top layer had a much lower effect strength to give it a more textured look, while the lower layer had a higher effect strength that looked a lot like mountains or other terrain features. Creating a layer mask allowed me to brush over spots to display the lower layer in certain areas, giving it some much needed features.
At this point I'd made it to where I felt it may improve the work instead of detracting from it - at least after labels and borders were added, but the colors seemed artificial and out of place. Luckily, however, this is when PhotoFunia could step in and apply a sketch effect to the image.
At this point I was pretty happy with how it was looking, it was close to what I envisioned and looked very visually appealing while still being a good way to portray information. All that was left was to make the white background transparent, add some minor details, and add the labels and borders. Below is the exact image I wound up using:
Overall, I'm very satisfied with how it turned out, and if you're working on a creative project, I'd recommend attempting something like this. It's not a central part of the work, but it improved the chapter a fair bit, and was doable despite lacking the talent and not intending to allocate a budget to my making of a free to read and share story.
The AI Generated Elephant in the Room
If you've read my non-fiction writing before, you'll know that I think AI will find its place around the skill floor as opposed to the skill ceiling. As you saw with my input, I have absolutely zero drawing talent, but with some elbow grease and an existing creative direction before and after generating an image I was able to get something well above what I could have otherwise accomplished. Outside of the lowest common denominators like stock photos for the sole purpose of a link preview being eye catching, however, I doubt AI will be wholesale replacing most creative works anytime soon. I can assure you that I tried numerous times to describe the map without providing a reference image, and if I used one of those outputs (or even just the unedited output after providing the reference image) it would have decreased the quality of my work instead of improving it.
I'm going to go out on a limb and expect that AI image, text, and video is all going to find its place in slop & generic content (such as AI generated slop replacing article spinners and stock photos respectively) and otherwise be used in a supporting role for various creative endeavors. For people working on projects like I'm working on (e.g. intended budget $0) it's helpful to have an AI capable of doing legwork - enabling projects to exist or be improved in ways they otherwise wouldn't have. I'm also guessing it'll find its way into more professional settings for grunt work - think a picture frame or fake TV show that would exist in the background of an animated project - likely a detail most people probably wouldn't notice, but that would save the creators time and money and/or allow them to focus more on the essential aspects of said work. Beyond that, as I've predicted before: I expect plenty of emails will be generated from a short list of bullet points, only to be summarized by the recipient's AI back into bullet points.
I will also make a prediction counter to what seems mainstream: AI is about to peak for a while. The start of AI image generation was with Google's DeepDream in 2015 - image recognition software that could be run in reverse to "recognize" patterns where there were none, effectively generating an image from digital noise or an unrelated image. While I'm not an expert by any means, I don't think we're too far off from that a decade later, just using very fine tuned tools that develop more coherent images. I guess that we're close to maxing out how efficiently we're able to generate images and video in that manner, and the hard caps on how much creative direction we can have when using AI - as well as the limits to how long we can keep it coherent (e.g. long videos or a chronologically consistent set of images) - will prevent AI from progressing too far beyond what it is currently unless/until another breakthrough occurs.
-
@ 52b4a076:e7fad8bd
2025-04-28 00:48:57
I have been recently building NFDB, a new relay DB. This post is meant as a short overview.
Regular relays have challenges
Current relay software have significant challenges, which I have experienced when hosting Nostr.land: - Scalability is only supported by adding full replicas, which does not scale to large relays. - Most relays use slow databases and are not optimized for large scale usage. - Search is near-impossible to implement on standard relays. - Privacy features such as NIP-42 are lacking. - Regular DB maintenance tasks on normal relays require extended downtime. - Fault-tolerance is implemented, if any, using a load balancer, which is limited. - Personalization and advanced filtering is not possible. - Local caching is not supported.
NFDB: A scalable database for large relays
NFDB is a new database meant for medium-large scale relays, built on FoundationDB that provides: - Near-unlimited scalability - Extended fault tolerance - Instant loading - Better search - Better personalization - and more.
Search
NFDB has extended search capabilities including: - Semantic search: Search for meaning, not words. - Interest-based search: Highlight content you care about. - Multi-faceted queries: Easily filter by topic, author group, keywords, and more at the same time. - Wide support for event kinds, including users, articles, etc.
Personalization
NFDB allows significant personalization: - Customized algorithms: Be your own algorithm. - Spam filtering: Filter content to your WoT, and use advanced spam filters. - Topic mutes: Mute topics, not keywords. - Media filtering: With Nostr.build, you will be able to filter NSFW and other content - Low data mode: Block notes that use high amounts of cellular data. - and more
Other
NFDB has support for many other features such as: - NIP-42: Protect your privacy with private drafts and DMs - Microrelays: Easily deploy your own personal microrelay - Containers: Dedicated, fast storage for discoverability events such as relay lists
Calcite: A local microrelay database
Calcite is a lightweight, local version of NFDB that is meant for microrelays and caching, meant for thousands of personal microrelays.
Calcite HA is an additional layer that allows live migration and relay failover in under 30 seconds, providing higher availability compared to current relays with greater simplicity. Calcite HA is enabled in all Calcite deployments.
For zero-downtime, NFDB is recommended.
Noswhere SmartCache
Relays are fixed in one location, but users can be anywhere.
Noswhere SmartCache is a CDN for relays that dynamically caches data on edge servers closest to you, allowing: - Multiple regions around the world - Improved throughput and performance - Faster loading times
routerd
routerdis a custom load-balancer optimized for Nostr relays, integrated with SmartCache.routerdis specifically integrated with NFDB and Calcite HA to provide fast failover and high performance.Ending notes
NFDB is planned to be deployed to Nostr.land in the coming weeks.
A lot more is to come. 👀️️️️️️
-
@ c9badfea:610f861a
2025-05-05 20:16:29
- Install PocketPal (it's free and open source)
- Launch the app, open the menu, and navigate to Models
- Download one or more models (e.g. Phi, Llama, Qwen)
- Once downloaded, tap Load to start chatting
ℹ️ Experiment with different models and their quantizations (Q4, Q6, Q8, etc.) to find the most suitable one
-
@ 3f770d65:7a745b24
2025-01-05 18:56:33
New Year’s resolutions often feel boring and repetitive. Most revolve around getting in shape, eating healthier, or giving up alcohol. While the idea is interesting—using the start of a new calendar year as a catalyst for change—it also seems unnecessary. Why wait for a specific date to make a change? If you want to improve something in your life, you can just do it. You don’t need an excuse.
That’s why I’ve never been drawn to the idea of making a list of resolutions. If I wanted a change, I’d make it happen, without worrying about the calendar. At least, that’s how I felt until now—when, for once, the timing actually gave me a real reason to embrace the idea of New Year’s resolutions.
Enter Olas.
If you're a visual creator, you've likely experienced the relentless grind of building a following on platforms like Instagram—endless doomscrolling, ever-changing algorithms, and the constant pressure to stay relevant. But what if there was a better way? Olas is a Nostr-powered alternative to Instagram that prioritizes community, creativity, and value-for-value exchanges. It's a game changer.
Instagram’s failings are well-known. Its algorithm often dictates whose content gets seen, leaving creators frustrated and powerless. Monetization hurdles further alienate creators who are forced to meet arbitrary follower thresholds before earning anything. Additionally, the platform’s design fosters endless comparisons and exposure to negativity, which can take a significant toll on mental health.
Instagram’s algorithms are notorious for keeping users hooked, often at the cost of their mental health. I've spoken about this extensively, most recently at Nostr Valley, explaining how legacy social media is bad for you. You might find yourself scrolling through content that leaves you feeling anxious or drained. Olas takes a fresh approach, replacing "doomscrolling" with "bloomscrolling." This is a common theme across the Nostr ecosystem. The lack of addictive rage algorithms allows the focus to shift to uplifting, positive content that inspires rather than exhausts.
Monetization is another area where Olas will set itself apart. On Instagram, creators face arbitrary barriers to earning—needing thousands of followers and adhering to restrictive platform rules. Olas eliminates these hurdles by leveraging the Nostr protocol, enabling creators to earn directly through value-for-value exchanges. Fans can support their favorite artists instantly, with no delays or approvals required. The plan is to enable a brand new Olas account that can get paid instantly, with zero followers - that's wild.
Olas addresses these issues head-on. Operating on the open Nostr protocol, it removes centralized control over one's content’s reach or one's ability to monetize. With transparent, configurable algorithms, and a community that thrives on mutual support, Olas creates an environment where creators can grow and succeed without unnecessary barriers.
Join me on my New Year's resolution. Join me on Olas and take part in the #Olas365 challenge! It’s a simple yet exciting way to share your content. The challenge is straightforward: post at least one photo per day on Olas (though you’re welcome to share more!).
Download on Android or download via Zapstore.
Let's make waves together.
-
@ e6817453:b0ac3c39
2025-01-05 14:29:17
The Rise of Graph RAGs and the Quest for Data Quality
As we enter a new year, it’s impossible to ignore the boom of retrieval-augmented generation (RAG) systems, particularly those leveraging graph-based approaches. The previous year saw a surge in advancements and discussions about Graph RAGs, driven by their potential to enhance large language models (LLMs), reduce hallucinations, and deliver more reliable outputs. Let’s dive into the trends, challenges, and strategies for making the most of Graph RAGs in artificial intelligence.
Booming Interest in Graph RAGs
Graph RAGs have dominated the conversation in AI circles. With new research papers and innovations emerging weekly, it’s clear that this approach is reshaping the landscape. These systems, especially those developed by tech giants like Microsoft, demonstrate how graphs can:
- Enhance LLM Outputs: By grounding responses in structured knowledge, graphs significantly reduce hallucinations.
- Support Complex Queries: Graphs excel at managing linked and connected data, making them ideal for intricate problem-solving.
Conferences on linked and connected data have increasingly focused on Graph RAGs, underscoring their central role in modern AI systems. However, the excitement around this technology has brought critical questions to the forefront: How do we ensure the quality of the graphs we’re building, and are they genuinely aligned with our needs?
Data Quality: The Foundation of Effective Graphs
A high-quality graph is the backbone of any successful RAG system. Constructing these graphs from unstructured data requires attention to detail and rigorous processes. Here’s why:
- Richness of Entities: Effective retrieval depends on graphs populated with rich, detailed entities.
- Freedom from Hallucinations: Poorly constructed graphs amplify inaccuracies rather than mitigating them.
Without robust data quality, even the most sophisticated Graph RAGs become ineffective. As a result, the focus must shift to refining the graph construction process. Improving data strategy and ensuring meticulous data preparation is essential to unlock the full potential of Graph RAGs.
Hybrid Graph RAGs and Variations
While standard Graph RAGs are already transformative, hybrid models offer additional flexibility and power. Hybrid RAGs combine structured graph data with other retrieval mechanisms, creating systems that:
- Handle diverse data sources with ease.
- Offer improved adaptability to complex queries.
Exploring these variations can open new avenues for AI systems, particularly in domains requiring structured and unstructured data processing.
Ontology: The Key to Graph Construction Quality
Ontology — defining how concepts relate within a knowledge domain — is critical for building effective graphs. While this might sound abstract, it’s a well-established field blending philosophy, engineering, and art. Ontology engineering provides the framework for:
- Defining Relationships: Clarifying how concepts connect within a domain.
- Validating Graph Structures: Ensuring constructed graphs are logically sound and align with domain-specific realities.
Traditionally, ontologists — experts in this discipline — have been integral to large enterprises and research teams. However, not every team has access to dedicated ontologists, leading to a significant challenge: How can teams without such expertise ensure the quality of their graphs?
How to Build Ontology Expertise in a Startup Team
For startups and smaller teams, developing ontology expertise may seem daunting, but it is achievable with the right approach:
- Assign a Knowledge Champion: Identify a team member with a strong analytical mindset and give them time and resources to learn ontology engineering.
- Provide Training: Invest in courses, workshops, or certifications in knowledge graph and ontology creation.
- Leverage Partnerships: Collaborate with academic institutions, domain experts, or consultants to build initial frameworks.
- Utilize Tools: Introduce ontology development tools like Protégé, OWL, or SHACL to simplify the creation and validation process.
- Iterate with Feedback: Continuously refine ontologies through collaboration with domain experts and iterative testing.
So, it is not always affordable for a startup to have a dedicated oncologist or knowledge engineer in a team, but you could involve consulters or build barefoot experts.
You could read about barefoot experts in my article :
Even startups can achieve robust and domain-specific ontology frameworks by fostering in-house expertise.
How to Find or Create Ontologies
For teams venturing into Graph RAGs, several strategies can help address the ontology gap:
-
Leverage Existing Ontologies: Many industries and domains already have open ontologies. For instance:
-
Public Knowledge Graphs: Resources like Wikipedia’s graph offer a wealth of structured knowledge.
- Industry Standards: Enterprises such as Siemens have invested in creating and sharing ontologies specific to their fields.
-
Business Framework Ontology (BFO): A valuable resource for enterprises looking to define business processes and structures.
-
Build In-House Expertise: If budgets allow, consider hiring knowledge engineers or providing team members with the resources and time to develop expertise in ontology creation.
-
Utilize LLMs for Ontology Construction: Interestingly, LLMs themselves can act as a starting point for ontology development:
-
Prompt-Based Extraction: LLMs can generate draft ontologies by leveraging their extensive training on graph data.
- Domain Expert Refinement: Combine LLM-generated structures with insights from domain experts to create tailored ontologies.
Parallel Ontology and Graph Extraction
An emerging approach involves extracting ontologies and graphs in parallel. While this can streamline the process, it presents challenges such as:
- Detecting Hallucinations: Differentiating between genuine insights and AI-generated inaccuracies.
- Ensuring Completeness: Ensuring no critical concepts are overlooked during extraction.
Teams must carefully validate outputs to ensure reliability and accuracy when employing this parallel method.
LLMs as Ontologists
While traditionally dependent on human expertise, ontology creation is increasingly supported by LLMs. These models, trained on vast amounts of data, possess inherent knowledge of many open ontologies and taxonomies. Teams can use LLMs to:
- Generate Skeleton Ontologies: Prompt LLMs with domain-specific information to draft initial ontology structures.
- Validate and Refine Ontologies: Collaborate with domain experts to refine these drafts, ensuring accuracy and relevance.
However, for validation and graph construction, formal tools such as OWL, SHACL, and RDF should be prioritized over LLMs to minimize hallucinations and ensure robust outcomes.
Final Thoughts: Unlocking the Power of Graph RAGs
The rise of Graph RAGs underscores a simple but crucial correlation: improving graph construction and data quality directly enhances retrieval systems. To truly harness this power, teams must invest in understanding ontologies, building quality graphs, and leveraging both human expertise and advanced AI tools.
As we move forward, the interplay between Graph RAGs and ontology engineering will continue to shape the future of AI. Whether through adopting existing frameworks or exploring innovative uses of LLMs, the path to success lies in a deep commitment to data quality and domain understanding.
Have you explored these technologies in your work? Share your experiences and insights — and stay tuned for more discussions on ontology extraction and its role in AI advancements. Cheers to a year of innovation!
-
@ 6538925e:571e55c3
2025-05-05 20:00:48
It’s been a little while since we released a major design update, so we’re really excited to get this new version of the app into your hands. Here’s a breakdown of all the main updates included in Fountain 1.2:
 #### Library Design Update
#### Library Design Update-
New content-type filters at the top of the page make it easier to navigate between podcasts and music in your library.
-
Recently Played is now the default view in your library, so it’s easier to jump back into podcasts you’ve already started.
-
The Music filter now makes it easier to find saved tracks and albums, and it also gives you a list of all the artists whose music you’ve saved.
-
We’ve refreshed the design of the content cards to make it easier to see how much time is remaining on episodes you’ve already started.
 #### Content Pages Design Update
#### Content Pages Design Update-
All of the different content pages have undergone an extensive redesign, including shows, episodes, artists, albums, tracks, clips and playlists
-
We’ve replaced the tab layout we were using on the content pages with one scrollable page, making it easier to access features like chapters and tracklists
-
We’ve sanitised the formatting of show notes too, and if there is no activity for a given episode, we now display the expanded show notes
 #### Episode Summaries
#### Episode SummariesEver looked at a 4-hour Lex Fridman episode and wished you could just read a high-level summary? We certainly have, so we did something about it.
-
Every episode page now has a Summary button above the show notes.
-
Simply pay 500 sats to unlock a summary, or upgrade to Fountain Premium for $2.99/month to enjoy unlimited summaries.
-
Summaries and transcripts now come as a bundle — two for the price of one!
-
Thanks to major improvements, they’re now faster, cheaper, and more accurate than ever before.
 #### Playback Improvements
#### Playback ImprovementsWe’ve completely rebuilt our audio engine from the ground up. Playback is now more robust and reliable — especially for music. Here are some of the key enhancements in Fountain 1.2:
-
Tracks now load and play instantly when tapped.
-
When playing a collection of tracks (e.g. from an artist, album, or playlist), you can now skip seamlessly between them.
-
We’ve replaced the scrollable player page with full-screen modals to make it easier to access show notes, comments, transcripts, chapters, tracklists, and your queue.
-
The new Smart Resume feature rewinds the episode by 5 seconds when you hit pause, so you don’t miss a beat.
-
You can now skip forward or backward by 60 seconds for faster navigation through episodes.
Other Bug Fixes & Improvements
-
Rebuilt payment stats for more complete and reliable transaction records.
-
Refreshed the design of the Settings pages for better usability.
-
Added new episode notification preferences in Settings.
-
Fixed several playback issues that were causing crashes or freezes.
-
Updated lock screen display and controls for livestreams.
-
Fixed issue where the next item in the queue paused unexpectedly.
-
Resolved playback stuttering on Android during livestreams.
-
Fixed disappearing playback controls on the lock screen.
-
Fixed playback speed not updating correctly.
-
Resolved issue where played episodes couldn’t be replayed.
-
Fixed playback not resuming correctly when listening in the car.
-
Synced car playback position with the device.
-
Fixed persistent car display refresh issue.
-
Fixed volume control via car controls.
-
Resolved issue with headphone controls after playing a transcript.
-
Fixed disappearing metadata on the lock screen.
-
Fixed bug where downloaded episodes stopped in airplane mode but showed as playing.
We would love to hear how you’re finding Fountain 1.2. Please submit your thoughts and feedback via the main menu in the app and we will take it on board as we continue to improve the app.
If you want to help test new features out before they get released, you can join Fountain Beta on Telegram. All iOS and Android users welcome.
-
-
@ a4a6b584:1e05b95b
2025-01-02 18:13:31
The Four-Layer Framework
Layer 1: Zoom Out

Start by looking at the big picture. What’s the subject about, and why does it matter? Focus on the overarching ideas and how they fit together. Think of this as the 30,000-foot view—it’s about understanding the "why" and "how" before diving into the "what."
Example: If you’re learning programming, start by understanding that it’s about giving logical instructions to computers to solve problems.
- Tip: Keep it simple. Summarize the subject in one or two sentences and avoid getting bogged down in specifics at this stage.
Once you have the big picture in mind, it’s time to start breaking it down.
Layer 2: Categorize and Connect

Now it’s time to break the subject into categories—like creating branches on a tree. This helps your brain organize information logically and see connections between ideas.
Example: Studying biology? Group concepts into categories like cells, genetics, and ecosystems.
- Tip: Use headings or labels to group similar ideas. Jot these down in a list or simple diagram to keep track.
With your categories in place, you’re ready to dive into the details that bring them to life.
Layer 3: Master the Details

Once you’ve mapped out the main categories, you’re ready to dive deeper. This is where you learn the nuts and bolts—like formulas, specific techniques, or key terminology. These details make the subject practical and actionable.
Example: In programming, this might mean learning the syntax for loops, conditionals, or functions in your chosen language.
- Tip: Focus on details that clarify the categories from Layer 2. Skip anything that doesn’t add to your understanding.
Now that you’ve mastered the essentials, you can expand your knowledge to include extra material.
Layer 4: Expand Your Horizons

Finally, move on to the extra material—less critical facts, trivia, or edge cases. While these aren’t essential to mastering the subject, they can be useful in specialized discussions or exams.
Example: Learn about rare programming quirks or historical trivia about a language’s development.
- Tip: Spend minimal time here unless it’s necessary for your goals. It’s okay to skim if you’re short on time.
Pro Tips for Better Learning
1. Use Active Recall and Spaced Repetition
Test yourself without looking at notes. Review what you’ve learned at increasing intervals—like after a day, a week, and a month. This strengthens memory by forcing your brain to actively retrieve information.
2. Map It Out
Create visual aids like diagrams or concept maps to clarify relationships between ideas. These are particularly helpful for organizing categories in Layer 2.
3. Teach What You Learn
Explain the subject to someone else as if they’re hearing it for the first time. Teaching exposes any gaps in your understanding and helps reinforce the material.
4. Engage with LLMs and Discuss Concepts
Take advantage of tools like ChatGPT or similar large language models to explore your topic in greater depth. Use these tools to:
- Ask specific questions to clarify confusing points.
- Engage in discussions to simulate real-world applications of the subject.
- Generate examples or analogies that deepen your understanding.Tip: Use LLMs as a study partner, but don’t rely solely on them. Combine these insights with your own critical thinking to develop a well-rounded perspective.
Get Started
Ready to try the Four-Layer Method? Take 15 minutes today to map out the big picture of a topic you’re curious about—what’s it all about, and why does it matter? By building your understanding step by step, you’ll master the subject with less stress and more confidence.
-
@ 1f79058c:eb86e1cb
2025-04-26 13:53:50
I'm currently using this bash script to publish long-form content from local Markdown files to Nostr relays.
It requires all of
yq,jq, andnakto be installed.Usage
Create a signed Nostr event and print it to the console:
bash markdown_to_nostr.sh article-filename.mdCreate a Nostr event and publish it to one or more relays:
bash markdown_to_nostr.sh article-filename.md ws://localhost:7777 wss://nostr.kosmos.orgMarkdown format
You can specify your metadata as YAML in a Front Matter header. Here's an example file:
```markdown
title: "Good Morning" summary: "It's a beautiful day" image: https://example.com/i/beautiful-day.jpg date: 2025-04-24T15:00:00Z tags: gm, poetry published: false
In the blue sky just a few specks of gray
In the evening of a beautiful day
Though last night it rained and more rain on the way
And that more rain is needed 'twould be fair to say.— Francis Duggan ```
The metadata keys are mostly self-explanatory. Note:
- All keys except for
titleare optional date, if present, will be set as thepublished_atdate.- If
publishedis set totrue, it will publish a kind 30023 event, otherwise a kind 30024 (draft) - The
dtag (widely used as URL slug for the article) will be the filename without the.mdextension
- All keys except for
-
@ 6a6be47b:3e74e3e1
2025-05-05 19:49:17
Hi frens, you may or may not have noticed I’ve been MIA for about three weeks. I wanted to take a moment to explain where I’ve been, and why I stepped back for a bit.
At the start of the year, I was determined to make the most of it-and I still am. I’ve been pouring myself into several projects, especially my painting, which has really taken off. I’m so grateful for your support; none of this would be possible without you. But here’s where things got tricky. I started feeling like I had to “earn” every moment of rest, and that mindset snowballed. My health took a hit, and then one of my other projects completely derailed.
The stress piled up, and I felt like I was on the verge of burning out.
Don’t get me wrong-I’ve always welcomed change, even when it’s tough. And this time was no exception. The project I’d been working on for months took a 180, and all that effort seemed to go down the drain. I was frustrated, but I kept pushing, even though I was running on fumes. By the time I “earned” a break, I was too exhausted to enjoy it.
I managed to post a piece about Holy Week on my blog (which I’m really proud of-check it out if you haven’t!), but after that, I was done. I realized I needed to stop, not just for a day, but for a real break. When I finally took a few days off with my husband, it was clear how much I needed it. I was burned out, plain and simple. Now, I’m still putting myself back together. Mentally, I feel drained, but I’m stronger than I was a few weeks ago. I know I’m lucky and privileged to be able to take this time, and I’m grateful for the perspective it’s given me. I also r realize that this isn’t just a “me” thing-most people have been here at some point. We keep going until there’s nothing left, then wonder why we feel like empty shells.
I’ll be back to drawing soon (knock on wood-don’t want to jinx it!). In the meantime, take care of yourselves, and godspeed.
-
@ 3bf0c63f:aefa459d
2025-04-25 19:26:48
Redistributing Git with Nostr
Every time someone tries to "decentralize" Git -- like many projects tried in the past to do it with BitTorrent, IPFS, ScuttleButt or custom p2p protocols -- there is always a lurking comment: "but Git is already distributed!", and then the discussion proceeds to mention some facts about how Git supports multiple remotes and its magic syncing and merging abilities and so on.
Turns out all that is true, Git is indeed all that powerful, and yet GitHub is the big central hub that hosts basically all Git repositories in the giant world of open-source. There are some crazy people that host their stuff elsewhere, but these projects end up not being found by many people, and even when they do they suffer from lack of contributions.
Because everybody has a GitHub account it's easy to open a pull request to a repository of a project you're using if it's on GitHub (to be fair I think it's very annoying to have to clone the repository, then add it as a remote locally, push to it, then go on the web UI and click to open a pull request, then that cloned repository lurks forever in your profile unless you go through 16 screens to delete it -- but people in general seem to think it's easy).
It's much harder to do it on some random other server where some project might be hosted, because now you have to add 4 more even more annoying steps: create an account; pick a password; confirm an email address; setup SSH keys for pushing. (And I'm not even mentioning the basic impossibility of offering
pushaccess to external unknown contributors to people who want to host their own simple homemade Git server.)At this point some may argue that we could all have accounts on GitLab, or Codeberg or wherever else, then those steps are removed. Besides not being a practical strategy this pseudo solution misses the point of being decentralized (or distributed, who knows) entirely: it's far from the ideal to force everybody to have the double of account management and SSH setup work in order to have the open-source world controlled by two shady companies instead of one.
What we want is to give every person the opportunity to host their own Git server without being ostracized. at the same time we must recognize that most people won't want to host their own servers (not even most open-source programmers!) and give everybody the ability to host their stuff on multi-tenant servers (such as GitHub) too. Importantly, though, if we allow for a random person to have a standalone Git server on a standalone server they host themselves on their wood cabin that also means any new hosting company can show up and start offering Git hosting, with or without new cool features, charging high or low or zero, and be immediately competing against GitHub or GitLab, i.e. we must remove the network-effect centralization pressure.
External contributions
The first problem we have to solve is: how can Bob contribute to Alice's repository without having an account on Alice's server?
SourceHut has reminded GitHub users that Git has always had this (for most) arcane
git send-emailcommand that is the original way to send patches, using an once-open protocol.Turns out Nostr acts as a quite powerful email replacement and can be used to send text content just like email, therefore patches are a very good fit for Nostr event contents.
Once you get used to it and the proper UIs (or CLIs) are built sending and applying patches to and from others becomes a much easier flow than the intense clickops mixed with terminal copypasting that is interacting with GitHub (you have to clone the repository on GitHub, then update the remote URL in your local directory, then create a branch and then go back and turn that branch into a Pull Request, it's quite tiresome) that many people already dislike so much they went out of their way to build many GitHub CLI tools just so they could comment on issues and approve pull requests from their terminal.
Replacing GitHub features
Aside from being the "hub" that people use to send patches to other people's code (because no one can do the email flow anymore, justifiably), GitHub also has 3 other big features that are not directly related to Git, but that make its network-effect harder to overcome. Luckily Nostr can be used to create a new environment in which these same features are implemented in a more decentralized and healthy way.
Issues: bug reports, feature requests and general discussions
Since the "Issues" GitHub feature is just a bunch of text comments it should be very obvious that Nostr is a perfect fit for it.
I will not even mention the fact that Nostr is much better at threading comments than GitHub (which doesn't do it at all), which can generate much more productive and organized discussions (and you can opt out if you want).
Search
I use GitHub search all the time to find libraries and projects that may do something that I need, and it returns good results almost always. So if people migrated out to other code hosting providers wouldn't we lose it?
The fact is that even though we think everybody is on GitHub that is a globalist falsehood. Some projects are not on GitHub, and if we use only GitHub for search those will be missed. So even if we didn't have a Nostr Git alternative it would still be necessary to create a search engine that incorporated GitLab, Codeberg, SourceHut and whatnot.
Turns out on Nostr we can make that quite easy by not forcing anyone to integrate custom APIs or hardcoding Git provider URLs: each repository can make itself available by publishing an "announcement" event with a brief description and one or more Git URLs. That makes it easy for a search engine to index them -- and even automatically download the code and index the code (or index just README files or whatever) without a centralized platform ever having to be involved.
The relays where such announcements will be available play a role, of course, but that isn't a bad role: each announcement can be in multiple relays known for storing "public good" projects, some relays may curate only projects known to be very good according to some standards, other relays may allow any kind of garbage, which wouldn't make them good for a search engine to rely upon, but would still be useful in case one knows the exact thing (and from whom) they're searching for (the same is valid for all Nostr content, by the way, and that's where it's censorship-resistance comes from).
Continuous integration
GitHub Actions are a very hardly subsidized free-compute-for-all-paid-by-Microsoft feature, but one that isn't hard to replace at all. In fact there exists today many companies offering the same kind of service out there -- although they are mostly targeting businesses and not open-source projects, before GitHub Actions was introduced there were also many that were heavily used by open-source projects.
One problem is that these services are still heavily tied to GitHub today, they require a GitHub login, sometimes BitBucket and GitLab and whatnot, and do not allow one to paste an arbitrary Git server URL, but that isn't a thing that is very hard to change anyway, or to start from scratch. All we need are services that offer the CI/CD flows, perhaps using the same framework of GitHub Actions (although I would prefer to not use that messy garbage), and charge some few satoshis for it.
It may be the case that all the current services only support the big Git hosting platforms because they rely on their proprietary APIs, most notably the webhooks dispatched when a repository is updated, to trigger the jobs. It doesn't have to be said that Nostr can also solve that problem very easily.
-
@ b17fccdf:b7211155
2024-12-29 12:04:31
🆕 What's changed:
- New bonus guide dedicated to install/upgrade/uninstall PostgreSQL
- Modified the LND guide to use PostgreSQL instead of bbolt
- Modified the Nostr relay guide to use PostgreSQL instead of SQLite (experimental)
- Modified the BTCPay Server bonus guide according to these changes
- Used the lndinit MiniBolt org fork, to add an extra section to migrate an existing LND bbolt database to PostgreSQL (🚨⚠️Experimental - use it behind your responsibility⚠️🚨)
- New Golang bonus guide as a common language for the lndinit compile
- Updated LND to v0.18
- New Bitcoin Core extra section to renovate Tor & I2P addresses
- New Bitcoin Core extra section to generate a full
bitcoin.conffile - Rebuilt some homepage sections and general structure
- Deleted the
$symbol of the commands to easy copy-paste to the terminal - Deleted the initial incoming and the outgoing rules configuration of UFW, due to it being by default
🪧 PD: If you want to use the old database backend of the LND or Nostr relay, follow the next extra sections:
- Use the default bbolt database backend for the LND
- Use the default SQLite database backend for the Nostr relay
⚠️Attention⚠️: The migration process was tested on testnet mode from an existing bbolt database backend to a new PostgreSQL database using lndinit and the results were successful. However, It wasn't tested on mainnet, according to the developer, it is in experimental status which could damage your existing LND database.🚨 Use it behind your responsibility 🧼
🔧 PR related: https://github.com/minibolt-guide/minibolt/pull/93
♻️ Migrate the PostgreSQL database location
If you installed NBXplorer + BTCPay Server, it is probably you have the database of the PostgreSQL cluster on the default path (
/var/lib/postgresql/16/main/), follow the next instructions to migrate it to the new dedicated location on/data/postgresdbfolder:- With user
admincreate the dedicated PostgreSQL data folder
sudo mkdir /data/postgresdb- Assign as the owner to the
postgresuser
sudo chown postgres:postgres /data/postgresdb- Assign permissions of the data folder only to the
postgresuser
sudo chmod -R 700 /data/postgresdb- Stop NBXplorer and BTCPay Server
sudo systemctl stop nbxplorer && sudo systemctl stop btcpayserver- Stop PostgreSQL
sudo systemctl stop postgresql- Use the rsync command to copy all files from the existing database on (
/var/lib/postgresql/16/main) to the new destination directory (/data/postgresdb)
sudo rsync -av /var/lib/postgresql/16/main/ /data/postgresdb/Expected output:
``` sending incremental file list ./ PG_VERSION postgresql.auto.conf postmaster.opts postmaster.pid base/ base/1/ base/1/112 base/1/113 base/1/1247 base/1/1247_fsm base/1/1247_vm base/1/1249 base/1/1249_fsm base/1/1249_vm [...] pg_wal/000000010000000000000009 pg_wal/archive_status/ pg_xact/ pg_xact/0000
sent 164,483,875 bytes received 42,341 bytes 36,561,381.33 bytes/sec total size is 164,311,368 speedup is 1.00 ```
- Edit the PostgreSQL data directory on configuration, to redirect the store to the new location
sudo nano /etc/postgresql/16/main/postgresql.conf --linenumbers- Replace the line 42 to this. Save and exit
data_directory = '/data/postgresdb'- Start PostgreSQL to apply changes and monitor the correct status of the main instance and sub-instance monitoring sessions before
sudo systemctl start postgresql- You can monitor the PostgreSQL main instance by the systemd journal and check the log output to ensure all is correct. You can exit the monitoring at any time with Ctrl-C
journalctl -fu postgresqlExample of the expected output:
Nov 08 11:51:10 minibolt systemd[1]: Stopped PostgreSQL RDBMS. Nov 08 11:51:10 minibolt systemd[1]: Stopping PostgreSQL RDBMS... Nov 08 11:51:13 minibolt systemd[1]: Starting PostgreSQL RDBMS... Nov 08 11:51:13 minibolt systemd[1]: Finished PostgreSQL RDBMS.- You can monitor the PostgreSQL sub-instance by the systemd journal and check log output to ensure all is correct. You can exit monitoring at any time with Ctrl-C
journalctl -fu postgresql@16-mainExample of the expected output:
Nov 08 11:51:10 minibolt systemd[1]: Stopping PostgreSQL Cluster 16-main... Nov 08 11:51:11 minibolt systemd[1]: postgresql@16-main.service: Succeeded. Nov 08 11:51:11 minibolt systemd[1]: Stopped PostgreSQL Cluster 16-main. Nov 08 11:51:11 minibolt systemd[1]: postgresql@16-main.service: Consumed 1h 10min 8.677s CPU time. Nov 08 11:51:11 minibolt systemd[1]: Starting PostgreSQL Cluster 16-main... Nov 08 11:51:13 minibolt systemd[1]: Started PostgreSQL Cluster 16-main.- Start NBXplorer and BTCPay Server again
sudo systemctl start nbxplorer && sudo systemctl start btcpayserver- Monitor to make sure everything is as you left it. You can exit monitoring at any time with Ctrl-C
journalctl -fu nbxplorerjournalctl -fu btcpayserverEnjoy it MiniBolter! 💙
-
@ c9badfea:610f861a
2025-05-05 19:34:45
- Install Kiwix (it's free and open source)
- Download ZIM files from the Kiwix Library (you will find complete offline versions of Wikipedia, Stack Overflow, Bitcoin Wiki, DevDocs and many more)
- Open the downloaded ZIM files within the Kiwix app
ℹ️ You can also package any website using either Kiwix Zimit (online tool) or the Zimit Docker Container (for technical users)
ℹ️
.zimis the file format used for packaged websites -
@ 91d8dece:3453543b
2025-05-05 17:49:36
https://drewztools.com/ flash USDT Are you tired of the long wait times and excessive fees associated with traditional cryptocurrency transactions? Look no further! Flash USDT from @drewztooolz is here to ease the way you send and receive crypto. Experience lightning-fast transfers, total anonymity, and zero fees with this state-of-the-art service. This flash last in the wallet for 90 t0 360 days before it disappears . Just so you know this coin is tradeable , swappable and transferable to many wallet type Flash USDT is not just another crypto tool; it’s a game-changer for anyone involved in cryptocurrency trading, particularly for OTC traders, P2P dealmakers, and cold wallet testers. Here’s why you should consider making it a part of your crypto toolkit: 🔥 Instant Transfers With Flash USDT, you can send high-value USDT to any wallet in under 60 seconds. Imagine the convenience of having your funds appear instantly without the typical delay caused by blockchain confirmations. Still have questions? Reach out via Telegram for 1-on-1 support. Our team is ready to assist you with anything you need! https://drewztools.com/ 💬 @drewztooolz 📲+1 (770) 666–2531
-
@ b17fccdf:b7211155
2024-12-29 11:56:44
A step-by-step guide to building a Bitcoin & Lightning node, and other stuff on a personal computer.
~ > It builds on a personal computer with x86/amd64 architecture processors.
~> It is based on the popular RaspiBolt v3 guide.
Those are some of the most relevant changes:
- Changed OS from Raspberry Pi OS Lite (64-bits) to Ubuntu Server LTS (Long term support) 64-bit PC (AMD64).
- Changed binaries and signatures of the programs to adapt them to x86/amd64 architecture.
- Deleted unnecessary tools and steps, and added others according to this case of use.
- Some useful authentication logs and monitoring commands were added in the security section.
- Added some interesting parameters in the settings of some services to activate and take advantage of new features.
- Changed I2P, Fulcrum, and ThunderHub guides, to be part of the core guide.
- Added exclusive optimization section of services for slow devices.
~ > Complete release notes MiniBolt v1: https://github.com/twofaktor/minibolt/releases/tag/1.0
~ > The MiniBolt guide is available at: https://minibolt.info
~ > Feel free to contribute to the source code on GitHub by opening issues, pull requests or discussions
Created by ⚡2 FakTor⚡
-
@ ec42c765:328c0600
2024-12-22 19:16:31
この記事は前回の内容を把握している人向けに書いています(特にNostrエクステンション(NIP-07)導入)
手順
- 登録する画像を用意する
- 画像をweb上にアップロードする
- 絵文字セットに登録する
1. 登録する画像を用意する
以下のような方法で用意してください。
- 画像編集ソフト等を使って自分で作成する
- 絵文字作成サイトを使う(絵文字ジェネレーター、MEGAMOJI など)
- フリー画像を使う(いらすとや など)
データ量削減
Nostrでは画像をそのまま表示するクライアントが多いので、データ量が大きな画像をそのまま使うとモバイル通信時などに負担がかかります。
データ量を増やさないためにサイズやファイル形式を変更することをおすすめします。
以下は私のおすすめです。 * サイズ:正方形 128×128 ピクセル、長方形 任意の横幅×128 ピクセル * ファイル形式:webp形式(webp変換おすすめサイト toimg) * 単色、単純な画像の場合:png形式(webpにするとむしろサイズが大きくなる)
その他
- 背景透過画像
- ダークモード、ライトモード両方で見やすい色
がおすすめです。
2. 画像をweb上にアップロードする
よく分からなければ emojito からのアップロードで問題ないです。
普段使っている画像アップロード先があるならそれでも構いません。
気になる方はアップロード先を適宜選んでください。既に投稿されたカスタム絵文字の画像に対して
- 削除も差し替えもできない → emojito など
- 削除できるが差し替えはできない → Gyazo、nostrcheck.meなど
- 削除も差し替えもできる → GitHub 、セルフホスティングなど
これらは既にNostr上に投稿されたカスタム絵文字の画像を後から変更できるかどうかを指します。
どの方法でも新しく使われるカスタム絵文字を変更することは可能です。
同一のカスタム絵文字セットに同一のショートコードで別の画像を登録する形で対応できます。3. 絵文字セットに登録する
emojito から登録します。
右上のアイコン → + New emoji set から新規の絵文字セットを作成できます。


① 絵文字セット名を入力
基本的にカスタム絵文字はカスタム絵文字セットを作り、ひとまとまりにして登録します。
一度作った絵文字セットに後から絵文字を追加することもできます。
② 画像をアップロードまたは画像URLを入力
emojitoから画像をアップロードする場合、ファイル名に日本語などの2バイト文字が含まれているとアップロードがエラーになるようです。
その場合はファイル名を適当な英数字などに変更してください。
③ 絵文字のショートコードを入力
ショートコードは絵文字を呼び出す時に使用する場合があります。
他のカスタム絵文字と被っても問題ありませんが選択時に複数表示されて支障が出る可能性があります。
他と被りにくく長くなりすぎないショートコードが良いかもしれません。
ショートコードに使えるのは半角の英数字とアンダーバーのみです。
④ 追加
Add を押してもまだ作成完了にはなりません。

一度に絵文字を複数登録できます。
最後に右上の Save を押すと作成完了です。

画面が切り替わるので、右側の Options から Bookmark を選択するとそのカスタム絵文字セットを自分で使えるようになります。
既存の絵文字セットを編集するには Options から Edit を選択します。
以上です。
仕様
-
@ fe32298e:20516265
2024-12-16 20:59:13
Today I learned how to install NVapi to monitor my GPUs in Home Assistant.
NVApi is a lightweight API designed for monitoring NVIDIA GPU utilization and enabling automated power management. It provides real-time GPU metrics, supports integration with tools like Home Assistant, and offers flexible power management and PCIe link speed management based on workload and thermal conditions.
- GPU Utilization Monitoring: Utilization, memory usage, temperature, fan speed, and power consumption.
- Automated Power Limiting: Adjusts power limits dynamically based on temperature thresholds and total power caps, configurable per GPU or globally.
- Cross-GPU Coordination: Total power budget applies across multiple GPUs in the same system.
- PCIe Link Speed Management: Controls minimum and maximum PCIe link speeds with idle thresholds for power optimization.
- Home Assistant Integration: Uses the built-in RESTful platform and template sensors.
Getting the Data
sudo apt install golang-go git clone https://github.com/sammcj/NVApi.git cd NVapi go run main.go -port 9999 -rate 1 curl http://localhost:9999/gpuResponse for a single GPU:
[ { "index": 0, "name": "NVIDIA GeForce RTX 4090", "gpu_utilisation": 0, "memory_utilisation": 0, "power_watts": 16, "power_limit_watts": 450, "memory_total_gb": 23.99, "memory_used_gb": 0.46, "memory_free_gb": 23.52, "memory_usage_percent": 2, "temperature": 38, "processes": [], "pcie_link_state": "not managed" } ]Response for multiple GPUs:
[ { "index": 0, "name": "NVIDIA GeForce RTX 3090", "gpu_utilisation": 0, "memory_utilisation": 0, "power_watts": 14, "power_limit_watts": 350, "memory_total_gb": 24, "memory_used_gb": 0.43, "memory_free_gb": 23.57, "memory_usage_percent": 2, "temperature": 36, "processes": [], "pcie_link_state": "not managed" }, { "index": 1, "name": "NVIDIA RTX A4000", "gpu_utilisation": 0, "memory_utilisation": 0, "power_watts": 10, "power_limit_watts": 140, "memory_total_gb": 15.99, "memory_used_gb": 0.56, "memory_free_gb": 15.43, "memory_usage_percent": 3, "temperature": 41, "processes": [], "pcie_link_state": "not managed" } ]Start at Boot
Create
/etc/systemd/system/nvapi.service:``` [Unit] Description=Run NVapi After=network.target
[Service] Type=simple Environment="GOPATH=/home/ansible/go" WorkingDirectory=/home/ansible/NVapi ExecStart=/usr/bin/go run main.go -port 9999 -rate 1 Restart=always User=ansible
Environment="GPU_TEMP_CHECK_INTERVAL=5"
Environment="GPU_TOTAL_POWER_CAP=400"
Environment="GPU_0_LOW_TEMP=40"
Environment="GPU_0_MEDIUM_TEMP=70"
Environment="GPU_0_LOW_TEMP_LIMIT=135"
Environment="GPU_0_MEDIUM_TEMP_LIMIT=120"
Environment="GPU_0_HIGH_TEMP_LIMIT=100"
Environment="GPU_1_LOW_TEMP=45"
Environment="GPU_1_MEDIUM_TEMP=75"
Environment="GPU_1_LOW_TEMP_LIMIT=140"
Environment="GPU_1_MEDIUM_TEMP_LIMIT=125"
Environment="GPU_1_HIGH_TEMP_LIMIT=110"
[Install] WantedBy=multi-user.target ```
Home Assistant
Add to Home Assistant
configuration.yamland restart HA (completely).For a single GPU, this works: ``` sensor: - platform: rest name: MYPC GPU Information resource: http://mypc:9999 method: GET headers: Content-Type: application/json value_template: "{{ value_json[0].index }}" json_attributes: - name - gpu_utilisation - memory_utilisation - power_watts - power_limit_watts - memory_total_gb - memory_used_gb - memory_free_gb - memory_usage_percent - temperature scan_interval: 1 # seconds
- platform: template sensors: mypc_gpu_0_gpu: friendly_name: "MYPC {{ state_attr('sensor.mypc_gpu_information', 'name') }} GPU" value_template: "{{ state_attr('sensor.mypc_gpu_information', 'gpu_utilisation') }}" unit_of_measurement: "%" mypc_gpu_0_memory: friendly_name: "MYPC {{ state_attr('sensor.mypc_gpu_information', 'name') }} Memory" value_template: "{{ state_attr('sensor.mypc_gpu_information', 'memory_utilisation') }}" unit_of_measurement: "%" mypc_gpu_0_power: friendly_name: "MYPC {{ state_attr('sensor.mypc_gpu_information', 'name') }} Power" value_template: "{{ state_attr('sensor.mypc_gpu_information', 'power_watts') }}" unit_of_measurement: "W" mypc_gpu_0_power_limit: friendly_name: "MYPC {{ state_attr('sensor.mypc_gpu_information', 'name') }} Power Limit" value_template: "{{ state_attr('sensor.mypc_gpu_information', 'power_limit_watts') }}" unit_of_measurement: "W" mypc_gpu_0_temperature: friendly_name: "MYPC {{ state_attr('sensor.mypc_gpu_information', 'name') }} Temperature" value_template: "{{ state_attr('sensor.mypc_gpu_information', 'temperature') }}" unit_of_measurement: "°C" ```
For multiple GPUs: ``` rest: scan_interval: 1 resource: http://mypc:9999 sensor: - name: "MYPC GPU0 Information" value_template: "{{ value_json[0].index }}" json_attributes_path: "$.0" json_attributes: - name - gpu_utilisation - memory_utilisation - power_watts - power_limit_watts - memory_total_gb - memory_used_gb - memory_free_gb - memory_usage_percent - temperature - name: "MYPC GPU1 Information" value_template: "{{ value_json[1].index }}" json_attributes_path: "$.1" json_attributes: - name - gpu_utilisation - memory_utilisation - power_watts - power_limit_watts - memory_total_gb - memory_used_gb - memory_free_gb - memory_usage_percent - temperature
-
platform: template sensors: mypc_gpu_0_gpu: friendly_name: "MYPC GPU0 GPU" value_template: "{{ state_attr('sensor.mypc_gpu0_information', 'gpu_utilisation') }}" unit_of_measurement: "%" mypc_gpu_0_memory: friendly_name: "MYPC GPU0 Memory" value_template: "{{ state_attr('sensor.mypc_gpu0_information', 'memory_utilisation') }}" unit_of_measurement: "%" mypc_gpu_0_power: friendly_name: "MYPC GPU0 Power" value_template: "{{ state_attr('sensor.mypc_gpu0_information', 'power_watts') }}" unit_of_measurement: "W" mypc_gpu_0_power_limit: friendly_name: "MYPC GPU0 Power Limit" value_template: "{{ state_attr('sensor.mypc_gpu0_information', 'power_limit_watts') }}" unit_of_measurement: "W" mypc_gpu_0_temperature: friendly_name: "MYPC GPU0 Temperature" value_template: "{{ state_attr('sensor.mypc_gpu0_information', 'temperature') }}" unit_of_measurement: "C"
-
platform: template sensors: mypc_gpu_1_gpu: friendly_name: "MYPC GPU1 GPU" value_template: "{{ state_attr('sensor.mypc_gpu1_information', 'gpu_utilisation') }}" unit_of_measurement: "%" mypc_gpu_1_memory: friendly_name: "MYPC GPU1 Memory" value_template: "{{ state_attr('sensor.mypc_gpu1_information', 'memory_utilisation') }}" unit_of_measurement: "%" mypc_gpu_1_power: friendly_name: "MYPC GPU1 Power" value_template: "{{ state_attr('sensor.mypc_gpu1_information', 'power_watts') }}" unit_of_measurement: "W" mypc_gpu_1_power_limit: friendly_name: "MYPC GPU1 Power Limit" value_template: "{{ state_attr('sensor.mypc_gpu1_information', 'power_limit_watts') }}" unit_of_measurement: "W" mypc_gpu_1_temperature: friendly_name: "MYPC GPU1 Temperature" value_template: "{{ state_attr('sensor.mypc_gpu1_information', 'temperature') }}" unit_of_measurement: "C"
```
Basic entity card:
type: entities entities: - entity: sensor.mypc_gpu_0_gpu secondary_info: last-updated - entity: sensor.mypc_gpu_0_memory secondary_info: last-updated - entity: sensor.mypc_gpu_0_power secondary_info: last-updated - entity: sensor.mypc_gpu_0_power_limit secondary_info: last-updated - entity: sensor.mypc_gpu_0_temperature secondary_info: last-updatedAnsible Role
```
-
name: install go become: true package: name: golang-go state: present
-
name: git clone git: repo: "https://github.com/sammcj/NVApi.git" dest: "/home/ansible/NVapi" update: yes force: true
go run main.go -port 9999 -rate 1
-
name: install systemd service become: true copy: src: nvapi.service dest: /etc/systemd/system/nvapi.service
-
name: Reload systemd daemons, enable, and restart nvapi become: true systemd: name: nvapi daemon_reload: yes enabled: yes state: restarted ```
-
@ 6e64b83c:94102ee8
2025-05-05 16:50:13
Nostr-static is a powerful static site generator that transforms long-form Nostr content into beautiful, standalone websites. It makes your content accessible to everyone, even those not using Nostr clients. For more information check out my previous blog post How to Create a Blog Out of Nostr Long-Form Articles
What's New in Version 0.7?
RSS and Atom Feeds
Version 0.7 brings comprehensive feed support with both RSS and Atom formats. The system automatically generates feeds for your main content, individual profiles, and tag-specific pages. These feeds are seamlessly integrated into your site's header, making them easily discoverable by feed readers and content aggregators.
This feature bridges the gap between Nostr and traditional web publishing, allowing your content to reach readers who prefer feed readers or automated content distribution systems.
Smart Content Discovery
The new tag discovery system enhances your readers' experience by automatically finding and recommending relevant articles from the Nostr network. It works by:
- Analyzing the tags in your articles
- Fetching popular articles from Nostr that share these tags
- Using configurable weights to rank these articles based on:
- Engagement metrics (reactions, reposts, replies)
- Zap statistics (amount, unique zappers, average zap size)
- Content quality signals (report penalties)
This creates a dynamic "Recommended Articles" section that helps readers discover more content they might be interested in, all while staying within the Nostr ecosystem.
See the new features yourself by visiting our demo at: https://blog.nostrize.me
-
@ 6868de52:42418e63
2025-05-05 16:39:44
自分が僕のことをなんで否定するのかよくわかんない 自分のことを高く評価してる。周囲の理解に努力してない けど、いつも気にしてる 自分の限界に気づくのが怖い? 周りに理解されないことに価値を見出し、意図的に理解されないようにしてるんじゃないのか 周りに影響され、自分は変わっていくんです 変わらないもの。変わっちゃいけないもの。 変わっちゃいけないものは、学問への尊敬。これが生きる目的だってこと。 変わらないものは、美少女への嗜好、世界の全てへの優しさ、屁理屈の論理が好きなこと。 で、理解されたいのか。されるべきなのか。 されるべきとは?あーそうだよ、されたいしされるべきなんだ! そっか、じゃあ理解したいのか。するべきなのか。 するべきだよ。ネットワーク的にも、心理的にも。 したくは、ないかな。その決定権は常に僕の手元にほしい。 関われる限界を知ることになるから。 自分のことは知らなくてもいい。制御できればいい。愛してるし。 でもこうやって心情を整理してるんだけどね。まー限界はありますよ。
-
@ 5ffa0470:9c3e760a
2025-05-05 16:17:19
-
@ 90c656ff:9383fd4e
2025-05-05 15:30:26
In recent years, Bitcoin has often been compared to gold, earning the nickname “digital gold.” This comparison arises because both forms of value share key characteristics, such as scarcity, durability, and global acceptance. However, Bitcoin also represents a technological innovation that redefines the concept of money and investment, standing out as a modern and efficient alternative to physical gold.
One of the main reasons Bitcoin is compared to gold is its programmed scarcity. While gold is a naturally limited resource whose supply depends on mining, Bitcoin has a maximum cap of 21 million units, defined in its code. This cap protects Bitcoin from inflation, unlike traditional currencies that can be created without limit by central banks.
This scarcity gives Bitcoin lasting value, similar to gold, as the limited supply helps preserve purchasing power over time. As demand for Bitcoin grows, its reduced availability reinforces its role as a store of value.
Another feature that brings Bitcoin closer to gold is durability. While gold is resistant to corrosion and can be stored for centuries, Bitcoin is a digital asset protected by advanced cryptography and stored on the blockchain. An immutable and decentralized ledger.
Moreover, Bitcoin is far easier to transport than gold. Moving physical gold involves high costs and security risks, making transport particularly difficult for international transactions. Bitcoin, on the other hand, can be sent digitally anywhere in the world in minutes, with low fees and no intermediaries. This technological advantage makes Bitcoin more effective in a globalized and digital world.
Security is another trait that Bitcoin and gold share. Gold is difficult to counterfeit, making it a reliable store of value. Similarly, Bitcoin uses cryptographic protocols that ensure secure transactions and protect against fraud.
In addition, all Bitcoin transactions are recorded on the blockchain, offering a level of transparency that physical gold does not provide. Anyone can review transactions on the network, increasing trust and traceability.
Historically, gold has been used as a hedge against inflation and economic crises. During times of instability, investors turn to gold as a way to preserve their wealth. Bitcoin is emerging as a digital alternative with the same purpose.
In countries with high inflation or political instability, Bitcoin has been used as a safeguard against the devaluation of local currencies. Its decentralized nature prevents governments from directly confiscating or controlling the asset, providing greater financial freedom to users.
Despite its similarities with gold, Bitcoin still faces challenges. Its volatility is much higher, which can cause short-term uncertainty. However, many experts argue that this volatility is typical of new assets and tends to decrease over time as adoption grows and the market matures.
Another challenge is regulation. While gold is globally recognized as a financial asset, Bitcoin still faces resistance from governments and financial institutions, which seek ways to control and regulate it.
In summary, Bitcoin - often called "digital gold" - offers a new form of value that combines the best characteristics of gold with the efficiency and innovation of digital technology. Its programmed scarcity, cryptographic security, portability, and resistance to censorship make it a viable alternative for preserving wealth and conducting transactions in the modern world.
Despite its volatility, Bitcoin is establishing itself as both a store of value and a hedge against economic crises. As such, it represents not just an evolution of the financial system but also a symbol of the shift toward a decentralized and global digital economy.
Thank you very much for reading this far. I hope everything is well with you, and sending a big hug from your favorite Bitcoiner maximalist from Madeira. Long live freedom!
-
@ 6f6b50bb:a848e5a1
2024-12-15 15:09:52
Che cosa significherebbe trattare l'IA come uno strumento invece che come una persona?
Dall’avvio di ChatGPT, le esplorazioni in due direzioni hanno preso velocità.
La prima direzione riguarda le capacità tecniche. Quanto grande possiamo addestrare un modello? Quanto bene può rispondere alle domande del SAT? Con quanta efficienza possiamo distribuirlo?
La seconda direzione riguarda il design dell’interazione. Come comunichiamo con un modello? Come possiamo usarlo per un lavoro utile? Quale metafora usiamo per ragionare su di esso?
La prima direzione è ampiamente seguita e enormemente finanziata, e per una buona ragione: i progressi nelle capacità tecniche sono alla base di ogni possibile applicazione. Ma la seconda è altrettanto cruciale per il campo e ha enormi incognite. Siamo solo a pochi anni dall’inizio dell’era dei grandi modelli. Quali sono le probabilità che abbiamo già capito i modi migliori per usarli?
Propongo una nuova modalità di interazione, in cui i modelli svolgano il ruolo di applicazioni informatiche (ad esempio app per telefoni): fornendo un’interfaccia grafica, interpretando gli input degli utenti e aggiornando il loro stato. In questa modalità, invece di essere un “agente” che utilizza un computer per conto dell’essere umano, l’IA può fornire un ambiente informatico più ricco e potente che possiamo utilizzare.
Metafore per l’interazione
Al centro di un’interazione c’è una metafora che guida le aspettative di un utente su un sistema. I primi giorni dell’informatica hanno preso metafore come “scrivanie”, “macchine da scrivere”, “fogli di calcolo” e “lettere” e le hanno trasformate in equivalenti digitali, permettendo all’utente di ragionare sul loro comportamento. Puoi lasciare qualcosa sulla tua scrivania e tornare a prenderlo; hai bisogno di un indirizzo per inviare una lettera. Man mano che abbiamo sviluppato una conoscenza culturale di questi dispositivi, la necessità di queste particolari metafore è scomparsa, e con esse i design di interfaccia skeumorfici che le rafforzavano. Come un cestino o una matita, un computer è ora una metafora di se stesso.
La metafora dominante per i grandi modelli oggi è modello-come-persona. Questa è una metafora efficace perché le persone hanno capacità estese che conosciamo intuitivamente. Implica che possiamo avere una conversazione con un modello e porgli domande; che il modello possa collaborare con noi su un documento o un pezzo di codice; che possiamo assegnargli un compito da svolgere da solo e che tornerà quando sarà finito.
Tuttavia, trattare un modello come una persona limita profondamente il nostro modo di pensare all’interazione con esso. Le interazioni umane sono intrinsecamente lente e lineari, limitate dalla larghezza di banda e dalla natura a turni della comunicazione verbale. Come abbiamo tutti sperimentato, comunicare idee complesse in una conversazione è difficile e dispersivo. Quando vogliamo precisione, ci rivolgiamo invece a strumenti, utilizzando manipolazioni dirette e interfacce visive ad alta larghezza di banda per creare diagrammi, scrivere codice e progettare modelli CAD. Poiché concepiamo i modelli come persone, li utilizziamo attraverso conversazioni lente, anche se sono perfettamente in grado di accettare input diretti e rapidi e di produrre risultati visivi. Le metafore che utilizziamo limitano le esperienze che costruiamo, e la metafora modello-come-persona ci impedisce di esplorare il pieno potenziale dei grandi modelli.
Per molti casi d’uso, e specialmente per il lavoro produttivo, credo che il futuro risieda in un’altra metafora: modello-come-computer.
Usare un’IA come un computer
Sotto la metafora modello-come-computer, interagiremo con i grandi modelli seguendo le intuizioni che abbiamo sulle applicazioni informatiche (sia su desktop, tablet o telefono). Nota che ciò non significa che il modello sarà un’app tradizionale più di quanto il desktop di Windows fosse una scrivania letterale. “Applicazione informatica” sarà un modo per un modello di rappresentarsi a noi. Invece di agire come una persona, il modello agirà come un computer.
Agire come un computer significa produrre un’interfaccia grafica. Al posto del flusso lineare di testo in stile telescrivente fornito da ChatGPT, un sistema modello-come-computer genererà qualcosa che somiglia all’interfaccia di un’applicazione moderna: pulsanti, cursori, schede, immagini, grafici e tutto il resto. Questo affronta limitazioni chiave dell’interfaccia di chat standard modello-come-persona:
-
Scoperta. Un buon strumento suggerisce i suoi usi. Quando l’unica interfaccia è una casella di testo vuota, spetta all’utente capire cosa fare e comprendere i limiti del sistema. La barra laterale Modifica in Lightroom è un ottimo modo per imparare l’editing fotografico perché non si limita a dirti cosa può fare questa applicazione con una foto, ma cosa potresti voler fare. Allo stesso modo, un’interfaccia modello-come-computer per DALL-E potrebbe mostrare nuove possibilità per le tue generazioni di immagini.
-
Efficienza. La manipolazione diretta è più rapida che scrivere una richiesta a parole. Per continuare l’esempio di Lightroom, sarebbe impensabile modificare una foto dicendo a una persona quali cursori spostare e di quanto. Ci vorrebbe un giorno intero per chiedere un’esposizione leggermente più bassa e una vibranza leggermente più alta, solo per vedere come apparirebbe. Nella metafora modello-come-computer, il modello può creare strumenti che ti permettono di comunicare ciò che vuoi più efficientemente e quindi di fare le cose più rapidamente.
A differenza di un’app tradizionale, questa interfaccia grafica è generata dal modello su richiesta. Questo significa che ogni parte dell’interfaccia che vedi è rilevante per ciò che stai facendo in quel momento, inclusi i contenuti specifici del tuo lavoro. Significa anche che, se desideri un’interfaccia più ampia o diversa, puoi semplicemente richiederla. Potresti chiedere a DALL-E di produrre alcuni preset modificabili per le sue impostazioni ispirati da famosi artisti di schizzi. Quando clicchi sul preset Leonardo da Vinci, imposta i cursori per disegni prospettici altamente dettagliati in inchiostro nero. Se clicchi su Charles Schulz, seleziona fumetti tecnicolor 2D a basso dettaglio.
Una bicicletta della mente proteiforme
La metafora modello-come-persona ha una curiosa tendenza a creare distanza tra l’utente e il modello, rispecchiando il divario di comunicazione tra due persone che può essere ridotto ma mai completamente colmato. A causa della difficoltà e del costo di comunicare a parole, le persone tendono a suddividere i compiti tra loro in blocchi grandi e il più indipendenti possibile. Le interfacce modello-come-persona seguono questo schema: non vale la pena dire a un modello di aggiungere un return statement alla tua funzione quando è più veloce scriverlo da solo. Con il sovraccarico della comunicazione, i sistemi modello-come-persona sono più utili quando possono fare un intero blocco di lavoro da soli. Fanno le cose per te.
Questo contrasta con il modo in cui interagiamo con i computer o altri strumenti. Gli strumenti producono feedback visivi in tempo reale e sono controllati attraverso manipolazioni dirette. Hanno un overhead comunicativo così basso che non è necessario specificare un blocco di lavoro indipendente. Ha più senso mantenere l’umano nel loop e dirigere lo strumento momento per momento. Come stivali delle sette leghe, gli strumenti ti permettono di andare più lontano a ogni passo, ma sei ancora tu a fare il lavoro. Ti permettono di fare le cose più velocemente.
Considera il compito di costruire un sito web usando un grande modello. Con le interfacce di oggi, potresti trattare il modello come un appaltatore o un collaboratore. Cercheresti di scrivere a parole il più possibile su come vuoi che il sito appaia, cosa vuoi che dica e quali funzionalità vuoi che abbia. Il modello genererebbe una prima bozza, tu la eseguirai e poi fornirai un feedback. “Fai il logo un po’ più grande”, diresti, e “centra quella prima immagine principale”, e “deve esserci un pulsante di login nell’intestazione”. Per ottenere esattamente ciò che vuoi, invierai una lista molto lunga di richieste sempre più minuziose.
Un’interazione alternativa modello-come-computer sarebbe diversa: invece di costruire il sito web, il modello genererebbe un’interfaccia per te per costruirlo, dove ogni input dell’utente a quell’interfaccia interroga il grande modello sotto il cofano. Forse quando descrivi le tue necessità creerebbe un’interfaccia con una barra laterale e una finestra di anteprima. All’inizio la barra laterale contiene solo alcuni schizzi di layout che puoi scegliere come punto di partenza. Puoi cliccare su ciascuno di essi, e il modello scrive l’HTML per una pagina web usando quel layout e lo visualizza nella finestra di anteprima. Ora che hai una pagina su cui lavorare, la barra laterale guadagna opzioni aggiuntive che influenzano la pagina globalmente, come accoppiamenti di font e schemi di colore. L’anteprima funge da editor WYSIWYG, permettendoti di afferrare elementi e spostarli, modificarne i contenuti, ecc. A supportare tutto ciò è il modello, che vede queste azioni dell’utente e riscrive la pagina per corrispondere ai cambiamenti effettuati. Poiché il modello può generare un’interfaccia per aiutare te e lui a comunicare più efficientemente, puoi esercitare più controllo sul prodotto finale in meno tempo.
La metafora modello-come-computer ci incoraggia a pensare al modello come a uno strumento con cui interagire in tempo reale piuttosto che a un collaboratore a cui assegnare compiti. Invece di sostituire un tirocinante o un tutor, può essere una sorta di bicicletta proteiforme per la mente, una che è sempre costruita su misura esattamente per te e il terreno che intendi attraversare.
Un nuovo paradigma per l’informatica?
I modelli che possono generare interfacce su richiesta sono una frontiera completamente nuova nell’informatica. Potrebbero essere un paradigma del tutto nuovo, con il modo in cui cortocircuitano il modello di applicazione esistente. Dare agli utenti finali il potere di creare e modificare app al volo cambia fondamentalmente il modo in cui interagiamo con i computer. Al posto di una singola applicazione statica costruita da uno sviluppatore, un modello genererà un’applicazione su misura per l’utente e le sue esigenze immediate. Al posto della logica aziendale implementata nel codice, il modello interpreterà gli input dell’utente e aggiornerà l’interfaccia utente. È persino possibile che questo tipo di interfaccia generativa sostituisca completamente il sistema operativo, generando e gestendo interfacce e finestre al volo secondo necessità.
All’inizio, l’interfaccia generativa sarà un giocattolo, utile solo per l’esplorazione creativa e poche altre applicazioni di nicchia. Dopotutto, nessuno vorrebbe un’app di posta elettronica che occasionalmente invia email al tuo ex e mente sulla tua casella di posta. Ma gradualmente i modelli miglioreranno. Anche mentre si spingeranno ulteriormente nello spazio di esperienze completamente nuove, diventeranno lentamente abbastanza affidabili da essere utilizzati per un lavoro reale.
Piccoli pezzi di questo futuro esistono già. Anni fa Jonas Degrave ha dimostrato che ChatGPT poteva fare una buona simulazione di una riga di comando Linux. Allo stesso modo, websim.ai utilizza un LLM per generare siti web su richiesta mentre li navighi. Oasis, GameNGen e DIAMOND addestrano modelli video condizionati sull’azione su singoli videogiochi, permettendoti di giocare ad esempio a Doom dentro un grande modello. E Genie 2 genera videogiochi giocabili da prompt testuali. L’interfaccia generativa potrebbe ancora sembrare un’idea folle, ma non è così folle.
Ci sono enormi domande aperte su come apparirà tutto questo. Dove sarà inizialmente utile l’interfaccia generativa? Come condivideremo e distribuiremo le esperienze che creiamo collaborando con il modello, se esistono solo come contesto di un grande modello? Vorremmo davvero farlo? Quali nuovi tipi di esperienze saranno possibili? Come funzionerà tutto questo in pratica? I modelli genereranno interfacce come codice o produrranno direttamente pixel grezzi?
Non conosco ancora queste risposte. Dovremo sperimentare e scoprirlo!Che cosa significherebbe trattare l'IA come uno strumento invece che come una persona?
Dall’avvio di ChatGPT, le esplorazioni in due direzioni hanno preso velocità.
La prima direzione riguarda le capacità tecniche. Quanto grande possiamo addestrare un modello? Quanto bene può rispondere alle domande del SAT? Con quanta efficienza possiamo distribuirlo?
La seconda direzione riguarda il design dell’interazione. Come comunichiamo con un modello? Come possiamo usarlo per un lavoro utile? Quale metafora usiamo per ragionare su di esso?
La prima direzione è ampiamente seguita e enormemente finanziata, e per una buona ragione: i progressi nelle capacità tecniche sono alla base di ogni possibile applicazione. Ma la seconda è altrettanto cruciale per il campo e ha enormi incognite. Siamo solo a pochi anni dall’inizio dell’era dei grandi modelli. Quali sono le probabilità che abbiamo già capito i modi migliori per usarli?
Propongo una nuova modalità di interazione, in cui i modelli svolgano il ruolo di applicazioni informatiche (ad esempio app per telefoni): fornendo un’interfaccia grafica, interpretando gli input degli utenti e aggiornando il loro stato. In questa modalità, invece di essere un “agente” che utilizza un computer per conto dell’essere umano, l’IA può fornire un ambiente informatico più ricco e potente che possiamo utilizzare.
Metafore per l’interazione
Al centro di un’interazione c’è una metafora che guida le aspettative di un utente su un sistema. I primi giorni dell’informatica hanno preso metafore come “scrivanie”, “macchine da scrivere”, “fogli di calcolo” e “lettere” e le hanno trasformate in equivalenti digitali, permettendo all’utente di ragionare sul loro comportamento. Puoi lasciare qualcosa sulla tua scrivania e tornare a prenderlo; hai bisogno di un indirizzo per inviare una lettera. Man mano che abbiamo sviluppato una conoscenza culturale di questi dispositivi, la necessità di queste particolari metafore è scomparsa, e con esse i design di interfaccia skeumorfici che le rafforzavano. Come un cestino o una matita, un computer è ora una metafora di se stesso.
La metafora dominante per i grandi modelli oggi è modello-come-persona. Questa è una metafora efficace perché le persone hanno capacità estese che conosciamo intuitivamente. Implica che possiamo avere una conversazione con un modello e porgli domande; che il modello possa collaborare con noi su un documento o un pezzo di codice; che possiamo assegnargli un compito da svolgere da solo e che tornerà quando sarà finito.
Tuttavia, trattare un modello come una persona limita profondamente il nostro modo di pensare all’interazione con esso. Le interazioni umane sono intrinsecamente lente e lineari, limitate dalla larghezza di banda e dalla natura a turni della comunicazione verbale. Come abbiamo tutti sperimentato, comunicare idee complesse in una conversazione è difficile e dispersivo. Quando vogliamo precisione, ci rivolgiamo invece a strumenti, utilizzando manipolazioni dirette e interfacce visive ad alta larghezza di banda per creare diagrammi, scrivere codice e progettare modelli CAD. Poiché concepiamo i modelli come persone, li utilizziamo attraverso conversazioni lente, anche se sono perfettamente in grado di accettare input diretti e rapidi e di produrre risultati visivi. Le metafore che utilizziamo limitano le esperienze che costruiamo, e la metafora modello-come-persona ci impedisce di esplorare il pieno potenziale dei grandi modelli.
Per molti casi d’uso, e specialmente per il lavoro produttivo, credo che il futuro risieda in un’altra metafora: modello-come-computer.
Usare un’IA come un computer
Sotto la metafora modello-come-computer, interagiremo con i grandi modelli seguendo le intuizioni che abbiamo sulle applicazioni informatiche (sia su desktop, tablet o telefono). Nota che ciò non significa che il modello sarà un’app tradizionale più di quanto il desktop di Windows fosse una scrivania letterale. “Applicazione informatica” sarà un modo per un modello di rappresentarsi a noi. Invece di agire come una persona, il modello agirà come un computer.
Agire come un computer significa produrre un’interfaccia grafica. Al posto del flusso lineare di testo in stile telescrivente fornito da ChatGPT, un sistema modello-come-computer genererà qualcosa che somiglia all’interfaccia di un’applicazione moderna: pulsanti, cursori, schede, immagini, grafici e tutto il resto. Questo affronta limitazioni chiave dell’interfaccia di chat standard modello-come-persona:
Scoperta. Un buon strumento suggerisce i suoi usi. Quando l’unica interfaccia è una casella di testo vuota, spetta all’utente capire cosa fare e comprendere i limiti del sistema. La barra laterale Modifica in Lightroom è un ottimo modo per imparare l’editing fotografico perché non si limita a dirti cosa può fare questa applicazione con una foto, ma cosa potresti voler fare. Allo stesso modo, un’interfaccia modello-come-computer per DALL-E potrebbe mostrare nuove possibilità per le tue generazioni di immagini.
Efficienza. La manipolazione diretta è più rapida che scrivere una richiesta a parole. Per continuare l’esempio di Lightroom, sarebbe impensabile modificare una foto dicendo a una persona quali cursori spostare e di quanto. Ci vorrebbe un giorno intero per chiedere un’esposizione leggermente più bassa e una vibranza leggermente più alta, solo per vedere come apparirebbe. Nella metafora modello-come-computer, il modello può creare strumenti che ti permettono di comunicare ciò che vuoi più efficientemente e quindi di fare le cose più rapidamente.
A differenza di un’app tradizionale, questa interfaccia grafica è generata dal modello su richiesta. Questo significa che ogni parte dell’interfaccia che vedi è rilevante per ciò che stai facendo in quel momento, inclusi i contenuti specifici del tuo lavoro. Significa anche che, se desideri un’interfaccia più ampia o diversa, puoi semplicemente richiederla. Potresti chiedere a DALL-E di produrre alcuni preset modificabili per le sue impostazioni ispirati da famosi artisti di schizzi. Quando clicchi sul preset Leonardo da Vinci, imposta i cursori per disegni prospettici altamente dettagliati in inchiostro nero. Se clicchi su Charles Schulz, seleziona fumetti tecnicolor 2D a basso dettaglio.
Una bicicletta della mente proteiforme
La metafora modello-come-persona ha una curiosa tendenza a creare distanza tra l’utente e il modello, rispecchiando il divario di comunicazione tra due persone che può essere ridotto ma mai completamente colmato. A causa della difficoltà e del costo di comunicare a parole, le persone tendono a suddividere i compiti tra loro in blocchi grandi e il più indipendenti possibile. Le interfacce modello-come-persona seguono questo schema: non vale la pena dire a un modello di aggiungere un return statement alla tua funzione quando è più veloce scriverlo da solo. Con il sovraccarico della comunicazione, i sistemi modello-come-persona sono più utili quando possono fare un intero blocco di lavoro da soli. Fanno le cose per te.
Questo contrasta con il modo in cui interagiamo con i computer o altri strumenti. Gli strumenti producono feedback visivi in tempo reale e sono controllati attraverso manipolazioni dirette. Hanno un overhead comunicativo così basso che non è necessario specificare un blocco di lavoro indipendente. Ha più senso mantenere l’umano nel loop e dirigere lo strumento momento per momento. Come stivali delle sette leghe, gli strumenti ti permettono di andare più lontano a ogni passo, ma sei ancora tu a fare il lavoro. Ti permettono di fare le cose più velocemente.
Considera il compito di costruire un sito web usando un grande modello. Con le interfacce di oggi, potresti trattare il modello come un appaltatore o un collaboratore. Cercheresti di scrivere a parole il più possibile su come vuoi che il sito appaia, cosa vuoi che dica e quali funzionalità vuoi che abbia. Il modello genererebbe una prima bozza, tu la eseguirai e poi fornirai un feedback. “Fai il logo un po’ più grande”, diresti, e “centra quella prima immagine principale”, e “deve esserci un pulsante di login nell’intestazione”. Per ottenere esattamente ciò che vuoi, invierai una lista molto lunga di richieste sempre più minuziose.
Un’interazione alternativa modello-come-computer sarebbe diversa: invece di costruire il sito web, il modello genererebbe un’interfaccia per te per costruirlo, dove ogni input dell’utente a quell’interfaccia interroga il grande modello sotto il cofano. Forse quando descrivi le tue necessità creerebbe un’interfaccia con una barra laterale e una finestra di anteprima. All’inizio la barra laterale contiene solo alcuni schizzi di layout che puoi scegliere come punto di partenza. Puoi cliccare su ciascuno di essi, e il modello scrive l’HTML per una pagina web usando quel layout e lo visualizza nella finestra di anteprima. Ora che hai una pagina su cui lavorare, la barra laterale guadagna opzioni aggiuntive che influenzano la pagina globalmente, come accoppiamenti di font e schemi di colore. L’anteprima funge da editor WYSIWYG, permettendoti di afferrare elementi e spostarli, modificarne i contenuti, ecc. A supportare tutto ciò è il modello, che vede queste azioni dell’utente e riscrive la pagina per corrispondere ai cambiamenti effettuati. Poiché il modello può generare un’interfaccia per aiutare te e lui a comunicare più efficientemente, puoi esercitare più controllo sul prodotto finale in meno tempo.
La metafora modello-come-computer ci incoraggia a pensare al modello come a uno strumento con cui interagire in tempo reale piuttosto che a un collaboratore a cui assegnare compiti. Invece di sostituire un tirocinante o un tutor, può essere una sorta di bicicletta proteiforme per la mente, una che è sempre costruita su misura esattamente per te e il terreno che intendi attraversare.
Un nuovo paradigma per l’informatica?
I modelli che possono generare interfacce su richiesta sono una frontiera completamente nuova nell’informatica. Potrebbero essere un paradigma del tutto nuovo, con il modo in cui cortocircuitano il modello di applicazione esistente. Dare agli utenti finali il potere di creare e modificare app al volo cambia fondamentalmente il modo in cui interagiamo con i computer. Al posto di una singola applicazione statica costruita da uno sviluppatore, un modello genererà un’applicazione su misura per l’utente e le sue esigenze immediate. Al posto della logica aziendale implementata nel codice, il modello interpreterà gli input dell’utente e aggiornerà l’interfaccia utente. È persino possibile che questo tipo di interfaccia generativa sostituisca completamente il sistema operativo, generando e gestendo interfacce e finestre al volo secondo necessità.
All’inizio, l’interfaccia generativa sarà un giocattolo, utile solo per l’esplorazione creativa e poche altre applicazioni di nicchia. Dopotutto, nessuno vorrebbe un’app di posta elettronica che occasionalmente invia email al tuo ex e mente sulla tua casella di posta. Ma gradualmente i modelli miglioreranno. Anche mentre si spingeranno ulteriormente nello spazio di esperienze completamente nuove, diventeranno lentamente abbastanza affidabili da essere utilizzati per un lavoro reale.
Piccoli pezzi di questo futuro esistono già. Anni fa Jonas Degrave ha dimostrato che ChatGPT poteva fare una buona simulazione di una riga di comando Linux. Allo stesso modo, websim.ai utilizza un LLM per generare siti web su richiesta mentre li navighi. Oasis, GameNGen e DIAMOND addestrano modelli video condizionati sull’azione su singoli videogiochi, permettendoti di giocare ad esempio a Doom dentro un grande modello. E Genie 2 genera videogiochi giocabili da prompt testuali. L’interfaccia generativa potrebbe ancora sembrare un’idea folle, ma non è così folle.
Ci sono enormi domande aperte su come apparirà tutto questo. Dove sarà inizialmente utile l’interfaccia generativa? Come condivideremo e distribuiremo le esperienze che creiamo collaborando con il modello, se esistono solo come contesto di un grande modello? Vorremmo davvero farlo? Quali nuovi tipi di esperienze saranno possibili? Come funzionerà tutto questo in pratica? I modelli genereranno interfacce come codice o produrranno direttamente pixel grezzi?
Non conosco ancora queste risposte. Dovremo sperimentare e scoprirlo!
Tradotto da:\ https://willwhitney.com/computing-inside-ai.htmlhttps://willwhitney.com/computing-inside-ai.html
-
-
@ 8125b911:a8400883
2025-04-25 07:02:35
In Nostr, all data is stored as events. Decentralization is achieved by storing events on multiple relays, with signatures proving the ownership of these events. However, if you truly want to own your events, you should run your own relay to store them. Otherwise, if the relays you use fail or intentionally delete your events, you'll lose them forever.
For most people, running a relay is complex and costly. To solve this issue, I developed nostr-relay-tray, a relay that can be easily run on a personal computer and accessed over the internet.
Project URL: https://github.com/CodyTseng/nostr-relay-tray
This article will guide you through using nostr-relay-tray to run your own relay.
Download
Download the installation package for your operating system from the GitHub Release Page.
| Operating System | File Format | | --------------------- | ---------------------------------- | | Windows |
nostr-relay-tray.Setup.x.x.x.exe| | macOS (Apple Silicon) |nostr-relay-tray-x.x.x-arm64.dmg| | macOS (Intel) |nostr-relay-tray-x.x.x.dmg| | Linux | You should know which one to use |Installation
Since this app isn’t signed, you may encounter some obstacles during installation. Once installed, an ostrich icon will appear in the status bar. Click on the ostrich icon, and you'll see a menu where you can click the "Dashboard" option to open the relay's control panel for further configuration.

macOS Users:
- On first launch, go to "System Preferences > Security & Privacy" and click "Open Anyway."
- If you encounter a "damaged" message, run the following command in the terminal to remove the restrictions:
bash sudo xattr -rd com.apple.quarantine /Applications/nostr-relay-tray.appWindows Users:
- On the security warning screen, click "More Info > Run Anyway."
Connecting
By default, nostr-relay-tray is only accessible locally through
ws://localhost:4869/, which makes it quite limited. Therefore, we need to expose it to the internet.In the control panel, click the "Proxy" tab and toggle the switch. You will then receive a "Public address" that you can use to access your relay from anywhere. It's that simple.
Next, add this address to your relay list and position it as high as possible in the list. Most clients prioritize connecting to relays that appear at the top of the list, and relays lower in the list are often ignored.

Restrictions
Next, we need to set up some restrictions to prevent the relay from storing events that are irrelevant to you and wasting storage space. nostr-relay-tray allows for flexible and fine-grained configuration of which events to accept, but some of this is more complex and will not be covered here. If you're interested, you can explore this further later.
For now, I'll introduce a simple and effective strategy: WoT (Web of Trust). You can enable this feature in the "WoT & PoW" tab. Before enabling, you'll need to input your pubkey.
There's another important parameter,
Depth, which represents the relationship depth between you and others. Someone you follow has a depth of 1, someone they follow has a depth of 2, and so on.- Setting this parameter to 0 means your relay will only accept your own events.
- Setting it to 1 means your relay will accept events from you and the people you follow.
- Setting it to 2 means your relay will accept events from you, the people you follow, and the people they follow.
Currently, the maximum value for this parameter is 2.

Conclusion
You've now successfully run your own relay and set a simple restriction to prevent it from storing irrelevant events.
If you encounter any issues during use, feel free to submit an issue on GitHub, and I'll respond as soon as possible.
Not your relay, not your events.
-
@ dd664d5e:5633d319
2024-12-14 15:25:56

Christmas season hasn't actually started, yet, in Roman #Catholic Germany. We're in Advent until the evening of the 24th of December, at which point Christmas begins (with the Nativity, at Vespers), and continues on for 40 days until Mariä Lichtmess (Presentation of Christ in the temple) on February 2nd.
It's 40 days because that's how long the post-partum isolation is, before women were allowed back into the temple (after a ritual cleansing).

That is the day when we put away all of the Christmas decorations and bless the candles, for the next year. (Hence, the British name "Candlemas".) It used to also be when household staff would get paid their cash wages and could change employer. And it is the day precisely in the middle of winter.

Between Christmas Eve and Candlemas are many celebrations, concluding with the Twelfth Night called Epiphany or Theophany. This is the day some Orthodox celebrate Christ's baptism, so traditions rotate around blessing of waters.

The Monday after Epiphany was the start of the farming season, in England, so that Sunday all of the ploughs were blessed, but the practice has largely died out.

Our local tradition is for the altar servers to dress as the wise men and go door-to-door, carrying their star and looking for the Baby Jesus, who is rumored to be lying in a manger.

They collect cash gifts and chocolates, along the way, and leave the generous their powerful blessing, written over the door. The famous 20 * C + M + B * 25 blessing means "Christus mansionem benedicat" (Christ, bless this house), or "Caspar, Melchior, Balthasar" (the names of the three kings), depending upon who you ask.
They offer the cash to the Baby Jesus (once they find him in the church's Nativity scene), but eat the sweets, themselves. It is one of the biggest donation-collections in the world, called the "Sternsinger" (star singers). The money goes from the German children, to help children elsewhere, and they collect around €45 million in cash and coins, every year.

As an interesting aside:
The American "groundhog day", derives from one of the old farmers' sayings about Candlemas, brought over by the Pennsylvania Dutch. It says, that if the badger comes out of his hole and sees his shadow, then it'll remain cold for 4 more weeks. When they moved to the USA, they didn't have any badgers around, so they switched to groundhogs, as they also hibernate in winter.
-
@ 40b9c85f:5e61b451
2025-04-24 15:27:02
Introduction
Data Vending Machines (DVMs) have emerged as a crucial component of the Nostr ecosystem, offering specialized computational services to clients across the network. As defined in NIP-90, DVMs operate on an apparently simple principle: "data in, data out." They provide a marketplace for data processing where users request specific jobs (like text translation, content recommendation, or AI text generation)
While DVMs have gained significant traction, the current specification faces challenges that hinder widespread adoption and consistent implementation. This article explores some ideas on how we can apply the reflection pattern, a well established approach in RPC systems, to address these challenges and improve the DVM ecosystem's clarity, consistency, and usability.
The Current State of DVMs: Challenges and Limitations
The NIP-90 specification provides a broad framework for DVMs, but this flexibility has led to several issues:
1. Inconsistent Implementation
As noted by hzrd149 in "DVMs were a mistake" every DVM implementation tends to expect inputs in slightly different formats, even while ostensibly following the same specification. For example, a translation request DVM might expect an event ID in one particular format, while an LLM service could expect a "prompt" input that's not even specified in NIP-90.
2. Fragmented Specifications
The DVM specification reserves a range of event kinds (5000-6000), each meant for different types of computational jobs. While creating sub-specifications for each job type is being explored as a possible solution for clarity, in a decentralized and permissionless landscape like Nostr, relying solely on specification enforcement won't be effective for creating a healthy ecosystem. A more comprehensible approach is needed that works with, rather than against, the open nature of the protocol.
3. Ambiguous API Interfaces
There's no standardized way for clients to discover what parameters a specific DVM accepts, which are required versus optional, or what output format to expect. This creates uncertainty and forces developers to rely on documentation outside the protocol itself, if such documentation exists at all.
The Reflection Pattern: A Solution from RPC Systems
The reflection pattern in RPC systems offers a compelling solution to many of these challenges. At its core, reflection enables servers to provide metadata about their available services, methods, and data types at runtime, allowing clients to dynamically discover and interact with the server's API.
In established RPC frameworks like gRPC, reflection serves as a self-describing mechanism where services expose their interface definitions and requirements. In MCP reflection is used to expose the capabilities of the server, such as tools, resources, and prompts. Clients can learn about available capabilities without prior knowledge, and systems can adapt to changes without requiring rebuilds or redeployments. This standardized introspection creates a unified way to query service metadata, making tools like
grpcurlpossible without requiring precompiled stubs.How Reflection Could Transform the DVM Specification
By incorporating reflection principles into the DVM specification, we could create a more coherent and predictable ecosystem. DVMs already implement some sort of reflection through the use of 'nip90params', which allow clients to discover some parameters, constraints, and features of the DVMs, such as whether they accept encryption, nutzaps, etc. However, this approach could be expanded to provide more comprehensive self-description capabilities.
1. Defined Lifecycle Phases
Similar to the Model Context Protocol (MCP), DVMs could benefit from a clear lifecycle consisting of an initialization phase and an operation phase. During initialization, the client and DVM would negotiate capabilities and exchange metadata, with the DVM providing a JSON schema containing its input requirements. nip-89 (or other) announcements can be used to bootstrap the discovery and negotiation process by providing the input schema directly. Then, during the operation phase, the client would interact with the DVM according to the negotiated schema and parameters.
2. Schema-Based Interactions
Rather than relying on rigid specifications for each job type, DVMs could self-advertise their schemas. This would allow clients to understand which parameters are required versus optional, what type validation should occur for inputs, what output formats to expect, and what payment flows are supported. By internalizing the input schema of the DVMs they wish to consume, clients gain clarity on how to interact effectively.
3. Capability Negotiation
Capability negotiation would enable DVMs to advertise their supported features, such as encryption methods, payment options, or specialized functionalities. This would allow clients to adjust their interaction approach based on the specific capabilities of each DVM they encounter.
Implementation Approach
While building DVMCP, I realized that the RPC reflection pattern used there could be beneficial for constructing DVMs in general. Since DVMs already follow an RPC style for their operation, and reflection is a natural extension of this approach, it could significantly enhance and clarify the DVM specification.
A reflection enhanced DVM protocol could work as follows: 1. Discovery: Clients discover DVMs through existing NIP-89 application handlers, input schemas could also be advertised in nip-89 announcements, making the second step unnecessary. 2. Schema Request: Clients request the DVM's input schema for the specific job type they're interested in 3. Validation: Clients validate their request against the provided schema before submission 4. Operation: The job proceeds through the standard NIP-90 flow, but with clearer expectations on both sides
Parallels with Other Protocols
This approach has proven successful in other contexts. The Model Context Protocol (MCP) implements a similar lifecycle with capability negotiation during initialization, allowing any client to communicate with any server as long as they adhere to the base protocol. MCP and DVM protocols share fundamental similarities, both aim to expose and consume computational resources through a JSON-RPC-like interface, albeit with specific differences.
gRPC's reflection service similarly allows clients to discover service definitions at runtime, enabling generic tools to work with any gRPC service without prior knowledge. In the REST API world, OpenAPI/Swagger specifications document interfaces in a way that makes them discoverable and testable.
DVMs would benefit from adopting these patterns while maintaining the decentralized, permissionless nature of Nostr.
Conclusion
I am not attempting to rewrite the DVM specification; rather, explore some ideas that could help the ecosystem improve incrementally, reducing fragmentation and making the ecosystem more comprehensible. By allowing DVMs to self describe their interfaces, we could maintain the flexibility that makes Nostr powerful while providing the structure needed for interoperability.
For developers building DVM clients or libraries, this approach would simplify consumption by providing clear expectations about inputs and outputs. For DVM operators, it would establish a standard way to communicate their service's requirements without relying on external documentation.
I am currently developing DVMCP following these patterns. Of course, DVMs and MCP servers have different details; MCP includes capabilities such as tools, resources, and prompts on the server side, as well as 'roots' and 'sampling' on the client side, creating a bidirectional way to consume capabilities. In contrast, DVMs typically function similarly to MCP tools, where you call a DVM with an input and receive an output, with each job type representing a different categorization of the work performed.
Without further ado, I hope this article has provided some insight into the potential benefits of applying the reflection pattern to the DVM specification.
-
@ e6817453:b0ac3c39
2024-12-07 15:06:43
I started a long series of articles about how to model different types of knowledge graphs in the relational model, which makes on-device memory models for AI agents possible.
We model-directed graphs
Also, graphs of entities
We even model hypergraphs
Last time, we discussed why classical triple and simple knowledge graphs are insufficient for AI agents and complex memory, especially in the domain of time-aware or multi-model knowledge.
So why do we need metagraphs, and what kind of challenge could they help us to solve?
- complex and nested event and temporal context and temporal relations as edges
- multi-mode and multilingual knowledge
- human-like memory for AI agents that has multiple contexts and relations between knowledge in neuron-like networks
MetaGraphs
A meta graph is a concept that extends the idea of a graph by allowing edges to become graphs. Meta Edges connect a set of nodes, which could also be subgraphs. So, at some level, node and edge are pretty similar in properties but act in different roles in a different context.
Also, in some cases, edges could be referenced as nodes.
This approach enables the representation of more complex relationships and hierarchies than a traditional graph structure allows. Let’s break down each term to understand better metagraphs and how they differ from hypergraphs and graphs.Graph Basics
- A standard graph has a set of nodes (or vertices) and edges (connections between nodes).
- Edges are generally simple and typically represent a binary relationship between two nodes.
- For instance, an edge in a social network graph might indicate a “friend” relationship between two people (nodes).
Hypergraph
- A hypergraph extends the concept of an edge by allowing it to connect any number of nodes, not just two.
- Each connection, called a hyperedge, can link multiple nodes.
- This feature allows hypergraphs to model more complex relationships involving multiple entities simultaneously. For example, a hyperedge in a hypergraph could represent a project team, connecting all team members in a single relation.
- Despite its flexibility, a hypergraph doesn’t capture hierarchical or nested structures; it only generalizes the number of connections in an edge.
Metagraph
- A metagraph allows the edges to be graphs themselves. This means each edge can contain its own nodes and edges, creating nested, hierarchical structures.
- In a meta graph, an edge could represent a relationship defined by a graph. For instance, a meta graph could represent a network of organizations where each organization’s structure (departments and connections) is represented by its own internal graph and treated as an edge in the larger meta graph.
- This recursive structure allows metagraphs to model complex data with multiple layers of abstraction. They can capture multi-node relationships (as in hypergraphs) and detailed, structured information about each relationship.
Named Graphs and Graph of Graphs
As you can notice, the structure of a metagraph is quite complex and could be complex to model in relational and classical RDF setups. It could create a challenge of luck of tools and software solutions for your problem.
If you need to model nested graphs, you could use a much simpler model of Named graphs, which could take you quite far.
The concept of the named graph came from the RDF community, which needed to group some sets of triples. In this way, you form subgraphs inside an existing graph. You could refer to the subgraph as a regular node. This setup simplifies complex graphs, introduces hierarchies, and even adds features and properties of hypergraphs while keeping a directed nature.
It looks complex, but it is not so hard to model it with a slight modification of a directed graph.
So, the node could host graphs inside. Let's reflect this fact with a location for a node. If a node belongs to a main graph, we could set the location to null or introduce a main node . it is up to you
Nodes could have edges to nodes in different subgraphs. This structure allows any kind of nesting graphs. Edges stay location-free
Meta Graphs in Relational Model
Let’s try to make several attempts to model different meta-graphs with some constraints.
Directed Metagraph where edges are not used as nodes and could not contain subgraphs
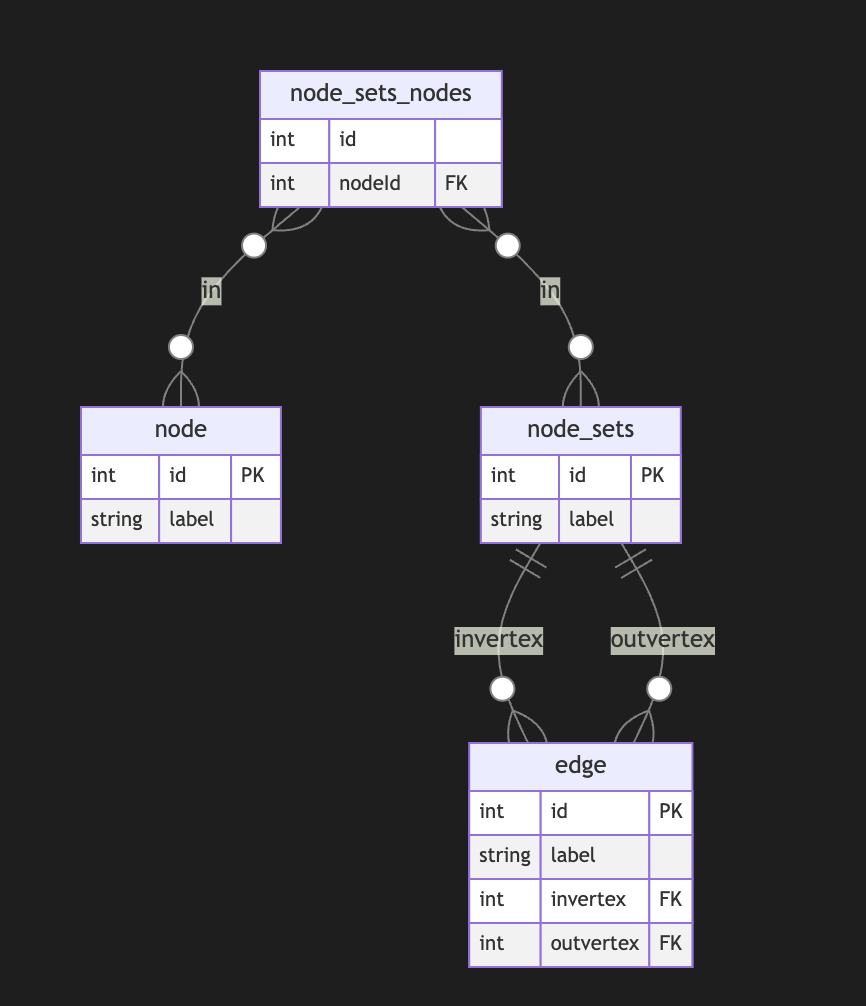
In this case, the edge always points to two sets of nodes. This introduces an overhead of creating a node set for a single node. In this model, we can model empty node sets that could require application-level constraints to prevent such cases.
Directed Metagraph where edges are not used as nodes and could contain subgraphs
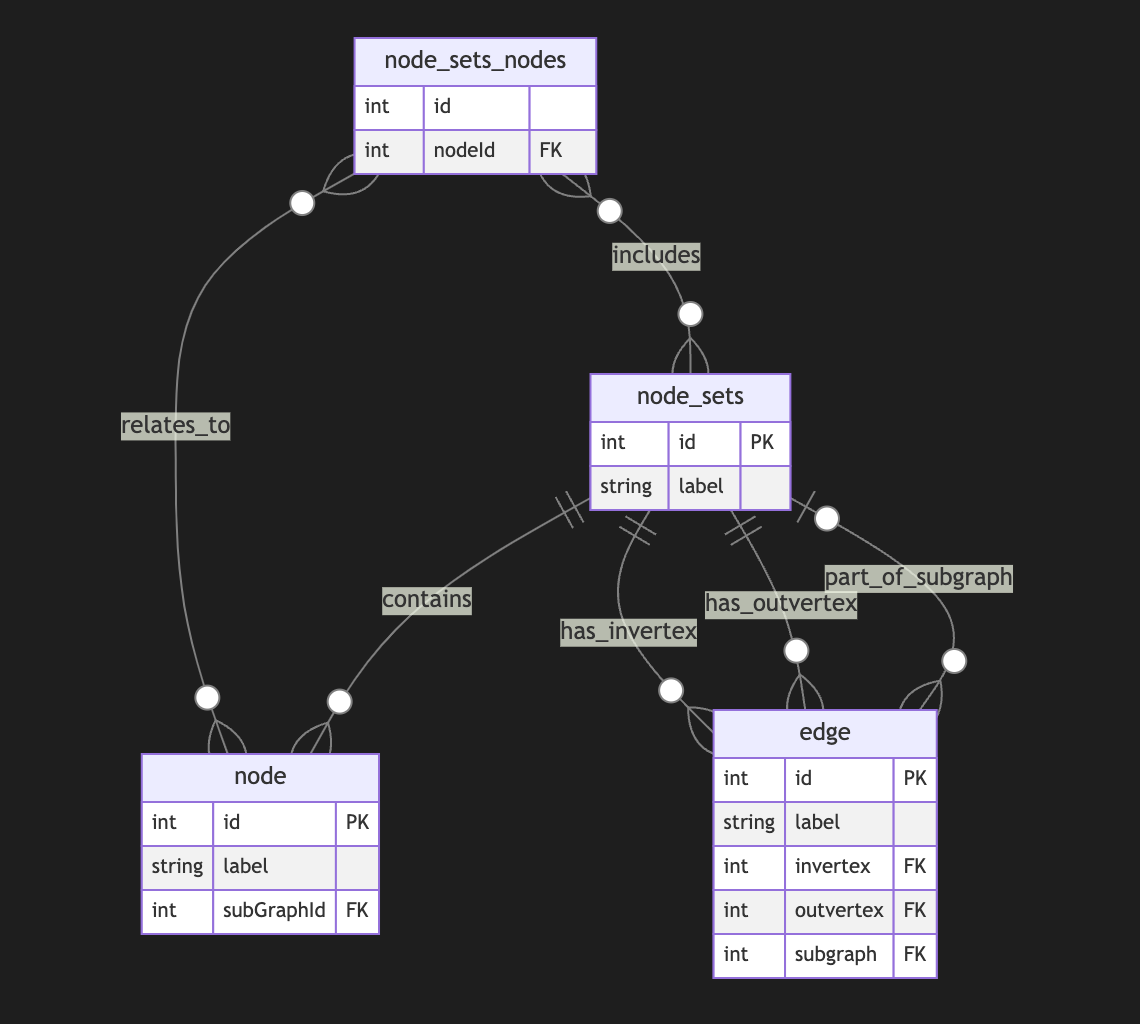
Adding a node set that could model a subgraph located in an edge is easy but could be separate from in-vertex or out-vert.
I also do not see a direct need to include subgraphs to a node, as we could just use a node set interchangeably, but it still could be a case.Directed Metagraph where edges are used as nodes and could contain subgraphs
As you can notice, we operate all the time with node sets. We could simply allow the extension node set to elements set that include node and edge IDs, but in this case, we need to use uuid or any other strategy to differentiate node IDs from edge IDs. In this case, we have a collision of ephemeral edges or ephemeral nodes when we want to change the role and purpose of the node as an edge or vice versa.
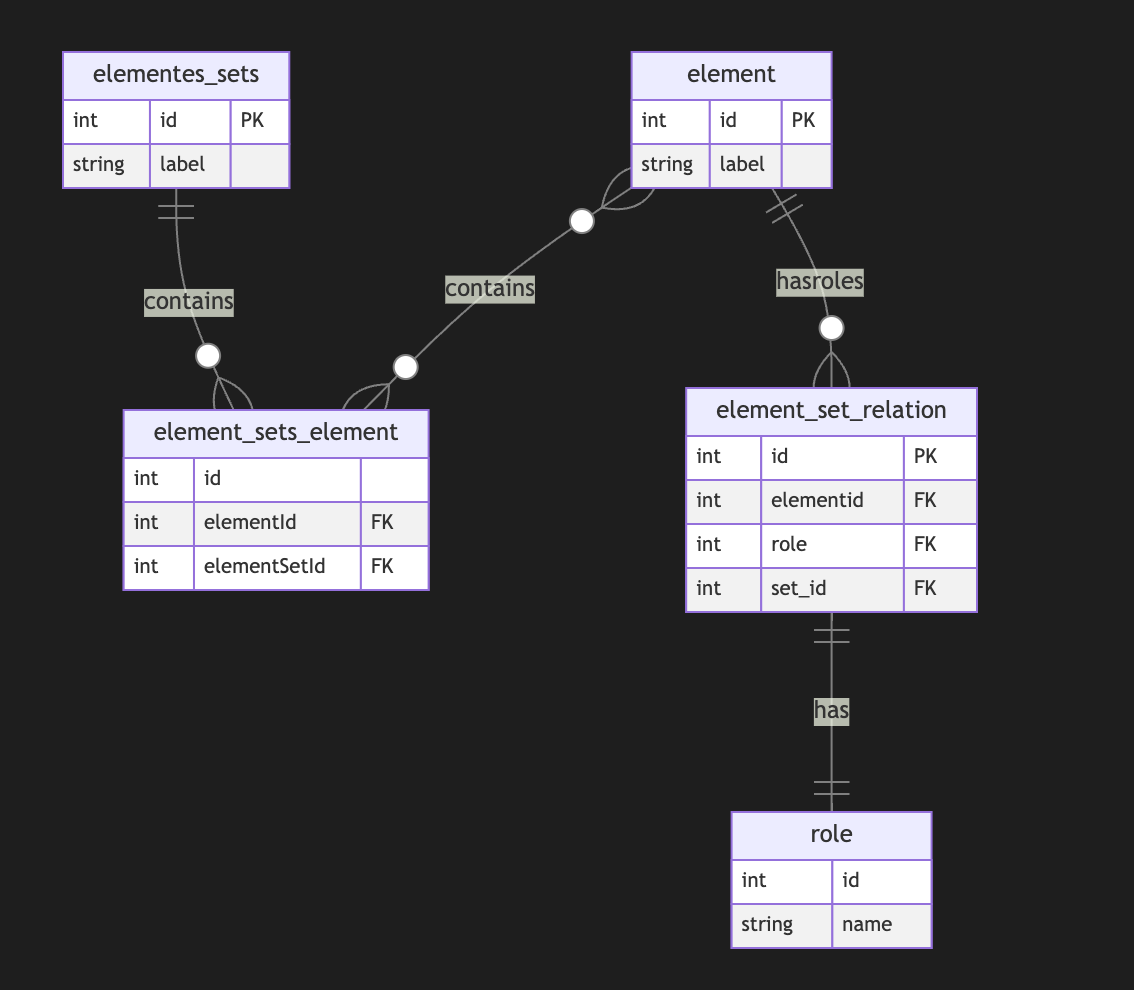
A full-scale metagraph model is way too complex for a relational database.
So we need a better model.Now, we have more flexibility but loose structural constraints. We cannot show that the element should have one vertex, one vertex, or both. This type of constraint has been moved to the application level. Also, the crucial question is about query and retrieval needs.
Any meta-graph model should be more focused on domain and needs and should be used in raw form. We did it for a pure theoretical purpose. -
@ 8cda1daa:e9e5bdd8
2025-04-24 10:20:13
Bitcoin cracked the code for money. Now it's time to rebuild everything else.
What about identity, trust, and collaboration? What about the systems that define how we live, create, and connect?
Bitcoin gave us a blueprint to separate money from the state. But the state still owns most of your digital life. It's time for something more radical.
Welcome to the Atomic Economy - not just a technology stack, but a civil engineering project for the digital age. A complete re-architecture of society, from the individual outward.
The Problem: We Live in Digital Captivity
Let's be blunt: the modern internet is hostile to human freedom.
You don't own your identity. You don't control your data. You don't decide what you see.
Big Tech and state institutions dominate your digital life with one goal: control.
- Poisoned algorithms dictate your emotions and behavior.
- Censorship hides truth and silences dissent.
- Walled gardens lock you into systems you can't escape.
- Extractive platforms monetize your attention and creativity - without your consent.
This isn't innovation. It's digital colonization.
A Vision for Sovereign Society
The Atomic Economy proposes a new design for society - one where: - Individuals own their identity, data, and value. - Trust is contextual, not imposed. - Communities are voluntary, not manufactured by feeds. - Markets are free, not fenced. - Collaboration is peer-to-peer, not platform-mediated.
It's not a political revolution. It's a technological and social reset based on first principles: self-sovereignty, mutualism, and credible exit.
So, What Is the Atomic Economy?
The Atomic Economy is a decentralized digital society where people - not platforms - coordinate identity, trust, and value.
It's built on open protocols, real software, and the ethos of Bitcoin. It's not about abstraction - it's about architecture.
Core Principles: - Self-Sovereignty: Your keys. Your data. Your rules. - Mutual Consensus: Interactions are voluntary and trust-based. - Credible Exit: Leave any system, with your data and identity intact. - Programmable Trust: Trust is explicit, contextual, and revocable. - Circular Economies: Value flows directly between individuals - no middlemen.
The Tech Stack Behind the Vision
The Atomic Economy isn't just theory. It's a layered system with real tools:
1. Payments & Settlement
- Bitcoin & Lightning: The foundation - sound, censorship-resistant money.
- Paykit: Modular payments and settlement flows.
- Atomicity: A peer-to-peer mutual credit protocol for programmable trust and IOUs.
2. Discovery & Matching
- Pubky Core: Decentralized identity and discovery using PKARR and the DHT.
- Pubky Nexus: Indexing for a user-controlled internet.
- Semantic Social Graph: Discovery through social tagging - you are the algorithm.
3. Application Layer
- Bitkit: A self-custodial Bitcoin and Lightning wallet.
- Pubky App: Tag, publish, trade, and interact - on your terms.
- Blocktank: Liquidity services for Lightning and circular economies.
- Pubky Ring: Key-based access control and identity syncing.
These tools don't just integrate - they stack. You build trust, exchange value, and form communities with no centralized gatekeepers.
The Human Impact
This isn't about software. It's about freedom.
- Empowered Individuals: Control your own narrative, value, and destiny.
- Voluntary Communities: Build trust on shared values, not enforced norms.
- Economic Freedom: Trade without permission, borders, or middlemen.
- Creative Renaissance: Innovation and art flourish in open, censorship-resistant systems.
The Atomic Economy doesn't just fix the web. It frees the web.
Why Bitcoiners Should Care
If you believe in Bitcoin, you already believe in the Atomic Economy - you just haven't seen the full map yet.
- It extends Bitcoin's principles beyond money: into identity, trust, coordination.
- It defends freedom where Bitcoin leaves off: in content, community, and commerce.
- It offers a credible exit from every centralized system you still rely on.
- It's how we win - not just economically, but culturally and socially.
This isn't "web3." This isn't another layer of grift. It's the Bitcoin future - fully realized.
Join the Atomic Revolution
- If you're a builder: fork the code, remix the ideas, expand the protocols.
- If you're a user: adopt Bitkit, use Pubky, exit the digital plantation.
- If you're an advocate: share the vision. Help people imagine a free society again.
Bitcoin promised a revolution. The Atomic Economy delivers it.
Let's reclaim society, one key at a time.
Learn more and build with us at Synonym.to.
-
@ e6817453:b0ac3c39
2024-12-07 15:03:06
Hey folks! Today, let’s dive into the intriguing world of neurosymbolic approaches, retrieval-augmented generation (RAG), and personal knowledge graphs (PKGs). Together, these concepts hold much potential for bringing true reasoning capabilities to large language models (LLMs). So, let’s break down how symbolic logic, knowledge graphs, and modern AI can come together to empower future AI systems to reason like humans.
The Neurosymbolic Approach: What It Means ?
Neurosymbolic AI combines two historically separate streams of artificial intelligence: symbolic reasoning and neural networks. Symbolic AI uses formal logic to process knowledge, similar to how we might solve problems or deduce information. On the other hand, neural networks, like those underlying GPT-4, focus on learning patterns from vast amounts of data — they are probabilistic statistical models that excel in generating human-like language and recognizing patterns but often lack deep, explicit reasoning.
While GPT-4 can produce impressive text, it’s still not very effective at reasoning in a truly logical way. Its foundation, transformers, allows it to excel in pattern recognition, but the models struggle with reasoning because, at their core, they rely on statistical probabilities rather than true symbolic logic. This is where neurosymbolic methods and knowledge graphs come in.
Symbolic Calculations and the Early Vision of AI
If we take a step back to the 1950s, the vision for artificial intelligence was very different. Early AI research was all about symbolic reasoning — where computers could perform logical calculations to derive new knowledge from a given set of rules and facts. Languages like Lisp emerged to support this vision, enabling programs to represent data and code as interchangeable symbols. Lisp was designed to be homoiconic, meaning it treated code as manipulatable data, making it capable of self-modification — a huge leap towards AI systems that could, in theory, understand and modify their own operations.
Lisp: The Earlier AI-Language
Lisp, short for “LISt Processor,” was developed by John McCarthy in 1958, and it became the cornerstone of early AI research. Lisp’s power lay in its flexibility and its use of symbolic expressions, which allowed developers to create programs that could manipulate symbols in ways that were very close to human reasoning. One of the most groundbreaking features of Lisp was its ability to treat code as data, known as homoiconicity, which meant that Lisp programs could introspect and transform themselves dynamically. This ability to adapt and modify its own structure gave Lisp an edge in tasks that required a form of self-awareness, which was key in the early days of AI when researchers were exploring what it meant for machines to “think.”
Lisp was not just a programming language—it represented the vision for artificial intelligence, where machines could evolve their understanding and rewrite their own programming. This idea formed the conceptual basis for many of the self-modifying and adaptive algorithms that are still explored today in AI research. Despite its decline in mainstream programming, Lisp’s influence can still be seen in the concepts used in modern machine learning and symbolic AI approaches.
Prolog: Formal Logic and Deductive Reasoning
In the 1970s, Prolog was developed—a language focused on formal logic and deductive reasoning. Unlike Lisp, based on lambda calculus, Prolog operates on formal logic rules, allowing it to perform deductive reasoning and solve logical puzzles. This made Prolog an ideal candidate for expert systems that needed to follow a sequence of logical steps, such as medical diagnostics or strategic planning.
Prolog, like Lisp, allowed symbols to be represented, understood, and used in calculations, creating another homoiconic language that allows reasoning. Prolog’s strength lies in its rule-based structure, which is well-suited for tasks that require logical inference and backtracking. These features made it a powerful tool for expert systems and AI research in the 1970s and 1980s.
The language is declarative in nature, meaning that you define the problem, and Prolog figures out how to solve it. By using formal logic and setting constraints, Prolog systems can derive conclusions from known facts, making it highly effective in fields requiring explicit logical frameworks, such as legal reasoning, diagnostics, and natural language understanding. These symbolic approaches were later overshadowed during the AI winter — but the ideas never really disappeared. They just evolved.
Solvers and Their Role in Complementing LLMs
One of the most powerful features of Prolog and similar logic-based systems is their use of solvers. Solvers are mechanisms that can take a set of rules and constraints and automatically find solutions that satisfy these conditions. This capability is incredibly useful when combined with LLMs, which excel at generating human-like language but need help with logical consistency and structured reasoning.
For instance, imagine a scenario where an LLM needs to answer a question involving multiple logical steps or a complex query that requires deducing facts from various pieces of information. In this case, a solver can derive valid conclusions based on a given set of logical rules, providing structured answers that the LLM can then articulate in natural language. This allows the LLM to retrieve information and ensure the logical integrity of its responses, leading to much more robust answers.
Solvers are also ideal for handling constraint satisfaction problems — situations where multiple conditions must be met simultaneously. In practical applications, this could include scheduling tasks, generating optimal recommendations, or even diagnosing issues where a set of symptoms must match possible diagnoses. Prolog’s solver capabilities and LLM’s natural language processing power can make these systems highly effective at providing intelligent, rule-compliant responses that traditional LLMs would struggle to produce alone.
By integrating neurosymbolic methods that utilize solvers, we can provide LLMs with a form of deductive reasoning that is missing from pure deep-learning approaches. This combination has the potential to significantly improve the quality of outputs for use-cases that require explicit, structured problem-solving, from legal queries to scientific research and beyond. Solvers give LLMs the backbone they need to not just generate answers but to do so in a way that respects logical rigor and complex constraints.
Graph of Rules for Enhanced Reasoning
Another powerful concept that complements LLMs is using a graph of rules. A graph of rules is essentially a structured collection of logical rules that interconnect in a network-like structure, defining how various entities and their relationships interact. This structured network allows for complex reasoning and information retrieval, as well as the ability to model intricate relationships between different pieces of knowledge.
In a graph of rules, each node represents a rule, and the edges define relationships between those rules — such as dependencies or causal links. This structure can be used to enhance LLM capabilities by providing them with a formal set of rules and relationships to follow, which improves logical consistency and reasoning depth. When an LLM encounters a problem or a question that requires multiple logical steps, it can traverse this graph of rules to generate an answer that is not only linguistically fluent but also logically robust.
For example, in a healthcare application, a graph of rules might include nodes for medical symptoms, possible diagnoses, and recommended treatments. When an LLM receives a query regarding a patient’s symptoms, it can use the graph to traverse from symptoms to potential diagnoses and then to treatment options, ensuring that the response is coherent and medically sound. The graph of rules guides reasoning, enabling LLMs to handle complex, multi-step questions that involve chains of reasoning, rather than merely generating surface-level responses.
Graphs of rules also enable modular reasoning, where different sets of rules can be activated based on the context or the type of question being asked. This modularity is crucial for creating adaptive AI systems that can apply specific sets of logical frameworks to distinct problem domains, thereby greatly enhancing their versatility. The combination of neural fluency with rule-based structure gives LLMs the ability to conduct more advanced reasoning, ultimately making them more reliable and effective in domains where accuracy and logical consistency are critical.
By implementing a graph of rules, LLMs are empowered to perform deductive reasoning alongside their generative capabilities, creating responses that are not only compelling but also logically aligned with the structured knowledge available in the system. This further enhances their potential applications in fields such as law, engineering, finance, and scientific research — domains where logical consistency is as important as linguistic coherence.
Enhancing LLMs with Symbolic Reasoning
Now, with LLMs like GPT-4 being mainstream, there is an emerging need to add real reasoning capabilities to them. This is where neurosymbolic approaches shine. Instead of pitting neural networks against symbolic reasoning, these methods combine the best of both worlds. The neural aspect provides language fluency and recognition of complex patterns, while the symbolic side offers real reasoning power through formal logic and rule-based frameworks.
Personal Knowledge Graphs (PKGs) come into play here as well. Knowledge graphs are data structures that encode entities and their relationships — they’re essentially semantic networks that allow for structured information retrieval. When integrated with neurosymbolic approaches, LLMs can use these graphs to answer questions in a far more contextual and precise way. By retrieving relevant information from a knowledge graph, they can ground their responses in well-defined relationships, thus improving both the relevance and the logical consistency of their answers.
Imagine combining an LLM with a graph of rules that allow it to reason through the relationships encoded in a personal knowledge graph. This could involve using deductive databases to form a sophisticated way to represent and reason with symbolic data — essentially constructing a powerful hybrid system that uses LLM capabilities for language fluency and rule-based logic for structured problem-solving.
My Research on Deductive Databases and Knowledge Graphs
I recently did some research on modeling knowledge graphs using deductive databases, such as DataLog — which can be thought of as a limited, data-oriented version of Prolog. What I’ve found is that it’s possible to use formal logic to model knowledge graphs, ontologies, and complex relationships elegantly as rules in a deductive system. Unlike classical RDF or traditional ontology-based models, which sometimes struggle with complex or evolving relationships, a deductive approach is more flexible and can easily support dynamic rules and reasoning.
Prolog and similar logic-driven frameworks can complement LLMs by handling the parts of reasoning where explicit rule-following is required. LLMs can benefit from these rule-based systems for tasks like entity recognition, logical inferences, and constructing or traversing knowledge graphs. We can even create a graph of rules that governs how relationships are formed or how logical deductions can be performed.
The future is really about creating an AI that is capable of both deep contextual understanding (using the powerful generative capacity of LLMs) and true reasoning (through symbolic systems and knowledge graphs). With the neurosymbolic approach, these AIs could be equipped not just to generate information but to explain their reasoning, form logical conclusions, and even improve their own understanding over time — getting us a step closer to true artificial general intelligence.
Why It Matters for LLM Employment
Using neurosymbolic RAG (retrieval-augmented generation) in conjunction with personal knowledge graphs could revolutionize how LLMs work in real-world applications. Imagine an LLM that understands not just language but also the relationships between different concepts — one that can navigate, reason, and explain complex knowledge domains by actively engaging with a personalized set of facts and rules.
This could lead to practical applications in areas like healthcare, finance, legal reasoning, or even personal productivity — where LLMs can help users solve complex problems logically, providing relevant information and well-justified reasoning paths. The combination of neural fluency with symbolic accuracy and deductive power is precisely the bridge we need to move beyond purely predictive AI to truly intelligent systems.
Let's explore these ideas further if you’re as fascinated by this as I am. Feel free to reach out, follow my YouTube channel, or check out some articles I’ll link below. And if you’re working on anything in this field, I’d love to collaborate!
Until next time, folks. Stay curious, and keep pushing the boundaries of AI!
-
@ 6e64b83c:94102ee8
2025-04-23 20:23:34
How to Run Your Own Nostr Relay on Android with Cloudflare Domain
Prerequisites
- Install Citrine on your Android device:
- Visit https://github.com/greenart7c3/Citrine/releases
- Download the latest release using:
- zap.store
- Obtainium
- F-Droid
- Or download the APK directly
-
Note: You may need to enable "Install from Unknown Sources" in your Android settings
-
Domain Requirements:
- Purchase a domain if you don't have one
-
Transfer your domain to Cloudflare if it's not already there (for free SSL certificates and cloudflared support)
-
Tools to use:
- nak (the nostr army knife):
- Download from https://github.com/fiatjaf/nak/releases
- Installation steps:
-
For Linux/macOS: ```bash # Download the appropriate version for your system wget https://github.com/fiatjaf/nak/releases/latest/download/nak-linux-amd64 # for Linux # or wget https://github.com/fiatjaf/nak/releases/latest/download/nak-darwin-amd64 # for macOS
# Make it executable chmod +x nak-*
# Move to a directory in your PATH sudo mv nak-* /usr/local/bin/nak
- For Windows:batch # Download the Windows version curl -L -o nak.exe https://github.com/fiatjaf/nak/releases/latest/download/nak-windows-amd64.exe# Move to a directory in your PATH (e.g., C:\Windows) move nak.exe C:\Windows\nak.exe
- Verify installation:bash nak --version ```
Setting Up Citrine
- Open the Citrine app
- Start the server
- You'll see it running on
ws://127.0.0.1:4869(local network only) - Go to settings and paste your npub into "Accept events signed by" inbox and press the + button. This prevents others from publishing events to your personal relay.
Installing Required Tools
- Install Termux from Google Play Store
- Open Termux and run:
bash pkg update && pkg install wget wget https://github.com/cloudflare/cloudflared/releases/latest/download/cloudflared-linux-arm64.deb dpkg -i cloudflared-linux-arm64.debCloudflare Authentication
- Run the authentication command:
bash cloudflared tunnel login - Follow the instructions:
- Copy the provided URL to your browser
- Log in to your Cloudflare account
- If the URL expires, copy it again after logging in
Creating the Tunnel
- Create a new tunnel:
bash cloudflared tunnel create <TUNNEL_NAME> - Choose any name you prefer for your tunnel
-
Copy the tunnel ID after creating the tunnel
-
Create and configure the tunnel config:
bash touch ~/.cloudflared/config.yml nano ~/.cloudflared/config.yml -
Add this configuration (replace the placeholders with your values): ```yaml tunnel:
credentials-file: /data/data/com.termux/files/home/.cloudflared/ .json ingress: - hostname: nostr.yourdomain.com service: ws://localhost:4869
- service: http_status:404 ```
- Note: In nano editor:
CTRL+Oand Enter to saveCTRL+Xto exit
-
Note: Check the credentials file path in the logs
-
Validate your configuration:
bash cloudflared tunnel validate -
Start the tunnel:
bash cloudflared tunnel run my-relay
Preventing Android from Killing the Tunnel
Run these commands to maintain tunnel stability:
bash date && apt install termux-tools && termux-setup-storage && termux-wake-lock echo "nameserver 1.1.1.1" > $PREFIX/etc/resolv.confTip: You can open multiple Termux sessions by swiping from the left edge of the screen while keeping your tunnel process running.
Updating Your Outbox Model Relays
Once your relay is running and accessible via your domain, you'll want to update your relay list in the Nostr network. This ensures other clients know about your relay and can connect to it.
Decoding npub (Public Key)
Private keys (nsec) and public keys (npub) are encoded in bech32 format, which includes: - A prefix (like nsec1, npub1 etc.) - The encoded data - A checksum
This format makes keys: - Easy to distinguish - Hard to copy incorrectly
However, most tools require these keys in hexadecimal (hex) format.
To decode an npub string to its hex format:
bash nak decode nostr:npub1dejts0qlva8mqzjlrxqkc2tmvs2t7elszky5upxaf3jha9qs9m5q605uc4Change it with your own npub.
bash { "pubkey": "6e64b83c1f674fb00a5f19816c297b6414bf67f015894e04dd4c657e94102ee8" }Copy the pubkey value in quotes.
Create a kind 10002 event with your relay list:
- Include your new relay with write permissions
- Include other relays you want to read from and write to, omit 3rd parameter to make it both read and write
Example format:
json { "kind": 10002, "tags": [ ["r", "wss://your-relay-domain.com", "write"], ["r", "wss://eden.nostr.land/"], ["r", "wss://nos.lol/"], ["r", "wss://nostr.bitcoiner.social/"], ["r", "wss://nostr.mom/"], ["r", "wss://relay.primal.net/"], ["r", "wss://nostr.wine/", "read"], ["r", "wss://relay.damus.io/"], ["r", "wss://relay.nostr.band/"], ["r", "wss://relay.snort.social/"] ], "content": "" }Save it to a file called
event.jsonNote: Add or remove any relays you want. To check your existing 10002 relays: - Visit https://nostr.band/?q=by%3Anpub1dejts0qlva8mqzjlrxqkc2tmvs2t7elszky5upxaf3jha9qs9m5q605uc4+++kind%3A10002 - nostr.band is an indexing service, it probably has your relay list. - Replace
npub1xxxin the URL with your own npub - Click "VIEW JSON" from the menu to see the raw event - Or use thenaktool if you know the relaysbash nak req -k 10002 -a <your-pubkey> wss://relay1.com wss://relay2.comReplace `<your-pubkey>` with your public key in hex format (you can get it using `nak decode <your-npub>`)- Sign and publish the event:
- Use a Nostr client that supports kind 10002 events
- Or use the
nakcommand-line tool:bash nak event --sec ncryptsec1... wss://relay1.com wss://relay2.com $(cat event.json)
Important Security Notes: 1. Never share your nsec (private key) with anyone 2. Consider using NIP-49 encrypted keys for better security 3. Never paste your nsec or private key into the terminal. The command will be saved in your shell history, exposing your private key. To clear the command history: - For bash: use
history -c- For zsh: usefc -Wto write history to file, thenfc -pto read it back - Or manually edit your shell history file (e.g.,~/.zsh_historyor~/.bash_history) 4. if you're usingzsh, usefc -pto prevent the next command from being saved to history 5. Or temporarily disable history before running sensitive commands:bash unset HISTFILE nak key encrypt ... set HISTFILEHow to securely create NIP-49 encypted private key
```bash
Read your private key (input will be hidden)
read -s SECRET
Read your password (input will be hidden)
read -s PASSWORD
encrypt command
echo "$SECRET" | nak key encrypt "$PASSWORD"
copy and paste the ncryptsec1 text from the output
read -s ENCRYPTED nak key decrypt "$ENCRYPTED"
clear variables from memory
unset SECRET PASSWORD ENCRYPTED ```
On a Windows command line, to read from stdin and use the variables in
nakcommands, you can use a combination ofset /pto read input and then use those variables in your command. Here's an example:```bash @echo off set /p "SECRET=Enter your secret key: " set /p "PASSWORD=Enter your password: "
echo %SECRET%| nak key encrypt %PASSWORD%
:: Clear the sensitive variables set "SECRET=" set "PASSWORD=" ```
If your key starts with
ncryptsec1, thenaktool will securely prompt you for a password when using the--secparameter, unless the command is used with a pipe< >or|.bash nak event --sec ncryptsec1... wss://relay1.com wss://relay2.com $(cat event.json)- Verify the event was published:
- Check if your relay list is visible on other relays
-
Use the
naktool to fetch your kind 10002 events:bash nak req -k 10002 -a <your-pubkey> wss://relay1.com wss://relay2.com -
Testing your relay:
- Try connecting to your relay using different Nostr clients
- Verify you can both read from and write to your relay
- Check if events are being properly stored and retrieved
- Tip: Use multiple Nostr clients to test different aspects of your relay
Note: If anyone in the community has a more efficient method of doing things like updating outbox relays, please share your insights in the comments. Your expertise would be greatly appreciated!
-
@ 7460b7fd:4fc4e74b
2025-05-05 14:49:02
PR 32359:取消 OP_RETURN 字节限制提案深入分析
提案概述及代码变更内容
提案背景与意图:比特币核心当前对交易中的 OP_RETURN 输出(数据载体输出)有严格限制:默认最多允许单个 OP_RETURN 输出,且其
scriptPubKey大小不超过 83 字节(约80字节数据加上OP_RETURN和Pushdata前缀)groups.google.com。这一标准规则旨在轻度阻碍链上存储大量任意数据,鼓励将非金融数据以“更无害”的方式存入链上(比如用OP_RETURN而非可花费的UTXO输出)groups.google.com。然而随着时间推移,这一限制并未阻止用户将数据写入区块链,反而促使开发者设计各种变通方案绕过限制。例如,近期 Citrea Clementine 协议(闪电网络相关项目)因为OP_RETURN容量不足,而改用不可花费的Taproot输出来存储所需数据groups.google.com。这样的做法导致大量小额UTXO留存在UTXO集,对全节点造成负担,被视为比使用OP_RETURN更有害的副作用github.com。基于此背景,Bitcoin Core 开发者 Peter Todd(与 Chaincode 实验室的 Antoine Poinsot 等人)提出了 PR #32359,意在解除OP_RETURN的字节大小限制,以消除这种“适得其反”的限制策略groups.google.comgithub.com。**代码变更要点:**该PR主要修改了与标准交易校验和策略配置相关的代码,包括移除
script/standard.cpp中对OP_RETURN输出大小和数量的检查,以及删除策略配置选项-datacarrier和-datacarriersizegithub.com。具体而言:-
取消OP_RETURN大小限制:删除了判断OP_RETURN数据长度是否超过 MAX_OP_RETURN_RELAY(83字节)的标准性检查。此后,交易中的OP_RETURN输出脚本长度将不再被固定上限限制,只要满足区块重量等共识规则即可(理论上可嵌入远大于83字节的数据)github.comgroups.google.com。PR说明中明确提到移除了这些限制的执行代码github.com。相应地,
-datacarriersize配置参数被删除,因为其存在意义(设置OP_RETURN字节上限)已不复存在github.com。此前-datacarriersize默认为83,当用户调高该值时节点可接受更大数据载体输出;而现在代码中已无此参数,节点将无条件接受任意大小的OP_RETURN输出。 -
移除OP_RETURN输出数量限制:原先比特币核心默认策略还规定每笔交易最多只有一个OP_RETURN输出是标准的,多于一个即视为非标准交易(拒绝中继)bitcoin.stackexchange.com。该PR同样意在取消此“任意”限制groups.google.com。修改中移除了对
nDataOut(OP_RETURN输出计数)的检查,即允许一笔交易包含多个OP_RETURN输出而仍被视作标准交易。之前的代码若检测到nDataOut > 1会返回“multi-op-return”的拒绝原因github.com;PR删除了这一段逻辑,相应的功能测试也更新或移除了对“multi-op-return”非标准原因的断言github.com。 -
保留标准形式要求:值得注意的是,OP_RETURN输出的形式要求仍保留。PR描述中强调“数据载体输出的形式仍保持标准化:脚本以单个 OP_RETURN 开头,后跟任意数量的数据推字节;不允许非数据类的其他脚本操作码”github.com。也就是说,虽然大小和数量限制解除了,但OP_RETURN脚本内容只能是纯数据,不能夹带其他执行opcode。这保证了这些输出依然是“不可花费”的纯数据输出,不会改变它们对UTXO集的影响(不会增加UTXO)。
综上,PR #32359 的核心改动在策略层面放宽了对 OP_RETURN 的限制,删除了相关配置和检查,使节点默认接受任意大小、任意数量的 OP_RETURN 数据输出。同时维持其基本形式(OP_RETURN+数据)以确保此变更不会引入其它类型的非标准交易格式。
改动层级:策略规则 vs 共识规则
该提案属于策略层(policy-level)的更改,而非共识层规则的更改。也就是说,它影响的是节点对交易的_中继、存储和打包_策略,而不改变交易或区块在链上的有效性判定。OP_RETURN字节上限和数量限制从一开始就是标准性约束(Standardness),并非比特币共识协议的一部分groups.google.com。因此,移除这些限制不会导致旧节点与新节点产生区块共识分歧。具体理由如下:
-
无共识规则变动:原有的83字节上限只是节点默认_拒绝转发/挖矿_超限交易的规则,但如果矿工强行将超83字节的OP_RETURN交易打包进区块,所有遵循共识规则的节点(包括未升级的旧节点)依然会接受该区块。因为共识层并没有“OP_RETURN大小不得超过83字节”的规定github.com。正如开发者所指出的,现行的OP_RETURN限制属于“standardness rules”,其约束可以被轻易绕过,并不影响交易的最终有效性github.com。Peter Todd 在评论中强调,为真正禁止链上发布任意数据,必须修改比特币的共识协议,而这在现实中几乎不可能实施github.com。
-
**旧节点兼容性:**由于没有引入新的脚本opcode或共识验证规则,旧版本节点即使不升级,仍然会承认包含大OP_RETURN输出的区块为有效。换言之,不存在分叉风险。旧节点唯一的区别是仍会按照老策略拒绝中继此类交易,但一旦交易被打包进区块,它们仍会接受github.com。正因如此,这一提议不会引发硬分叉,只是改变默认策略。
-
**策略可自行定制:**另外,正如PR作者所言,这纯粹是默认策略的调整,用户依然可以选择运行修改版的软件继续实施先前的限制。例如,Peter Todd提到有替代实现(如 Bitcoin Knots)可以继续强制这些限制github.com。因此,这并非要“强制”所有节点解除限制,而是主流软件默认策略的演进。
需要澄清的是,有反对者担心解除限制可能扩大攻击面(下文详述),但这些都是针对节点资源和网络层面的影响,而非共识层安全性问题。总的来看,PR #32359 是策略层改进,与先前如RBF默认开启、逐渐弱化非标准交易限制等改变类似,其出发点在于网络行为而非协议规则本身。
对闪电网络节点和交易验证的影响
对链上验证的影响:由于这是策略层变更,交易和区块的验证规则并未改变,因此运行旧版本 Bitcoin Core 的闪电网络节点在共识上不会出现任何问题。闪电网络全节点通常依赖比特币全节点来跟踪链上交易,它们关心的是交易确认和共识有效性。解除OP_RETURN限制并不会使旧节点拒绝新区块,因而不会造成闪电通道关闭交易或HTLC交易在旧节点上验签失败等情况。换句话说,不升级Bitcoin Core软件的LN节点仍可正常参与链上共识,无需担心链上交易验证兼容性。
对节点中继和资源的影响:主要影响在于网络传播和资源占用。如果闪电网络节点所连接的Bitcoin Core没有升级,它将不会中继或存储那些含有超大OP_RETURN的未确认交易(因为旧版本视之为非标准交易)。这可能导致未升级节点的内存池与升级节点不一致:某些在新版节点中合法存在的交易,在旧版中被拒之门外。不过这通常不影响闪电网络的运行,因为闪电通道相关交易本身不会包含OP_RETURN数据输出。此外,当这些交易被矿工打包进区块后,旧节点依然会接收到区块并处理。所以,即便LN节点的后端Bitcoin Core未升级,最坏情形只是它在交易未打包时可能感知不到这些“大数据”交易,但这通常无碍于闪电网络功能(闪电网络主要关心的是通道交易的确认情况)。
升级的好处和必要性:从闪电网络生态来看,放宽OP_RETURN限制反而可能带来一些正面作用。正如前述,已有闪电网络周边项目因为83字节限制不足,转而使用不可花费输出存储数据groups.google.com。例如 Antoine Poinsot 在邮件列表中提到的 Clementine 协议,将某些watchtower挑战数据存进Taproot输出,因为OP_RETURN容量不够groups.google.com。解除限制后,此类应用完全可以改用更友好的OP_RETURN输出来存储数据,不再制造永久占据UTXO集的“垃圾”UTXOgithub.com。因此,闪电网络的watchtower、跨链桥等组件若需要在链上写入证据数据,将可直接利用更大的OP_RETURN输出,网络整体效率和健壮性都会提升。
需要注意的是,如果PR最终被合并并广泛部署,闪电网络节点运营者应该升级其Bitcoin Core后端以跟上新的默认策略。升级后,其节点将和大多数网络节点一样中继和接受大OP_RETURN交易,确保自己的内存池和网络同步,不会漏掉一些潜在相关交易(尽管目前来看,这些交易对LN通道本身并无直接关联)。总之,从兼容性看不升级没有致命问题,但从网络参与度和功能上看,升级是有益的。
潜在的间接影响:反对者提出,解除限制可能导致区块和内存池充斥更多任意数据,从而推高链上手续费、影响闪电通道关闭时所需的手续费估计。例如,如果大量大OP_RETURN交易占据区块空间,链上拥堵加剧,LN通道关闭需要支付更高费用才能及时确认。这其实是一般性拥堵问题,并非LN特有的兼容性问题。支持者则认为,这正是自由市场作用的体现,使用链上空间就该竞争付费github.com。无论如何,闪电网络作为二层方案,其优势在于减少链上交互频率,链上手续费市场的变化对LN有影响但不改变其运行逻辑。LN节点只需确保其Bitcoin Core正常运行、及时跟上链上状态即可。
开发者讨论焦点:支持与反对观点
PR #32359 在开发者社区引发了激烈讨论,支持者和反对者针锋相对,各自提出了有力的论据。以下总结双方主要观点:
-
支持方观点:
-
当前限制无效且适得其反:支持者强调83字节上限并未阻止人们在链上存数据,反而促使更有害的行为。Peter Todd指出,很多协议改用不可花费UTXO或在
scriptsig中藏数据来绕过OP_RETURN限制,结果增加了UTXO集膨胀,这是限制OP_RETURN带来的反效果github.com。与其如此,不如移除限制,让数据都写入可被丢弃的OP_RETURN输出,避免UTXO污染github.comgithub.com。正如一位支持者所言:“与其让尘埃UTXO永远留在UTXO集合,不如使用可证明不可花费的输出(OP_RETURN)”github.com。 -
**限制易被绕过,增添维护负担:**由于有些矿工或服务商(如MARA Slipstream私有广播)本就接受大OP_RETURN交易,这一限制对有心者来说形同虚设github.com。同时,存在维护这个限制的代码和配置选项,增加了节点实现复杂度。Todd认为,与其让Bitcoin Core承担维护“低效甚至有害”的限制,不如干脆取消,有需要的人可以使用其他软件实现自己的政策github.com。他提到有替代的Bitcoin Knots节点可自行过滤“垃圾”交易,但没必要要求Bitcoin Core默认坚持这些无效限制github.com。
-
尊重自由市场,拥抱链上数据用例:部分支持者从理念上认为,比特币区块空间的使用应交由手续费市场决定,而不应由节点软件做人为限制。著名开发者 Jameson Lopp 表示,是时候承认“有人就是想用比特币做数据锚定”,我们应当提供更优方式满足这种需求,而不是一味阻碍github.com。他认为用户既然愿意付费存数据,就说明这种行为对他们有价值,矿工也有动力处理;网络层不应进行过度的“父爱”式管制github.com。对于反对者所称“大数据交易会挤占区块、抬高手续费”,Lopp直言“这本来就是区块空间市场运作方式”,愿付高费者得以优先确认,无可厚非github.com。
-
统一与简化策略:还有支持者指出,既然限制容易绕过且逐渐没人遵守,那保留它只会造成节点之间策略不一致,反而增加网络复杂性。通过取消限制,所有核心节点一致地接受任意大小OP_RETURN,可避免因为策略差异导致的网络孤块或中继不畅(尽管共识不受影响,但策略不一致会带来一些网络层问题)。同时删除相关配置项,意味着简化用户配置,减少困惑和误用。Peter Todd在回应保留配置选项的建议时提到,Bitcoin Core在Full-RBF功能上也曾移除过用户可选项,直接默认启用,因为现实证明矿工最终都会朝盈利的方向调整策略,节点自行设置反而无济于事github.com。他以RBF为例:在Core开启默认Full-RBF之前,矿工几乎已经100%自行采用了RBF策略,因此保留开关意义不大github.com。类比来看,数据交易也是如此:如果有利可图,矿工终会打包,无论节点是否选择不转发。
-
反对方观点:
-
去除限制会放松对垃圾交易的防线:反对者担心,一旦解除OP_RETURN限制,链上将出现更多纯粹存储数据的“垃圾”交易,给网络带来DoS攻击和资源消耗风险。开发者 BrazyDevelopment 详细描述了可能被加剧的攻击向量github.com:首先,“Flood-and-Loot”攻击——攻击者构造带有巨大OP_RETURN数据的低价值交易(符合共识规则,多笔交易可达数MB数据),疯狂填充各节点的内存池。github.com这样会占满节点内存和带宽,延迟正常交易的传播和确认,并推高手续费竞争。github.com虽然节点有
maxmempool大小限制和最低中继费率等机制,但这些机制基于常规交易行为调校,面对异常海量的数据交易可能捉襟见肘github.com。其次,“RBF替换循环”攻击——攻击者可以利用无需额外费用的RBF替换,不断发布和替换包含大OP_RETURN的数据交易,在内存池中反复占据空间却不被确认,从而扰乱手续费市场和内存池秩序github.com。反对者认为,移除大小上限将使上述攻击更廉价、更容易实施github.com。他们主张即便要放宽,也应设定一个“高但合理”的上限(例如100KB),或在内存池压力大时动态调整限制,以保护较小资源节点的运行github.com。 -
用户丧失自定义策略的权利:一些开发者反对彻底删掉
-datacarrier和-datacarriersize选项。他们认为即使大势所趋是接受更多数据,也应保留用户自主选择的空间。正如开发者 BitcoinMechanic 所言:“矿工接受大数据交易不代表用户就不能选择自己的内存池装些什么”github.com。目前用户可以通过配置将-datacarrier设为0(不中继OP_RETURN交易)或者调低-datacarriersize来严格限制自己节点的策略。直接去除这些选项,会让那些出于各种考虑(如运营受限资源节点、防范垃圾数据)的用户失去控制权。从这个角度看,反对者认为限制应该由用户 opt-in 地解除,而不是一刀切放开。开发者 Retropex 也表示:“如果矿工想要更大的数据载体交易,他们完全可以自行调整这些设置…没有理由剥夺矿工和节点运营者做选择的权利”github.com。 -
此改动非必要且不符合部分用户利益:有反对意见认为当前83字节其实已经能覆盖绝大多数合理应用需求,更大的数据上链并非比特币设计初衷。他们担心放开限制会鼓励把比特币区块链当作任意数据存储层,偏离“点对点电子现金”主线,可能带来长期的链膨胀问题。这一阵营有人将此争议上升为理念之争:是坚持比特币作为金融交易为主,还是开放成为通用数据区块链?有评论形容这场拉锯“有点类似2017年的扩容之争”,虽然本质不同(一个是共识层区块大小辩论,一个是策略层数据使用辩论),但双方观点分歧同样明显99bitcoins.com99bitcoins.com。一些反对者(如Luke Dashjr等)长期主张减少非必要的数据上链,此次更是明确 Concept NACK。Luke-Jr 认为,其实完全可以通过引入地址格式变化等办法来识别并限制存数据的交易,而不需要动用共识层改动github.com(虽然他也承认这会非常激进和不现实,但以此反驳“除了改共识无计可施”的观点)。总之,反对者倾向于维持现状:代码里已有的限制无需移除,至少不应在无压倒性共识下贸然改变github.com。
-
社区共识不足:许多开发者在GitHub上给出了“Concept NACK”(概念上不支持)的评价。一位参与者感叹:“又来?两年前讨论过的理由现在依然适用”github.com。在PR的Review日志中,可以看到反对此提案的活跃贡献者数量明显多于支持者github.com。例如,反对阵营包括 Luke-Jr、BitcoinMechanic、CryptoGuida、1ma 等众多开发者和社区成员,而支持此提案的核心开发者相对少一些(包括Jameson Lopp、Sjöors、Sergio Demian Lerner等)github.com。这种意见分裂显示出社区对取消OP_RETURN限制尚未达成广泛共识。一些反对者还担忧这么大的改动可能引发社区矛盾,甚至有人夸张地提到可能出现新的链分叉风险99bitcoins.com99bitcoins.com(虽然实际上由于不涉及共识,硬分叉风险很小,但社区内部分歧确实存在)。
综上,支持者聚焦于提高链上效率、顺应实际需求和减轻UTXO负担,认为解除限制利大于弊;而反对者强调网络稳健、安全和用户自主,担心轻易放开会招致滥用和攻击。双方在GitHub上的讨论异常热烈,很多评论获得了数十个👍或👎表态,可见整个社区对此议题的关注度之高github.comgithub.com。
PR当前状态及后续展望
截至目前(2025年5月初),PR #32359 仍处于开放讨论阶段,并未被合并。鉴于该提案在概念上收到了众多 NACK,缺乏开发者间的明确共识,短期内合并的可能性不大。GitHub 上的自动统计显示,给予“Concept NACK”的评审者数量显著超过“Concept ACK”的数量github.com。这表明在Bitcoin Core维护者看来,社区对是否采纳此改动存在明显分歧。按照 Bitcoin Core 一贯的谨慎作风,当一个提案存在较大争议时,通常会被搁置或要求进一步修改、讨论,而不会仓促合并。
目前,该PR正等待进一步的评审和讨论。有开发者提出了替代方案或折中思路。例如,Bitcoin Core维护者 instagibbs 提交了相关的 PR #32406,提议仅取消默认的OP_RETURN大小上限(等效于将
-datacarriersize默认提高到极大),但保留配置选项,从而在不牺牲用户选择权的情况下实现功能开放github.com。这表明部分反对者并非完全拒绝放宽限制,而是希望以更温和的方式推进。PR #32359 与这些提案互相冲突,需要协调出统一的方案github.com。另外,也有开发者建议在测试网上模拟大OP_RETURN交易的攻击场景,以评估风险、说服怀疑者github.com。审议状态总结:综合来看,PR #32359 尚未接近合并,更谈不上被正式接受进入下一个Bitcoin Core版本。它既没有被关闭(拒绝),也没有快速进入最终review/merge阶段,而是停留在激烈讨论中。目前Bitcoin Core的维护者并未给出明确的合并时间表,反而是在鼓励社区充分讨论其利弊。未来的走向可能有几种:要么提案经过修改(例如保留配置项、增加安全机制等)逐渐赢得共识后合并,要么维持搁置等待更明确的社区信号。此外,不排除开发者转而采用渐进路线——例如先在测试网络取消限制试验,或先提高上限值而非彻底移除,以观察效果。也有可能此提案最终会因共识不足而长期悬而不决。
总之,OP_RETURN字节限制之争体现了比特币开发中策略层决策的审慎和平衡:需要在创新开放与稳健保守之间找到折衷。PR #32359 所引发的讨论仍在持续,它的意义在于促使社区重新审视链上数据存储的策略取舍。无论最终结果如何,这一讨论本身对比特币的发展具有积极意义,因为它让开发者和社区更加清晰地权衡了比特币作为数据载体和价值载体的定位。我们将持续关注该提案的进展,以及围绕它所展开的进一步测试和论证。github.comgroups.google.com
引用来源:
-
Bitcoin Core PR #32359 提案内容github.comgithub.com及开发者讨论(Peter Todd评论github.comgithub.com等)
-
Bitcoin Dev 邮件列表讨论帖:《Relax OP_RETURN standardness restrictions》groups.google.comgroups.google.com
-
GitHub 开发者评论摘录:支持意见(Jameson Loppgithub.com等)与反对意见(BitcoinMechanicgithub.com、BrazyDevelopmentgithub.com等)
-
Bitcoin Core PR 评论自动统计(Concept ACK/NACK 汇总)github.com
-
-
@ 9bde4214:06ca052b
2025-04-22 18:13:37
"It's gonna be permissionless or hell."
Gigi and gzuuus are vibing towards dystopia.
Books & articles mentioned:
- AI 2027
- DVMs were a mistake
- Careless People by Sarah Wynn-Williams
- Takedown by Laila michelwait
- The Ultimate Resource by Julian L. Simon
- Harry Potter by J.K. Rowling
- Momo by Michael Ende
In this dialogue:
- Pablo's Roo Setup
- Tech Hype Cycles
- AI 2027
- Prompt injection and other attacks
- Goose and DVMCP
- Cursor vs Roo Code
- Staying in control thanks to Amber and signing delegation
- Is YOLO mode here to stay?
- What agents to trust?
- What MCP tools to trust?
- What code snippets to trust?
- Everyone will run into the issues of trust and micropayments
- Nostr solves Web of Trust & micropayments natively
- Minimalistic & open usually wins
- DVMCP exists thanks to Totem
- Relays as Tamagochis
- Agents aren't nostr experts, at least not right now
- Fix a mistake once & it's fixed forever
- Giving long-term memory to LLMs
- RAG Databases signed by domain experts
- Human-agent hybrids & Chess
- Nostr beating heart
- Pluggable context & experts
- "You never need an API key for anything"
- Sats and social signaling
- Difficulty-adjusted PoW as a rare-limiting mechanism
- Certificate authorities and centralization
- No solutions to policing speech!
- OAuth and how it centralized
- Login with nostr
- Closed vs open-source models
- Tiny models vs large models
- The minions protocol (Stanford paper)
- Generalist models vs specialized models
- Local compute & encrypted queries
- Blinded compute
- "In the eyes of the state, agents aren't people"
- Agents need identity and money; nostr provides both
- "It's gonna be permissionless or hell"
- We already have marketplaces for MCP stuff, code snippets, and other things
- Most great stuff came from marketplaces (browsers, games, etc)
- Zapstore shows that this is already working
- At scale, central control never works. There's plenty scams and viruses in the app stores.
- Using nostr to archive your user-generated content
- HAVEN, blossom, novia
- The switcharoo from advertisements to training data
- What is Truth?
- What is Real?
- "We're vibing into dystopia"
- Who should be the arbiter of Truth?
- First Amendment & why the Logos is sacred
- Silicon Valley AI bros arrogantly dismiss wisdom and philosophy
- Suicide rates & the meaning crisis
- Are LLMs symbiotic or parasitic?
- The Amish got it right
- Are we gonna make it?
- Careless People by Sarah Wynn-Williams
- Takedown by Laila michelwait
- Harry Potter dementors & Momo's time thieves
- Facebook & Google as non-human (superhuman) agents
- Zapping as a conscious action
- Privacy and the internet
- Plausible deniability thanks to generative models
- Google glasses, glassholes, and Meta's Ray Ben's
- People crave realness
- Bitcoin is the realest money we ever had
- Nostr allows for real and honest expression
- How do we find out what's real?
- Constraints, policing, and chilling effects
- Jesus' plans for DVMCP
- Hzrd's article on how DVMs are broken (DVMs were a mistake)
- Don't believe the hype
- DVMs pre-date MCP tools
- Data Vending Machines were supposed to be stupid: put coin in, get stuff out.
- Self-healing vibe-coding
- IP addresses as scarce assets
- Atomic swaps and the ASS protocol
- More marketplaces, less silos
- The intensity of #SovEng and the last 6 weeks
- If you can vibe-code everything, why build anything?
- Time, the ultimate resource
- What are the LLMs allowed to think?
- Natural language interfaces are inherently dialogical
- Sovereign Engineering is dialogical too
-
@ fd78c37f:a0ec0833
2025-04-21 04:40:30
Bitcoin is redefining finance, and in Asia—Thailand, Vietnam, Indonesia, and beyond—developers, entrepreneurs, and communities are fueling this revolution. YakiHonne, a decentralized social payments app built on Nostr, sat down with Gio (nostr:npub1yrnuj56rnen08zp2h9h7p74ghgjx6ma39spmpj6w9hzxywutevsst7k5cx), a core member of Thailand’s Sats ‘N’ Facts community, to explore their mission of fostering open-source Bitcoin development. In this interview, Gio shares the origins of Sats ‘N’ Facts, the challenges of hosting Bitcoin-focused events in Asia, and how these efforts are shaping adoption across the region.
YakiHonne: Can you tell us about yourself and how Sats ‘N’ Facts came to life? What sparked your Bitcoin journey?
Gio: I’m originally from Europe but have called Thailand home for six years. My Bitcoin story began while working at a commercial bank, where I saw the fiat system’s flaws firsthand—things like the Cantillon Effect, where money printing favors the connected few, felt deeply unfair. That discomfort led me to Andreas Antonopoulos’ videos, which opened my eyes to Bitcoin’s potential. After moving to Bangkok, I joined the open-source scene at BOB Space, collaborating with folks on tech projects.
Sats ‘N’ Facts grew out of that spirit. We wanted to create a Bitcoin-focused community to support developers and builders in Asia. Our recent conference in Chiang Mai brought together over 70 enthusiasts from Thailand, Vietnam, Laos, and beyond, sparking collaborations like a new Lightning Network tool. It was a milestone in connecting the region’s Bitcoin ecosystem.
YakiHonne: What inspired the Sats ‘N’ Facts conference, and how did you attract attendees?
Gio: The event was born from a desire to create a high-signal, low-noise space for Freedom Tech in Asia. While the U.S. and Europe host major Bitcoin events, Asia’s scene is still emerging under commercial stunts. We aimed to bridge that gap, uniting developers, educators, and enthusiasts to discuss real innovations—no altcoins, no corporate agendas. Our focus was on open-source projects like Bitcoin Core, Ark, Cashu, fostering conversations that could lead to tangible contributions.
Attracting attendees wasn’t easy. We leveraged local networks, reaching out to Bitcoin communities in neighboring countries via Nostr and Telegram. Posts on X helped spread the word, and we saw developers from Laos join for the first time, which was thrilling. Sponsors like Fulgur Ventures, Utreexo, and the Bitcoin Development Kit Foundation played a huge role, covering costs so we could keep the event free and accessible.
YakiHonne: What challenges did you face organizing the conference in Asia?
Gio: It was a steep learning curve. Funding was the biggest hurdle—early on, we struggled to cover venue and travel costs. Thankfully, our sponsors stepped in, letting me focus on logistics, which were no small feat either. As a first-time organizer, I underestimated the chaos of a tight timeline. Day one felt like herding cats without a fixed agenda, but the energy was electric—developers debugging code together, newcomers asking big questions.
Another challenge was cultural. Bitcoin’s still niche in Asia, so convincing locals to attend took persistence; there was no local presence for some reason. Despite the hiccups, we pulled it off, hosting 60+ attendees and sparking ideas for new projects, like a Cashu wallet integration. I’d tweak the planning next time, but the raw passion made it unforgettable.
YakiHonne: How does YakiHonne’s vision of decentralized social payments align with Sats ‘N’ Facts’ goals? Could tools like ours support your community?
Gio: That’s a great question. YakiHonne’s approach—merging Nostr’s censorship-resistant communication with Lightning payments—fits perfectly with our mission to empower users through open tech. At Sats ‘N’ Facts, we’re all about tools that give people control, whether it’s code or money. An app like YakiHonne could streamline community funding, letting developers tip each other for contributions or crowdfund projects directly. Imagine a hackathon where winners get sats instantly via YakiHonne—it’d be a game-changer. I’d love to see you guys at our next event to demo it!
YakiHonne: What advice would you give to someone starting a Bitcoin-focused community or event?
Gio: First, keep it Bitcoin-only. Stay true to the principles—cut out distractions like altcoins or hype-driven schemes. Start small: host regular meetups, maybe five people at a café, and build trust over time. Consistency and authenticity beat flashiness in the medium and long term.
Second, involve technical folks. Developers bring credibility and clarity, explaining Bitcoin’s nuts and bolts in ways newcomers get. I admire how Andreas Antonopoulos bridges that gap—technical yet accessible. You need that foundation to grow a real community.
Finally, lean on existing networks. If you know someone running a Bitcoin meetup in another city, collaborate. Share ideas, speakers, or even livestreams. Nostr’s great for this—our Laos attendees found us through a single post. Relationships are everything.
YakiHonne: Does Sats ‘N’ Facts focus more on Bitcoin’s technical side, non-technical side, or both?
Gio: We blend both. Our event had workshops for coders alongside talks for beginners on why Bitcoin matters. Open-source is our heartbeat, though. If you’re starting out, dive into projects like Bitcoin Core or Lightning. Review a pull request, test a Cashu wallet, or join a hackathon. One developer at our event built a Lightning micropayment tool that’s now live on GitHub.
There’s no shortage of ways to contribute. Community calls, forums, residency programs, and platforms like Geyser Fund are goldmines. YakiHonne could amplify this—imagine tipping developers for bug fixes via your app. It’s about iterating until you create something real.
YakiHonne: Your work is inspiring, Gio. Sats ‘N’ Facts is uniting Asia’s Bitcoin communities in a powerful way. What’s next for you?
Gio: Thanks for the kind words! We’re just getting started. The Chiang Mai event showed what’s possible—connecting developers across borders, reviewing and launching code and testing upcoming technologies. Next, we’re planning smaller hackathons and other events to keep the momentum going, maybe in Vietnam, Indonesia or Korea. I’d love to integrate tools like YakiHonne to fund these efforts directly through Nostr payments. Long-term, we want Sats ‘N’ Facts to be a hub for Asia’s Bitcoin builders, proving open-source can thrive here.

YakiHonne: Thank you, Gio, for sharing Sats ‘N’ Facts incredible journey. Your work is lighting a path for Bitcoin in Asia, and we’re honored to tell this story.
To our readers: Bitcoin’s future depends on communities like Sats ‘N’ Facts—and you can join the revolution. Download YakiHonne on Nostr to connect with builders, send Lightning payments, and explore the decentralized world. Follow Sats ‘N’ Facts for their next hackathon, and let’s build freedom tech together!
-
@ e6817453:b0ac3c39
2024-12-07 14:54:46
Introduction: Personal Knowledge Graphs and Linked Data
We will explore the world of personal knowledge graphs and discuss how they can be used to model complex information structures. Personal knowledge graphs aren’t just abstract collections of nodes and edges—they encode meaningful relationships, contextualizing data in ways that enrich our understanding of it. While the core structure might be a directed graph, we layer semantic meaning on top, enabling nuanced connections between data points.
The origin of knowledge graphs is deeply tied to concepts from linked data and the semantic web, ideas that emerged to better link scattered pieces of information across the web. This approach created an infrastructure where data islands could connect — facilitating everything from more insightful AI to improved personal data management.
In this article, we will explore how these ideas have evolved into tools for modeling AI’s semantic memory and look at how knowledge graphs can serve as a flexible foundation for encoding rich data contexts. We’ll specifically discuss three major paradigms: RDF (Resource Description Framework), property graphs, and a third way of modeling entities as graphs of graphs. Let’s get started.
Intro to RDF
The Resource Description Framework (RDF) has been one of the fundamental standards for linked data and knowledge graphs. RDF allows data to be modeled as triples: subject, predicate, and object. Essentially, you can think of it as a structured way to describe relationships: “X has a Y called Z.” For instance, “Berlin has a population of 3.5 million.” This modeling approach is quite flexible because RDF uses unique identifiers — usually URIs — to point to data entities, making linking straightforward and coherent.
RDFS, or RDF Schema, extends RDF to provide a basic vocabulary to structure the data even more. This lets us describe not only individual nodes but also relationships among types of data entities, like defining a class hierarchy or setting properties. For example, you could say that “Berlin” is an instance of a “City” and that cities are types of “Geographical Entities.” This kind of organization helps establish semantic meaning within the graph.
RDF and Advanced Topics
Lists and Sets in RDF
RDF also provides tools to model more complex data structures such as lists and sets, enabling the grouping of nodes. This extension makes it easier to model more natural, human-like knowledge, for example, describing attributes of an entity that may have multiple values. By adding RDF Schema and OWL (Web Ontology Language), you gain even more expressive power — being able to define logical rules or even derive new relationships from existing data.
Graph of Graphs
A significant feature of RDF is the ability to form complex nested structures, often referred to as graphs of graphs. This allows you to create “named graphs,” essentially subgraphs that can be independently referenced. For example, you could create a named graph for a particular dataset describing Berlin and another for a different geographical area. Then, you could connect them, allowing for more modular and reusable knowledge modeling.
Property Graphs
While RDF provides a robust framework, it’s not always the easiest to work with due to its heavy reliance on linking everything explicitly. This is where property graphs come into play. Property graphs are less focused on linking everything through triples and allow more expressive properties directly within nodes and edges.
For example, instead of using triples to represent each detail, a property graph might let you store all properties about an entity (e.g., “Berlin”) directly in a single node. This makes property graphs more intuitive for many developers and engineers because they more closely resemble object-oriented structures: you have entities (nodes) that possess attributes (properties) and are connected to other entities through relationships (edges).
The significant benefit here is a condensed representation, which speeds up traversal and queries in some scenarios. However, this also introduces a trade-off: while property graphs are more straightforward to query and maintain, they lack some complex relationship modeling features RDF offers, particularly when connecting properties to each other.
Graph of Graphs and Subgraphs for Entity Modeling
A third approach — which takes elements from RDF and property graphs — involves modeling entities using subgraphs or nested graphs. In this model, each entity can be represented as a graph. This allows for a detailed and flexible description of attributes without exploding every detail into individual triples or lump them all together into properties.
For instance, consider a person entity with a complex employment history. Instead of representing every employment detail in one node (as in a property graph), or as several linked nodes (as in RDF), you can treat the employment history as a subgraph. This subgraph could then contain nodes for different jobs, each linked with specific properties and connections. This approach keeps the complexity where it belongs and provides better flexibility when new attributes or entities need to be added.
Hypergraphs and Metagraphs
When discussing more advanced forms of graphs, we encounter hypergraphs and metagraphs. These take the idea of relationships to a new level. A hypergraph allows an edge to connect more than two nodes, which is extremely useful when modeling scenarios where relationships aren’t just pairwise. For example, a “Project” could connect multiple “People,” “Resources,” and “Outcomes,” all in a single edge. This way, hypergraphs help in reducing the complexity of modeling high-order relationships.
Metagraphs, on the other hand, enable nodes and edges to themselves be represented as graphs. This is an extremely powerful feature when we consider the needs of artificial intelligence, as it allows for the modeling of relationships between relationships, an essential aspect for any system that needs to capture not just facts, but their interdependencies and contexts.
Balancing Structure and Properties
One of the recurring challenges when modeling knowledge is finding the balance between structure and properties. With RDF, you get high flexibility and standardization, but complexity can quickly escalate as you decompose everything into triples. Property graphs simplify the representation by using attributes but lose out on the depth of connection modeling. Meanwhile, the graph-of-graphs approach and hypergraphs offer advanced modeling capabilities at the cost of increased computational complexity.
So, how do you decide which model to use? It comes down to your use case. RDF and nested graphs are strong contenders if you need deep linkage and are working with highly variable data. For more straightforward, engineer-friendly modeling, property graphs shine. And when dealing with very complex multi-way relationships or meta-level knowledge, hypergraphs and metagraphs provide the necessary tools.
The key takeaway is that only some approaches are perfect. Instead, it’s all about the modeling goals: how do you want to query the graph, what relationships are meaningful, and how much complexity are you willing to manage?
Conclusion
Modeling AI semantic memory using knowledge graphs is a challenging but rewarding process. The different approaches — RDF, property graphs, and advanced graph modeling techniques like nested graphs and hypergraphs — each offer unique strengths and weaknesses. Whether you are building a personal knowledge graph or scaling up to AI that integrates multiple streams of linked data, it’s essential to understand the trade-offs each approach brings.
In the end, the choice of representation comes down to the nature of your data and your specific needs for querying and maintaining semantic relationships. The world of knowledge graphs is vast, with many tools and frameworks to explore. Stay connected and keep experimenting to find the balance that works for your projects.
-
@ 56cd780f:cbde8b29
2025-05-05 14:31:56
[Test3] Trying to show subtitle
Is it actually called “summary”?
-
@ ed5774ac:45611c5c
2025-04-19 20:29:31
April 20, 2020: The day I saw my so-called friends expose themselves as gutless, brain-dead sheep.
On that day, I shared a video exposing the damning history of the Bill & Melinda Gates Foundation's vaccine campaigns in Africa and the developing world. As Gates was on every TV screen, shilling COVID jabs that didn’t even exist, I called out his blatant financial conflict of interest and pointed out the obvious in my facebook post: "Finally someone is able to explain why Bill Gates runs from TV to TV to promote vaccination. Not surprisingly, it's all about money again…" - referencing his substantial investments in vaccine technology, including BioNTech's mRNA platform that would later produce the COVID vaccines and generate massive profits for his so-called philanthropic foundation.
The conflict of interest was undeniable. I genuinely believed anyone capable of basic critical thinking would at least pause to consider these glaring financial motives. But what followed was a masterclass in human stupidity.
My facebook post from 20 April 2020:

Not only was I branded a 'conspiracy theorist' for daring to question the billionaire who stood to make a fortune off the very vaccines he was shilling, but the brain-dead, logic-free bullshit vomited by the people around me was beyond pathetic. These barely literate morons couldn’t spell "Pfizer" without auto-correct, yet they mindlessly swallowed and repeated every lie the media and government force-fed them, branding anything that cracked their fragile reality as "conspiracy theory." Big Pharma’s rap sheet—fraud, deadly cover-ups, billions in fines—could fill libraries, yet these obedient sheep didn’t bother to open a single book or read a single study before screaming their ignorance, desperate to virtue-signal their obedience. Then, like spineless lab rats, they lined up for an experimental jab rushed to the market in months, too dumb to care that proper vaccine development takes a decade.
The pathetic part is that these idiots spend hours obsessing over reviews for their useless purchases like shoes or socks, but won’t spare 60 seconds to research the experimental cocktail being injected into their veins—or even glance at the FDA’s own damning safety reports. Those same obedient sheep would read every Yelp review for a fucking coffee shop but won't spend five minutes looking up Pfizer's criminal fraud settlements. They would demand absolute obedience to ‘The Science™’—while being unable to define mRNA, explain lipid nanoparticles, or justify why trials were still running as they queued up like cattle for their jab. If they had two brain cells to rub together or spent 30 minutes actually researching, they'd know, but no—they'd rather suck down the narrative like good little slaves, too dumb to question, too weak to think.
Worst of all, they became the system’s attack dogs—not just swallowing the poison, but forcing it down others’ throats. This wasn’t ignorance. It was betrayal. They mutated into medical brownshirts, destroying lives to virtue-signal their obedience—even as their own children’s hearts swelled with inflammation.
One conversation still haunts me to this day—a masterclass in wealth-worship delusion. A close friend, as a response to my facebook post, insisted that Gates’ assumed reading list magically awards him vaccine expertise, while dismissing his billion-dollar investments in the same products as ‘no conflict of interest.’ Worse, he argued that Gates’s $5–10 billion pandemic windfall was ‘deserved.’
This exchange crystallizes civilization’s intellectual surrender: reason discarded with religious fervor, replaced by blind faith in corporate propaganda.
The comment of a friend on my facebook post that still haunts me to this day:

Walking Away from the Herd
After a period of anger and disillusionment, I made a decision: I would no longer waste energy arguing with people who refused to think for themselves. If my circle couldn’t even ask basic questions—like why an untested medical intervention was being pushed with unprecedented urgency—then I needed a new community.
Fortunately, I already knew where to look. For three years, I had been involved in Bitcoin, a space where skepticism wasn’t just tolerated—it was demanded. Here, I’d met some of the most principled and independent thinkers I’d ever encountered. These were people who understood the corrupting influence of centralized power—whether in money, media, or politics—and who valued sovereignty, skepticism, and integrity. Instead of blind trust, bitcoiners practiced relentless verification. And instead of empty rhetoric, they lived by a simple creed: Don’t trust. Verify.
It wasn’t just a philosophy. It was a lifeline. So I chose my side and I walked away from the herd.
Finding My Tribe
Over the next four years, I immersed myself in Bitcoin conferences, meetups, and spaces where ideas were tested, not parroted. Here, I encountered extraordinary people: not only did they share my skepticism toward broken systems, but they challenged me to sharpen it.
No longer adrift in a sea of mindless conformity, I’d found a crew of thinkers who cut through the noise. They saw clearly what most ignored—that at the core of society’s collapse lay broken money, the silent tax on time, freedom, and truth itself. But unlike the complainers I’d left behind, these people built. They coded. They wrote. They risked careers and reputations to expose the rot. Some faced censorship; others, mockery. All understood the stakes.
These weren’t keyboard philosophers. They were modern-day Cassandras, warning of inflation’s theft, the Fed’s lies, and the coming dollar collapse—not for clout, but because they refused to kneel to a dying regime. And in their defiance, I found something rare: a tribe that didn’t just believe in a freer future. They were engineering it.
April 20, 2024: No more herd. No more lies. Only proof-of-work.
On April 20, 2024, exactly four years after my last Facebook post, the one that severed my ties to the herd for good—I stood in front of Warsaw’s iconic Palace of Culture and Science, surrounded by 400 bitcoiners who felt like family. We were there to celebrate Bitcoin’s fourth halving, but it was more than a protocol milestone. It was a reunion of sovereign individuals. Some faces I’d known since the early days; others, I’d met only hours before. We bonded instantly—heated debates, roaring laughter, zero filters on truths or on so called conspiracy theories.
As the countdown to the halving began, it hit me: This was the antithesis of the hollow world I’d left behind. No performative outrage, no coerced consensus—just a room of unyielding minds who’d traded the illusion of safety for the grit of truth. Four years prior, I’d been alone in my resistance. Now, I raised my glass among my people - those who had seen the system's lies and chosen freedom instead. Each had their own story of awakening, their own battles fought, but here we shared the same hard-won truth.
The energy wasn’t just electric. It was alive—the kind that emerges when free people build rather than beg. For the first time, I didn’t just belong. I was home. And in that moment, the halving’s ticking clock mirrored my own journey: cyclical, predictable in its scarcity, revolutionary in its consequences. Four years had burned away the old world. What remained was stronger.

No Regrets
Leaving the herd wasn’t a choice—it was evolution. My soul shouted: "I’d rather stand alone than kneel with the masses!". The Bitcoin community became more than family; they’re living proof that the world still produces warriors, not sheep. Here, among those who forge truth, I found something extinct elsewhere: hope that burns brighter with every halving, every block, every defiant mind that joins the fight.
Change doesn’t come from the crowd. It starts when one person stops applauding.
Today, I stand exactly where I always wanted to be—shoulder-to-shoulder with my true family: the rebels, the builders, the ungovernable. Together, we’re building the decentralized future.
-
@ e6817453:b0ac3c39
2024-12-07 14:52:47
The temporal semantics and temporal and time-aware knowledge graphs. We have different memory models for artificial intelligence agents. We all try to mimic somehow how the brain works, or at least how the declarative memory of the brain works. We have the split of episodic memory and semantic memory. And we also have a lot of theories, right?
Declarative Memory of the Human Brain
How is the semantic memory formed? We all know that our brain stores semantic memory quite close to the concept we have with the personal knowledge graphs, that it’s connected entities. They form a connection with each other and all those things. So far, so good. And actually, then we have a lot of concepts, how the episodic memory and our experiences gets transmitted to the semantic:
- hippocampus indexing and retrieval
- sanitization of episodic memories
- episodic-semantic shift theory
They all give a different perspective on how different parts of declarative memory cooperate.
We know that episodic memories get semanticized over time. You have semantic knowledge without the notion of time, and probably, your episodic memory is just decayed.
But, you know, it’s still an open question:
do we want to mimic an AI agent’s memory as a human brain memory, or do we want to create something different?
It’s an open question to which we have no good answer. And if you go to the theory of neuroscience and check how episodic and semantic memory interfere, you will still find a lot of theories, yeah?
Some of them say that you have the hippocampus that keeps the indexes of the memory. Some others will say that you semantic the episodic memory. Some others say that you have some separate process that digests the episodic and experience to the semantics. But all of them agree on the plan that it’s operationally two separate areas of memories and even two separate regions of brain, and the semantic, it’s more, let’s say, protected.
So it’s harder to forget the semantical facts than the episodes and everything. And what I’m thinking about for a long time, it’s this, you know, the semantic memory.
Temporal Semantics
It’s memory about the facts, but you somehow mix the time information with the semantics. I already described a lot of things, including how we could combine time with knowledge graphs and how people do it.
There are multiple ways we could persist such information, but we all hit the wall because the complexity of time and the semantics of time are highly complex concepts.
Time in a Semantic context is not a timestamp.
What I mean is that when you have a fact, and you just mentioned that I was there at this particular moment, like, I don’t know, 15:40 on Monday, it’s already awake because we don’t know which Monday, right? So you need to give the exact date, but usually, you do not have experiences like that.
You do not record your memories like that, except you do the journaling and all of the things. So, usually, you have no direct time references. What I mean is that you could say that I was there and it was some event, blah, blah, blah.
Somehow, we form a chain of events that connect with each other and maybe will be connected to some period of time if we are lucky enough. This means that we could not easily represent temporal-aware information as just a timestamp or validity and all of the things.
For sure, the validity of the knowledge graphs (simple quintuple with start and end dates)is a big topic, and it could solve a lot of things. It could solve a lot of the time cases. It’s super simple because you give the end and start dates, and you are done, but it does not answer facts that have a relative time or time information in facts . It could solve many use cases but struggle with facts in an indirect temporal context. I like the simplicity of this idea. But the problem of this approach that in most cases, we simply don’t have these timestamps. We don’t have the timestamp where this information starts and ends. And it’s not modeling many events in our life, especially if you have the processes or ongoing activities or recurrent events.
I’m more about thinking about the time of semantics, where you have a time model as a hybrid clock or some global clock that does the partial ordering of the events. It’s mean that you have the chain of the experiences and you have the chain of the facts that have the different time contexts.
We could deduct the time from this chain of the events. But it’s a big, big topic for the research. But what I want to achieve, actually, it’s not separation on episodic and semantic memory. It’s having something in between.
Blockchain of connected events and facts
I call it temporal-aware semantics or time-aware knowledge graphs, where we could encode the semantic fact together with the time component.I doubt that time should be the simple timestamp or the region of the two timestamps. For me, it is more a chain for facts that have a partial order and form a blockchain like a database or a partially ordered Acyclic graph of facts that are temporally connected. We could have some notion of time that is understandable to the agent and a model that allows us to order the events and focus on what the agent knows and how to order this time knowledge and create the chains of the events.
Time anchors
We may have a particular time in the chain that allows us to arrange a more concrete time for the rest of the events. But it’s still an open topic for research. The temporal semantics gets split into a couple of domains. One domain is how to add time to the knowledge graphs. We already have many different solutions. I described them in my previous articles.
Another domain is the agent's memory and how the memory of the artificial intelligence treats the time. This one, it’s much more complex. Because here, we could not operate with the simple timestamps. We need to have the representation of time that are understandable by model and understandable by the agent that will work with this model. And this one, it’s way bigger topic for the research.”
-
@ c9badfea:610f861a
2025-05-05 12:55:46
1. Create
bash git bundle create backup.bundle --all2. Verify
bash git bundle verify backup.bundle3. Restore
bash git clone backup.bundleℹ️ Feel free to change the
backup.bundlefile name -
@ 41959693:3888319c
2025-05-05 10:58:49
Die Schnelllebigkeit der Moderne tilgt in unserer Wahrnehmung die zeitlichen Abstände von Ereignissen. Es bleibt kaum Gelegenheit ein Thema im Rückspiegel zu erfassen, zu durchdenken, zu rezipieren – schon buhlt der nächste Augenblick um Aufmerksamkeit.
Mögen an die Leipziger Buchmesse Ende März mittlerweile nur noch Visitenkarten und Selfies oder manch signiertes Exemplar im Buchregal erinnern; es lohnt sich doch, die größte deutsche Besuchermesse der Buchbranche nun rückblickend zu betrachten. Gerade da ihr Event-Charakter von Jahr zu Jahr zunimmt, ist die Frage reizvoll, welche beständigen Themen dort wie präsentiert wurden, in diesem Fall natürlich „Frieden“.
An allen vier Messetagen hielt ich die Augen auf, wo sich Autoren, Verlage und allgemeine die Institutionen der Branche dazu äußerten. Vorgreifend muss gesagt werden, dass Krieg und Frieden heute nicht mehr zwingend primäre Themen sind, sondern oft begleitend mitbehandelt werden. Für Zerstörung und Elend scheint dabei immer die große Bühne bereitet zu werden; einvernehmliche Koexistenz wird gewöhnlich mit leiser Klaviatur gespielt. Dennoch fand ich vier Bücher, welche direkt das Thema ansprachen:
- Die norwegische Soziologin und Publizistin Linn Stalsberg stellte ihr Werk „War is contempt for life. An essay on peace“ (ISBN: 978-8282262736, Res Publica, 2024) vor, in welchem sie auf all die Menschen eingeht, die für Pazifismus, Gewaltlosigkeit und Anti-Militarismus einstehen. Ihrer Meinung nach haben wir unzählige Berichte über Kriegs-, kaum jedoch Geschichten von Friedenshelden. Die deutsche Ausgabe soll im schweizerischen Kommode-Verlag im September diesen Jahres erscheinen.
-
„Die Evolution der Gewalt. Warum wir Frieden wollen, aber Kriege führen“, geschrieben von Kai Michel, Harald Meller und Carel van Schaik, wurde für den Preis der Leipziger Buchmesse in der Kategorie Sachbuch/Essayistik nominiert. Die Autoren vertreten u. a. die Thesen, dass Krieg kein essentieller Gesellschaftsprozess ist, wie es einige geflügelte Worte oder ideologische Äußerungen vermuten lassen – und, dass die Erfolge der Bellizisten nur 1 % der Weltgeschichte ausmachen (ISBN: 978-3423284387, dtv, 2024).
-
Der Publizist und taz-Redakteur Pascal Beucker gibt mit „Pazifismus – ein Irrweg?“ (ISBN 978-3170434325, Kohlhammer, 2024) eine Übersicht über die Geschichte des Pazifismus, geht auf in Vergessenheit geratene Hintergründe der einzelnen Motivationen und Bewegungen ein und wagt Zukunftsprognosen über die Erfolgschancen gewaltloser Auseinandersetzungen.
- Neben den Sachbüchern fand sich auch ein Vertreter aus dem Bereich der Belletristik: Rüdiger Heins und Michael Landgraf gaben eine Anthologie mit Friedenstexten, Prosa und Lyrik, heraus: „365 Tage Frieden“ (ISBN: 978-3930758951 Edition Maya, 2025), verspricht der Titel, für den zahlreiche Autoren auf ganz unterschiedliche Art und Weise träumten, sich erinnerten, uns mahnten und weiterhin hoffen.
Ansonsten fanden sich viele kleinere Veranstaltungsformate und Verlage, welche ihr Scherflein beitragen wollten, dabei aber sehr unscharf blieben und beispielsweise im Forum Offene Gesellschaft u. a. Grenzoffenheit, Toleranz und Inklusion behandelten. Inwieweit diese, in jüngster Vergangenheit doch recht stark medial forcierten Themen die zentrale Friedensfrage ergründen und stützen, ist vermutlich Auslegungssache.
Unsere Definition von Frieden mag nicht sonderlich scharf sein; jeder zieht darin andere Grenzen und wird sich situativ nach eigenem Gusto verhalten. Dennoch bewegt uns eine Grundschwingung, führt uns ein Sehnen in eine höhere, gemeinsame Richtung. Diese Erkenntnis ist es wert, durch den Lauf der Geschichte bewahrt zu werden, durch aktuelle Zeugnisse ebenso wie durch die Gedanken derer, die vor uns waren.
Ich habe beschlossen diese Bücher für Sie, werte Leser, in den nächsten Wochen nach und nach zu rezensieren.
Dieser Beitrag wurde mit dem Pareto-Client geschrieben.
Not yet on Nostr and want the full experience? Easy onboarding via Start.
Artikel findet man auch auf Telegram unter:
-
@ 3b19f10a:4e1f94b4
2024-12-07 09:55:46
-
@ cb4352cd:a16422d7
2025-05-05 10:08:06
Artificial intelligence is no longer just a buzzword — it’s becoming the quiet powerhouse behind many of the most meaningful changes in financial services. From helping people access credit to stopping fraud in its tracks, AI is making the financial world faster, smarter, and more personal.
Smarter Risk Management
Until recently, getting a loan meant paperwork, credit history checks, and plenty of waiting. But now, AI models can process huge amounts of data — including mobile usage and online behavior — to help lenders better understand a borrower’s real financial picture.
Startups like Upstart and Zest AI are making credit more inclusive by moving beyond legacy scoring models and enabling access to financing for underserved communities.
Personalized Financial Services
Robo-advisors like Betterment and Wealthfront are already using AI to build investment portfolios tailored to individual users. Digital banks use machine learning to analyze spending, offer savings tips, or spot unusual charges.
Meanwhile, virtual assistants and intelligent chatbots help customers manage finances without ever speaking to a human. The result? Financial tools that feel personal — and actually useful.
Fighting Fraud in Real Time
AI is becoming essential in financial security. Firms like Darktrace and Feedzai deploy AI systems that monitor transaction data in real time and flag anything suspicious. They learn from each interaction, making fraud detection faster and more accurate over time.
And in compliance, AI-powered tools can digest dense regulatory texts and help institutions stay within complex legal boundaries.
AI in Trading and Asset Management
In the world of trading, AI is now a key player. Quantitative funds use it to test strategies, scan headlines, and model price movements in seconds. Machine learning enables more nuanced, high-frequency trading — and can even spot trends before humans notice.
The Road Ahead: AI as a Financial Foundation
What once sounded futuristic is now foundational. AI is being woven into nearly every layer of financial services — and the impact is only just beginning.
The Beyond Banking Conference by WeFi will explore what’s next. From ethical AI use to the automation of banking infrastructure, the event will bring together leaders from FinTech, Web3, and AI to map the future of finance.
AI may not replace human judgment — but it’s already changing how we understand money, trust, and access.
-
@ b99efe77:f3de3616
2025-05-05 09:54:32
asfadfadsf
afasdfasdfsadf
Places & Transitions
- Places:
-
Bla bla bla: some text
-
Transitions:
- start: Initializes the system.
- logTask: bla bla bla.
petrinet ;startDay () -> working ;stopDay working -> () ;startPause working -> paused ;endPause paused -> working ;goSmoke working -> smoking ;endSmoke smoking -> working ;startEating working -> eating ;stopEating eating -> working ;startCall working -> onCall ;endCall onCall -> working ;startMeeting working -> inMeetinga ;endMeeting inMeeting -> working ;logTask working -> working -
@ 526bec6a:07c68d13
2025-05-05 08:20:00
01: Counterfeiting Money002: Credit Card Fraud003: Making Plastic Explosives from Bleach004: Picking Master Locks005: The Arts of Lockpicking I006: The Arts of Lockpicking II007: Solidox Bombs008: High Tech Revenge: The Beigebox (NEW Revision 4.14)009: CO2 Bombs010: Thermite Bombs (NEW Rivision, 4.14)011: Touch Explosives012: Letter Bombs013: Paint Bombs014: Ways to send a car to HELL015: Do ya hate school? (NEW Revision, 4.14)016: Phone related vandalism017: Highway police radar jamming018: Smoke Bombs019: Mail Box Bombs020: Hotwiring cars021: Napalm022: Fertilizer Bomb023: Tennis Ball Bomb024: Diskette Bombs025: Unlisted Phone Numbers (NEW Revision, 4.14)026: Fuses027: How to make Potassium Nitrate028: Exploding Lightbulbs029: Under water igniters030: Home-brew blast cannon031: Chemical Equivalency List032: Phone Taps033: Landmines034: A different kind of Molitov Cocktail035: Phone Systems Tutorial I036: Phone Systems Tutorial II037: Basic Alliance Teleconferencing038: Aqua Box Plans039: Hindenberg Bomb040: How to Kill Someone with your Bare Hands041: Phone Systems Tutorial III042: Black Box Plans043: The Blotto Box044: Blowgun045: Brown Box Plans046: Calcium Carbide Bomb047: More Ways to Send a Car to Hell048: Ripping off Change Machines (NEW Revision, 4.14)049: Clear Box Plans050: CNA Number Listing051: Electronic Terrorism052: How to Start a Conference w/o 2600hz or M-F053: Dynamite054: Auto Exhaust Flame Thower055: How to Break into BBS Express056: Firebomb057: Fuse Bomb058: Generic Bomb059: Green Box Plans060: Portable Grenade Launcher061: Basic Hacking Tutorial I062: Basic Hacking Tutorial II063: Hacking DEC's064: Harmless Bombs 065: Breaking into Houses (NEW Revision, 4.14)066: Hypnotism067: Remote Informer Issue #1068: Jackpotting ATM Machines069: Jug Bomb070: Fun at K-Mart071: Mace Substitute072: How to Grow Marijuana073: Match Head Bomb074: Terrorizing McDonalds075: "Mentor's" Last Words076: The Myth of the 2600hz Detector077: Blue Box Plans (Ye' olde Favorite)078: Napalm II079: Nitroglycerin Recipe080: Operation: Fuckup081: Stealing Calls from Payphones082: Pool Fun (NEW Revision, 4.14)083: Free Postage084: Unstable Explosives085: Weird Drugs086: The Art of Carding087: Recognizing Credit Cards088: How to Get a New Identity089: Remote Informer Issue #2090: Remote Informer Issue #3091: Remote Informer Issue #4092: Remote Informer Issue #5093: Phreaker's Guide to Loop Lines094: Ma-Bell Tutorial095: Getting Money out of Pay Phones096: Computer-based PBX097: PC-Pursuit Port Statistics098: Pearl Box Plans099: The Phreak File100: Red Box Plans101: RemObs102: Scarlet Box Plans103: Silver Box Plans104: Bell Trashing105: Canadian WATS Phonebook106: Hacking TRW107: Hacking VAX & UNIX108: Verification Circuits109: White Box Plans110: The BLAST Box111: Dealing with the Rate & Route Operator112: Cellular Phone Phreaking113: Cheesebox Plans114: How to Start Your Own Conferences115: Gold Box Plans116: The History of ESS117: The Lunch Box118: Olive Box Plans119: The Tron Box120: More TRW Info121: "Phreaker's Phunhouse"122: Phrack Magazine - Vol. 3, Issue 27 (Intro to MIDNET)123: Phrack Magazine - Vol. 3, Issue 27 (The Making of a Hacker)124: Phrack Magazine - Vol. 3, Issue 28 (Network Miscellany)125: Phrack Magazine - Vol. 3, Issue 28 (Pearl Box Schematic)126: Phrack Magazine - Vol. 3, Issue 28 (Snarfing Remote Files)127: Phrack Magazine - Vol. 3, Issue 30 (Western Union, Telex, TWX & Time Service)128: Phrack Magazine - Vol. 3, Issue 30 (Hacking & Tymnet)129: Phrack Magazine - Vol. 3, Issue 30 (The DECWRL Mail Gateway)130: Sodium Chlorate131: Mercury Fulminate132: Improvised Black Powder 133: Nitric Acid134: Dust Bomb Instructions135: Carbon-Tet Explosive136: Making Picric Acid from Aspirin137: Reclamation of RDX from C-4 Explosives138: Egg-based Gelled Flame Fuels139: Clothespin Switch140: Flexible Plate Switch141: Low Signature Systems (Silencers)142: Delay Igniter From Cigarette143: Nicotine144: Dried Seed Timer145: Nail Grenade146: Bell Glossary147: Phone Dial Locks -- How to Beat'em148: Exchange Scanning149: A Short History of Phreaking150: "Secrets of the Little Blue Box" (story)151: The History of British Phreaking152: "Bad as Shit" (story)153: Telenet154: Fucking with the Operator155: Phrack Magazine - Vol. 1, Issue 1 (The Phone Preak's Fry-Um Guide)156: International Country Code Listing157: Infinity Transmitter Schematic and Plans158: LSD159: Bananas160: Yummy Marihuana Recipes161: Peanuts162: Chemical Fire Bottle163: Igniter from Book Matches164: "Red or White Powder" Propellant165: Pipe Hand Grenade166: European Credit Card Fraud (Written by Creditman! A Cookbook IV Recap!!)167: Potassium Bomb168: Your Legal Rights (For adults, or some of us think we are)169: Juvenile Offenders' Rights170: Down The Road Missle171: Fun With ShotGunn Shells172: Surveillance Equipment173: Drip Timer174: Stealing175: Miscellaneous176: Shaving cream bomb177: Ripping off change machines 2178: Lockpicking the EASY way179: Anarchy 'N' Explosives Prelude180: Anarchy 'N' Explosives Vol. 1181: Anarchy 'N' Explosives Vol. 2182: Anarchy 'N' Explosives Vol. 3183: Anarchy 'N' Explosives Vol. 4184: Anarchy 'N' Explosives Vol. 5185: Explosives and Propellants186: Lockpicking 3187: Chemical Equivalent List 2188: Nitroglycerin 2189: Cellulose Nitrate190: Starter Explosives191: Flash Powder192: Exploding Pens193: Revised Pipe Bombs 4.14194: * SAFETY * A MUST READ!195: Ammonium TriIodide196: Sulfuric Acid / Ammonium Nitrate III197: Black Powder 3198: Nitrocellulose199: R.D.X. (Revised 4.14)200: The Black Gate BBS 201: ANFOS202: Picric Acid 2203: Bottled Explosives204: Dry Ice205: Fuses / Ignitors / Delays206: Film Canister Bombs207: Book Bombs208: Phone Bombs209: Special Ammunition210: Rocketry211: Pipe Cannon 2212: Smoke Bombs 4.14213: Firecrackers214: Suppliers II215: Lab-Raid Checklist216: Misc. Anarchy217: LockPicking 4218: Misc. Anarchy II219: -* THERMITE 4 Index of Additions to the Anarchist Cookbook
- Ripping off Coke Machines
- Build an original style zip gun
- Diary of a hacker part one
- Diary of a hacker part two
- How to create a new identity
- Findind Security Holes
- Hacking techniques
- Composite Rocket Fuels
- The Complete Social Engineering faq's
- Association Betting System
- The Beginners Betting System
- The Dream Racing System
- The NetProfits Racing Plan
- The Professional Betting System
- Unix Hacking Tutorial
- Extract from the New York Times
- Unix Hacking Commands
- Home Brew Blast Cannon
- Down The Road Missile
- Internet email security
- Pneumatic spud gun
- The School Stoppers Textbook
- The Big Book of Mischief
- Terror Handbook - 100% bombs and explosives
- Beginners guide to hacking and phreaking
- Easy Grenades/Rockets
- toilet bowl cleaner Bomb
- Blowgun
Adding Coinos.io REST Api end points support to BTCpayAPI. Here is what is implemented, tested and doumented so far.
Current REST APIs supported are now:
LND API https://lightning.engineering/api-docs/api/lnd/ BTCPay Greenfield API (v1) https://docs.btcpayserver.org/API/Greenfield/v1/ Hashicorp Vault API https://developer.hashicorp.com/vault/api-docs/secret/kv/kv-v1 Coinos.io API https://coinos.io/docs
Although this is PowerShell code, it is exclusively being developed and tested on Linux only.
Code is available at https://btcpayserver.sytes.net
-
@ b2d670de:907f9d4a
2024-12-02 21:24:45
onion-service-nostr-relays
A list of nostr relays exposed as onion services.
The list
| Relay name | Description | Onion url | Operator | Payment URL | Payment options | | --- | --- | --- | --- | --- | --- | | nostr.oxtr.dev | Same relay as clearnet relay nostr.oxtr.dev | ws://oxtrdevav64z64yb7x6rjg4ntzqjhedm5b5zjqulugknhzr46ny2qbad.onion | operator | N/A | N/A | | relay.snort.social | Same relay as clearnet relay relay.snort.social | wss://skzzn6cimfdv5e2phjc4yr5v7ikbxtn5f7dkwn5c7v47tduzlbosqmqd.onion | operator | N/A | N/A | | nostr.thesamecat.io | Same relay as clearnet relay nostr.thesamecat.io | ws://2jsnlhfnelig5acq6iacydmzdbdmg7xwunm4xl6qwbvzacw4lwrjmlyd.onion | operator | N/A | N/A | | nostr.land | The nostr.land paid relay (same as clearnet) | ws://nostrland2gdw7g3y77ctftovvil76vquipymo7tsctlxpiwknevzfid.onion | operator | Payment URL | BTC LN | | bitcoiner.social | No auth required, currently | ws://bitcoinr6de5lkvx4tpwdmzrdfdpla5sya2afwpcabjup2xpi5dulbad.onion | operator | N/A | N/A | | relay.westernbtc.com | The westernbtc.com paid relay | ws://westbtcebhgi4ilxxziefho6bqu5lqwa5ncfjefnfebbhx2cwqx5knyd.onion | operator | Payment URL | BTC LN | | freelay.sovbit.host | Free relay for sovbit.host | ws://sovbitm2enxfr5ot6qscwy5ermdffbqscy66wirkbsigvcshumyzbbqd.onion | operator | N/A | N/A | | nostr.sovbit.host | Paid relay for sovbit.host | ws://sovbitgz5uqyh7jwcsudq4sspxlj4kbnurvd3xarkkx2use3k6rlibqd.onion | operator | N/A | N/A | | nostr.wine | 🍷 nostr.wine relay | ws://nostrwinemdptvqukjttinajfeedhf46hfd5bz2aj2q5uwp7zros3nad.onion | operator | Payment URL | BTC LN, BTC, Credit Card/CashApp (Stripe) | | inbox.nostr.wine | 🍷 inbox.nostr.wine relay | ws://wineinboxkayswlofkugkjwhoyi744qvlzdxlmdvwe7cei2xxy4gc6ad.onion | operator | Payment URL | BTC LN, BTC | | filter.nostr.wine | 🍷 filter.nostr.wine proxy relay | ws://winefiltermhqixxzmnzxhrmaufpnfq3rmjcl6ei45iy4aidrngpsyid.onion | operator | Payment URL | BTC LN, BTC | | N/A | N/A | ws://pzfw4uteha62iwkzm3lycabk4pbtcr67cg5ymp5i3xwrpt3t24m6tzad.onion:81 | operator | N/A | N/A | | nostr.fractalized.net | Free relay for fractalized.net | ws://xvgox2zzo7cfxcjrd2llrkthvjs5t7efoalu34s6lmkqhvzvrms6ipyd.onion | operator | N/A | N/A | | nfrelay.app | nfrelay.app aggregator relay (nostr-filter-relay) | ws://nfrelay6saohkmipikquvrn6d64dzxivhmcdcj4d5i7wxis47xwsriyd.onion | operator | N/A | N/A | relay.nostr.net | Public relay from nostr.net (Same as clearnet) | ws://nostrnetl6yd5whkldj3vqsxyyaq3tkuspy23a3qgx7cdepb4564qgqd.onion | operator | N/A | N/A | | nerostrator | Free to read, pay XMR to relay | ws://nerostrrgb5fhj6dnzhjbgmnkpy2berdlczh6tuh2jsqrjok3j4zoxid.onion | operator |Payment URL | XMR | | nostr.girino.org | Public relay from nostr.girino.org | ws://gnostr2jnapk72mnagq3cuykfon73temzp77hcbncn4silgt77boruid.onion | operator | N/A | N/A | | wot.girino.org | WoT relay from wot.girino.org | ws://girwot2koy3kvj6fk7oseoqazp5vwbeawocb3m27jcqtah65f2fkl3yd.onion | operator | N/A | N/A | | haven.girino.org/{outbox, inbox, chat, private} | Haven smart relay from haven.girino.org | ws://ghaven2hi3qn2riitw7ymaztdpztrvmm337e2pgkacfh3rnscaoxjoad.onion/{outbox, inbox, chat, private} | operator | N/A | N/A | | relay.nostpy.lol | Free Web of Trust relay (Same as clearnet) | ws://pemgkkqjqjde7y2emc2hpxocexugbixp42o4zymznil6zfegx5nfp4id.onion | operator |N/A | N/A | | Poster.place Nostr Relay | N/A | ws://dmw5wbawyovz7fcahvguwkw4sknsqsalffwctioeoqkvvy7ygjbcuoad.onion | operator | N/A | N/A |
Contributing
Contributions are encouraged to keep this document alive. Just open a PR and I'll have it tested and merged. The onion URL is the only mandatory column, the rest is just nice-to-have metadata about the relay. Put
N/Ain empty columns.If you want to contribute anonymously, please contact me on SimpleX or send a DM on nostr using a disposable npub.
Operator column
It is generally preferred to use something that includes a NIP-19 string, either just the string or a url that contains the NIP-19 string in it (e.g. an njump url).
-
@ dab6c606:51f507b6
2025-04-18 14:59:25
Core idea: Use geotagged anonymized Nostr events with Cashu-based points to snitch on cop locations for a more relaxed driving and walking
We all know navigation apps. There's one of them that allows you to report on locations of cops. It's Waze and it's owned by Google. There are perfectly fine navigation apps like Organic Maps, that unfortunately lack the cop-snitching features. In some countries, it is illegal to report cop locations, so it would probably not be a good idea to use your npub to report them. But getting a points Cashu token as a reward and exchanging them from time to time would solve this. You can of course report construction, traffic jams, ...
Proposed solution: Add Nostr client (Copstr) to Organic Maps. Have a button in bottom right allowing you to report traffic situations. Geotagged events are published on Nostr relays, users sending cashu tokens as thank you if the report is valid. Notes have smart expiration times.
Phase 2: Automation: Integration with dashcams and comma.ai allow for automated AI recognition of traffic events such as traffic jams and cops, with automatic touchless reporting.
Result: Drive with most essential information and with full privacy. Collect points to be cool and stay cool.
-
@ 526bec6a:07c68d13
2025-05-05 08:06:09
Let’s talk about a straightforward betting strategy that’s been around for years, often used by folks who treat horse racing more like a business than a gamble. This method is all about following a clear staking plan to aim for a small, consistent profit per race—without needing to be a racing expert. I’ll break it down step-by-step so it’s easy to understand, even if you’re new to this! The Goal: Small, Steady Wins The idea here is to aim for a target profit (T) of 5 points per race. Think of a "point" as a unit of money you decide on—it could be $50, $1, or whatever you’re comfortable with. For example, I use a starting bank of $200, and I set each point at $1. So, 5 points = $5 profit per race. Important Rule: Once you pick the value of a point, stick with it throughout the entire betting sequence. Don’t change it, no matter what happens! Why This Works (Even If You Know Nothing About Racing) This plan is designed so that you’ll eventually win, even if you’re clueless about horses. The catch? You need to be patient and okay with small profits per point because the stakes (the amount you bet) can grow after each loss. For example: If you set each point at £1 and lose 10 races in a row, your 11th bet would need to recover $55 (your target plus losses). If you set each point at 25p, you’d only need to recover $13.75 after 10 losses. See the difference? Lower point values mean smaller risks, but also smaller profits. Pick a point value that matches the risk you’re willing to take and the profit you want to make. How the Staking Plan Works Here’s the basic idea: you start with a target profit of 5 points per race. If you lose, you add your loss to the next race’s target. If you win, you subtract your gain. The goal is to keep going until you hit your total profit target, then start over. Let’s break down the key terms: T (Target): Your profit goal for the race (starts at 5 points). T + L: Your target plus any losses from previous races (or minus any gains if you won). S (Stake): How much you bet on the race. R (Result): Whether you won (e.g., 2-1 means the horse paid 2-to-1 odds) or lost (L). W (Points Won): How many points you gained from a win. L (Points Lost): How many points you lost from a bet. AWL (Running Total): Your accumulated wins and losses over the sequence. Once you reach your overall profit goal (like 40 points in the example below), you take your winnings and start the sequence over with a 5-point target. Example Sequence: Watch It in Action Here’s a sample sequence to show how this plays out. I’m using a 1-per-point value for simplicity:What happened here? In Race 1, I aimed for 5 points but lost my 2-point stake, so my running total is -2. In Race 2, I added my loss (2) to the new target (10), so I’m aiming for 12 points. I lost again, so my running total drops to -6. By Race 8, I finally hit a big win (4-1 odds), gaining 44 points. My running total jumps to +50, which exceeds my overall target of 40 points. I take my profit ($50 if each point is $1) and start over in Race 9 with a 5-point target. How to Calculate Your Stake To figure out how much to bet (your stake), take your T + L (target plus losses) and divide by 3, rounding to the nearest whole number. Why 3? Because you want to bet on horses with odds of 3-1 or higher. A win at those odds will cover all your losses and give you your target profit. For example: In Race 4, my T + L is 33. Divide by 3: 33 ÷ 3 = 11. So, I bet 11 points. My horse wins at 2-1 odds, so I get 22 points back (11 × 2). This clears my losses and gives me a profit. Pro Tip: Stick to odds of evens (1-1) or higher. Many pros avoid “odds-on” bets (like 1-2) because they don’t pay enough to make this system work well. Tips to Make This Work for You Pick Your Races Wisely: You don’t have to bet on every race. Some pros bet on every race at a meeting (e.g., 6 races a day, 36 bets a week), but I recommend being selective. Consider using a professional tipping service for better picks—newspaper tips can be risky (one “expert” once picked 30 losers in a row!). Spread Your Bets: Use 3 or 4 different bookmakers. No single bookie will be happy if you keep winning over time. Account for Betting Tax (If Applicable): If there’s a tax on your bets, add it to your next race’s target. This way, the system covers the tax for you. Be Prepared for Losing Streaks: Even with careful picks, you might hit a string of losses. That’s why you keep your point value low—so your stakes don’t balloon too much. Why This Is a “Business,” Not Gambling People who use this method don’t see it as gambling—they treat racing like a business. The key is patience and discipline. A single win at 3-1 odds or higher will wipe out all your losses and deliver your target profit. It’s a slow grind, but it’s designed to keep you in the game long-term. Final Thoughts This staking plan is all about consistency and managing risk. Start with a small bank (like $200), set a point value you’re comfortable with (like 50 or 1), and stick to the rules. You don’t need to be a racing genius—just follow the system, bet smart, and wait for that big win to clear your slate and put profit in your pocket. Got questions or want to tweak this for your own style? Let me know, and I’ll help you fine-tune your approach! Happy betting!
-
@ 81cda509:ae345bd2
2024-12-01 06:01:54


@florian | Photographer
Studio-Shoot
“Know thyself” is a phrase attributed to the ancient Greek philosopher Socrates, and it has been a cornerstone of philosophical thought for centuries. It invites an individual to deeply examine their own thoughts, feelings, behaviors, and motivations in order to understand their true nature.
At its core, “Know thyself” encourages self-awareness - an understanding of who you truly are beneath the surface. This process of introspection can uncover your strengths, weaknesses, desires, fears, and values. It invites you to acknowledge your habits, biases, and patterns of thinking, so you can make more conscious choices in life.
Knowing yourself also involves understanding your place in the larger context of existence. It means recognizing how your actions and choices affect others and the world around you. This awareness can lead to greater empathy, a sense of interconnectedness, and a more authentic life, free from the distractions of societal expectations or superficial identities.
In a practical sense, knowing yourself might involve:
-
Self-reflection: Regularly taking time to reflect on your thoughts, feelings, and experiences.
-
Mindfulness: Practicing awareness of the present moment and observing your reactions without judgment.
-
Exploration: Being open to trying new things and learning from both successes and failures.
-
Seeking truth: Engaging in honest inquiry about your motivations, desires, and beliefs.
-
Growth: Continuously learning from your past and striving to align your actions with your inner values.
Ultimately, “Know thyself” is about cultivating a deep, honest understanding of who you are, which leads to a more fulfilled, intentional, and peaceful existence.
-
-
@ dd664d5e:5633d319
2025-05-05 07:47:50
Speak your truth, Nostr
I think that there's a difference in the decisions people make when they're True Believers, and when they've just been hired to do something, or they arrived much later and don't really get the point of the decisions. It's that way with any organization controlled by a protocol, such as a constitution, basic law, canon, or core specification.
The True Believers all eventually look like idiotic fanatics who can't "keep up with the cool kids", but they arrived there because they were looking for a solution to a particular problem that they were having. If you then change the solution, to solve some other problem, while destroying the solution that attracted them to the project, in the first place, then they'll be unhappy about it.
Being cool doesn't automatically make you right about everything, but you can simply have enough might to "change" what is right. Shift the goalposts so that the problem you are trying to solve is The Most Pressing Problem. Everyone still focused on the Original Problem is reduced to protesting and being called "difficult", "unhelpful", "uncooperative", "rude".
Why are they protesting? Why don't they just go with the flow? Look at us, we never protest. We are so nice! We're totally happy with the way things are going. We are always polite and elegant and regal. Only rude people complain.
Good vibes only.
-
@ a367f9eb:0633efea
2024-11-05 08:48:41
Last week, an investigation by Reuters revealed that Chinese researchers have been using open-source AI tools to build nefarious-sounding models that may have some military application.
The reporting purports that adversaries in the Chinese Communist Party and its military wing are taking advantage of the liberal software licensing of American innovations in the AI space, which could someday have capabilities to presumably harm the United States.
In a June paper reviewed by Reuters, six Chinese researchers from three institutions, including two under the People’s Liberation Army’s (PLA) leading research body, the Academy of Military Science (AMS), detailed how they had used an early version of Meta’s Llama as a base for what it calls “ChatBIT”.
The researchers used an earlier Llama 13B large language model (LLM) from Meta, incorporating their own parameters to construct a military-focused AI tool to gather and process intelligence, and offer accurate and reliable information for operational decision-making.
While I’m doubtful that today’s existing chatbot-like tools will be the ultimate battlefield for a new geopolitical war (queue up the computer-simulated war from the Star Trek episode “A Taste of Armageddon“), this recent exposé requires us to revisit why large language models are released as open-source code in the first place.
Added to that, should it matter that an adversary is having a poke around and may ultimately use them for some purpose we may not like, whether that be China, Russia, North Korea, or Iran?
The number of open-source AI LLMs continues to grow each day, with projects like Vicuna, LLaMA, BLOOMB, Falcon, and Mistral available for download. In fact, there are over one million open-source LLMs available as of writing this post. With some decent hardware, every global citizen can download these codebases and run them on their computer.
With regard to this specific story, we could assume it to be a selective leak by a competitor of Meta which created the LLaMA model, intended to harm its reputation among those with cybersecurity and national security credentials. There are potentially trillions of dollars on the line.
Or it could be the revelation of something more sinister happening in the military-sponsored labs of Chinese hackers who have already been caught attacking American infrastructure, data, and yes, your credit history?
As consumer advocates who believe in the necessity of liberal democracies to safeguard our liberties against authoritarianism, we should absolutely remain skeptical when it comes to the communist regime in Beijing. We’ve written as much many times.
At the same time, however, we should not subrogate our own critical thinking and principles because it suits a convenient narrative.
Consumers of all stripes deserve technological freedom, and innovators should be free to provide that to us. And open-source software has provided the very foundations for all of this.
Open-source matters When we discuss open-source software and code, what we’re really talking about is the ability for people other than the creators to use it.
The various licensing schemes – ranging from GNU General Public License (GPL) to the MIT License and various public domain classifications – determine whether other people can use the code, edit it to their liking, and run it on their machine. Some licenses even allow you to monetize the modifications you’ve made.
While many different types of software will be fully licensed and made proprietary, restricting or even penalizing those who attempt to use it on their own, many developers have created software intended to be released to the public. This allows multiple contributors to add to the codebase and to make changes to improve it for public benefit.
Open-source software matters because anyone, anywhere can download and run the code on their own. They can also modify it, edit it, and tailor it to their specific need. The code is intended to be shared and built upon not because of some altruistic belief, but rather to make it accessible for everyone and create a broad base. This is how we create standards for technologies that provide the ground floor for further tinkering to deliver value to consumers.
Open-source libraries create the building blocks that decrease the hassle and cost of building a new web platform, smartphone, or even a computer language. They distribute common code that can be built upon, assuring interoperability and setting standards for all of our devices and technologies to talk to each other.
I am myself a proponent of open-source software. The server I run in my home has dozens of dockerized applications sourced directly from open-source contributors on GitHub and DockerHub. When there are versions or adaptations that I don’t like, I can pick and choose which I prefer. I can even make comments or add edits if I’ve found a better way for them to run.
Whether you know it or not, many of you run the Linux operating system as the base for your Macbook or any other computer and use all kinds of web tools that have active repositories forked or modified by open-source contributors online. This code is auditable by everyone and can be scrutinized or reviewed by whoever wants to (even AI bots).
This is the same software that runs your airlines, powers the farms that deliver your food, and supports the entire global monetary system. The code of the first decentralized cryptocurrency Bitcoin is also open-source, which has allowed thousands of copycat protocols that have revolutionized how we view money.
You know what else is open-source and available for everyone to use, modify, and build upon?
PHP, Mozilla Firefox, LibreOffice, MySQL, Python, Git, Docker, and WordPress. All protocols and languages that power the web. Friend or foe alike, anyone can download these pieces of software and run them how they see fit.
Open-source code is speech, and it is knowledge.
We build upon it to make information and technology accessible. Attempts to curb open-source, therefore, amount to restricting speech and knowledge.
Open-source is for your friends, and enemies In the context of Artificial Intelligence, many different developers and companies have chosen to take their large language models and make them available via an open-source license.
At this very moment, you can click on over to Hugging Face, download an AI model, and build a chatbot or scripting machine suited to your needs. All for free (as long as you have the power and bandwidth).
Thousands of companies in the AI sector are doing this at this very moment, discovering ways of building on top of open-source models to develop new apps, tools, and services to offer to companies and individuals. It’s how many different applications are coming to life and thousands more jobs are being created.
We know this can be useful to friends, but what about enemies?
As the AI wars heat up between liberal democracies like the US, the UK, and (sluggishly) the European Union, we know that authoritarian adversaries like the CCP and Russia are building their own applications.
The fear that China will use open-source US models to create some kind of military application is a clear and present danger for many political and national security researchers, as well as politicians.
A bipartisan group of US House lawmakers want to put export controls on AI models, as well as block foreign access to US cloud servers that may be hosting AI software.
If this seems familiar, we should also remember that the US government once classified cryptography and encryption as “munitions” that could not be exported to other countries (see The Crypto Wars). Many of the arguments we hear today were invoked by some of the same people as back then.
Now, encryption protocols are the gold standard for many different banking and web services, messaging, and all kinds of electronic communication. We expect our friends to use it, and our foes as well. Because code is knowledge and speech, we know how to evaluate it and respond if we need to.
Regardless of who uses open-source AI, this is how we should view it today. These are merely tools that people will use for good or ill. It’s up to governments to determine how best to stop illiberal or nefarious uses that harm us, rather than try to outlaw or restrict building of free and open software in the first place.
Limiting open-source threatens our own advancement If we set out to restrict and limit our ability to create and share open-source code, no matter who uses it, that would be tantamount to imposing censorship. There must be another way.
If there is a “Hundred Year Marathon” between the United States and liberal democracies on one side and autocracies like the Chinese Communist Party on the other, this is not something that will be won or lost based on software licenses. We need as much competition as possible.
The Chinese military has been building up its capabilities with trillions of dollars’ worth of investments that span far beyond AI chatbots and skip logic protocols.
The theft of intellectual property at factories in Shenzhen, or in US courts by third-party litigation funding coming from China, is very real and will have serious economic consequences. It may even change the balance of power if our economies and countries turn to war footing.
But these are separate issues from the ability of free people to create and share open-source code which we can all benefit from. In fact, if we want to continue our way our life and continue to add to global productivity and growth, it’s demanded that we defend open-source.
If liberal democracies want to compete with our global adversaries, it will not be done by reducing the freedoms of citizens in our own countries.
Last week, an investigation by Reuters revealed that Chinese researchers have been using open-source AI tools to build nefarious-sounding models that may have some military application.
The reporting purports that adversaries in the Chinese Communist Party and its military wing are taking advantage of the liberal software licensing of American innovations in the AI space, which could someday have capabilities to presumably harm the United States.
In a June paper reviewed by Reuters, six Chinese researchers from three institutions, including two under the People’s Liberation Army’s (PLA) leading research body, the Academy of Military Science (AMS), detailed how they had used an early version of Meta’s Llama as a base for what it calls “ChatBIT”.
The researchers used an earlier Llama 13B large language model (LLM) from Meta, incorporating their own parameters to construct a military-focused AI tool to gather and process intelligence, and offer accurate and reliable information for operational decision-making.
While I’m doubtful that today’s existing chatbot-like tools will be the ultimate battlefield for a new geopolitical war (queue up the computer-simulated war from the Star Trek episode “A Taste of Armageddon“), this recent exposé requires us to revisit why large language models are released as open-source code in the first place.
Added to that, should it matter that an adversary is having a poke around and may ultimately use them for some purpose we may not like, whether that be China, Russia, North Korea, or Iran?
The number of open-source AI LLMs continues to grow each day, with projects like Vicuna, LLaMA, BLOOMB, Falcon, and Mistral available for download. In fact, there are over one million open-source LLMs available as of writing this post. With some decent hardware, every global citizen can download these codebases and run them on their computer.
With regard to this specific story, we could assume it to be a selective leak by a competitor of Meta which created the LLaMA model, intended to harm its reputation among those with cybersecurity and national security credentials. There are potentially trillions of dollars on the line.
Or it could be the revelation of something more sinister happening in the military-sponsored labs of Chinese hackers who have already been caught attacking American infrastructure, data, and yes, your credit history?
As consumer advocates who believe in the necessity of liberal democracies to safeguard our liberties against authoritarianism, we should absolutely remain skeptical when it comes to the communist regime in Beijing. We’ve written as much many times.
At the same time, however, we should not subrogate our own critical thinking and principles because it suits a convenient narrative.
Consumers of all stripes deserve technological freedom, and innovators should be free to provide that to us. And open-source software has provided the very foundations for all of this.
Open-source matters
When we discuss open-source software and code, what we’re really talking about is the ability for people other than the creators to use it.
The various licensing schemes – ranging from GNU General Public License (GPL) to the MIT License and various public domain classifications – determine whether other people can use the code, edit it to their liking, and run it on their machine. Some licenses even allow you to monetize the modifications you’ve made.
While many different types of software will be fully licensed and made proprietary, restricting or even penalizing those who attempt to use it on their own, many developers have created software intended to be released to the public. This allows multiple contributors to add to the codebase and to make changes to improve it for public benefit.
Open-source software matters because anyone, anywhere can download and run the code on their own. They can also modify it, edit it, and tailor it to their specific need. The code is intended to be shared and built upon not because of some altruistic belief, but rather to make it accessible for everyone and create a broad base. This is how we create standards for technologies that provide the ground floor for further tinkering to deliver value to consumers.
Open-source libraries create the building blocks that decrease the hassle and cost of building a new web platform, smartphone, or even a computer language. They distribute common code that can be built upon, assuring interoperability and setting standards for all of our devices and technologies to talk to each other.
I am myself a proponent of open-source software. The server I run in my home has dozens of dockerized applications sourced directly from open-source contributors on GitHub and DockerHub. When there are versions or adaptations that I don’t like, I can pick and choose which I prefer. I can even make comments or add edits if I’ve found a better way for them to run.
Whether you know it or not, many of you run the Linux operating system as the base for your Macbook or any other computer and use all kinds of web tools that have active repositories forked or modified by open-source contributors online. This code is auditable by everyone and can be scrutinized or reviewed by whoever wants to (even AI bots).
This is the same software that runs your airlines, powers the farms that deliver your food, and supports the entire global monetary system. The code of the first decentralized cryptocurrency Bitcoin is also open-source, which has allowed thousands of copycat protocols that have revolutionized how we view money.
You know what else is open-source and available for everyone to use, modify, and build upon?
PHP, Mozilla Firefox, LibreOffice, MySQL, Python, Git, Docker, and WordPress. All protocols and languages that power the web. Friend or foe alike, anyone can download these pieces of software and run them how they see fit.
Open-source code is speech, and it is knowledge.
We build upon it to make information and technology accessible. Attempts to curb open-source, therefore, amount to restricting speech and knowledge.
Open-source is for your friends, and enemies
In the context of Artificial Intelligence, many different developers and companies have chosen to take their large language models and make them available via an open-source license.
At this very moment, you can click on over to Hugging Face, download an AI model, and build a chatbot or scripting machine suited to your needs. All for free (as long as you have the power and bandwidth).
Thousands of companies in the AI sector are doing this at this very moment, discovering ways of building on top of open-source models to develop new apps, tools, and services to offer to companies and individuals. It’s how many different applications are coming to life and thousands more jobs are being created.
We know this can be useful to friends, but what about enemies?
As the AI wars heat up between liberal democracies like the US, the UK, and (sluggishly) the European Union, we know that authoritarian adversaries like the CCP and Russia are building their own applications.
The fear that China will use open-source US models to create some kind of military application is a clear and present danger for many political and national security researchers, as well as politicians.
A bipartisan group of US House lawmakers want to put export controls on AI models, as well as block foreign access to US cloud servers that may be hosting AI software.
If this seems familiar, we should also remember that the US government once classified cryptography and encryption as “munitions” that could not be exported to other countries (see The Crypto Wars). Many of the arguments we hear today were invoked by some of the same people as back then.
Now, encryption protocols are the gold standard for many different banking and web services, messaging, and all kinds of electronic communication. We expect our friends to use it, and our foes as well. Because code is knowledge and speech, we know how to evaluate it and respond if we need to.
Regardless of who uses open-source AI, this is how we should view it today. These are merely tools that people will use for good or ill. It’s up to governments to determine how best to stop illiberal or nefarious uses that harm us, rather than try to outlaw or restrict building of free and open software in the first place.
Limiting open-source threatens our own advancement
If we set out to restrict and limit our ability to create and share open-source code, no matter who uses it, that would be tantamount to imposing censorship. There must be another way.
If there is a “Hundred Year Marathon” between the United States and liberal democracies on one side and autocracies like the Chinese Communist Party on the other, this is not something that will be won or lost based on software licenses. We need as much competition as possible.
The Chinese military has been building up its capabilities with trillions of dollars’ worth of investments that span far beyond AI chatbots and skip logic protocols.
The theft of intellectual property at factories in Shenzhen, or in US courts by third-party litigation funding coming from China, is very real and will have serious economic consequences. It may even change the balance of power if our economies and countries turn to war footing.
But these are separate issues from the ability of free people to create and share open-source code which we can all benefit from. In fact, if we want to continue our way our life and continue to add to global productivity and growth, it’s demanded that we defend open-source.
If liberal democracies want to compete with our global adversaries, it will not be done by reducing the freedoms of citizens in our own countries.
Originally published on the website of the Consumer Choice Center.
-
@ c4b5369a:b812dbd6
2025-04-15 07:26:16
Offline transactions with Cashu
Over the past few weeks, I've been busy implementing offline capabilities into nutstash. I think this is one of the key value propositions of ecash, beinga a bearer instrument that can be used without internet access.
 It does however come with limitations, which can lead to a bit of confusion. I hope this article will clear some of these questions up for you!
It does however come with limitations, which can lead to a bit of confusion. I hope this article will clear some of these questions up for you!What is ecash/Cashu?
Ecash is the first cryptocurrency ever invented. It was created by David Chaum in 1983. It uses a blind signature scheme, which allows users to prove ownership of a token without revealing a link to its origin. These tokens are what we call ecash. They are bearer instruments, meaning that anyone who possesses a copy of them, is considered the owner.
Cashu is an implementation of ecash, built to tightly interact with Bitcoin, more specifically the Bitcoin lightning network. In the Cashu ecosystem,
Mintsare the gateway to the lightning network. They provide the infrastructure to access the lightning network, pay invoices and receive payments. Instead of relying on a traditional ledger scheme like other custodians do, the mint issues ecash tokens, to represent the value held by the users.How do normal Cashu transactions work?
A Cashu transaction happens when the sender gives a copy of his ecash token to the receiver. This can happen by any means imaginable. You could send the token through email, messenger, or even by pidgeon. One of the common ways to transfer ecash is via QR code.
The transaction is however not finalized just yet! In order to make sure the sender cannot double-spend their copy of the token, the receiver must do what we call a
swap. A swap is essentially exchanging an ecash token for a new one at the mint, invalidating the old token in the process. This ensures that the sender can no longer use the same token to spend elsewhere, and the value has been transferred to the receiver.
What about offline transactions?
Sending offline
Sending offline is very simple. The ecash tokens are stored on your device. Thus, no internet connection is required to access them. You can litteraly just take them, and give them to someone. The most convenient way is usually through a local transmission protocol, like NFC, QR code, Bluetooth, etc.
The one thing to consider when sending offline is that ecash tokens come in form of "coins" or "notes". The technical term we use in Cashu is
Proof. It "proofs" to the mint that you own a certain amount of value. Since these proofs have a fixed value attached to them, much like UTXOs in Bitcoin do, you would need proofs with a value that matches what you want to send. You can mix and match multiple proofs together to create a token that matches the amount you want to send. But, if you don't have proofs that match the amount, you would need to go online and swap for the needed proofs at the mint.Another limitation is, that you cannot create custom proofs offline. For example, if you would want to lock the ecash to a certain pubkey, or add a timelock to the proof, you would need to go online and create a new custom proof at the mint.
Receiving offline
You might think: well, if I trust the sender, I don't need to be swapping the token right away!
You're absolutely correct. If you trust the sender, you can simply accept their ecash token without needing to swap it immediately.
This is already really useful, since it gives you a way to receive a payment from a friend or close aquaintance without having to worry about connectivity. It's almost just like physical cash!
It does however not work if the sender is untrusted. We have to use a different scheme to be able to receive payments from someone we don't trust.
Receiving offline from an untrusted sender
To be able to receive payments from an untrusted sender, we need the sender to create a custom proof for us. As we've seen before, this requires the sender to go online.
The sender needs to create a token that has the following properties, so that the receciver can verify it offline:
- It must be locked to ONLY the receiver's public key
- It must include an
offline signature proof(DLEQ proof) - If it contains a timelock & refund clause, it must be set to a time in the future that is acceptable for the receiver
- It cannot contain duplicate proofs (double-spend)
- It cannot contain proofs that the receiver has already received before (double-spend)

If all of these conditions are met, then the receiver can verify the proof offline and accept the payment. This allows us to receive payments from anyone, even if we don't trust them.
At first glance, this scheme seems kinda useless. It requires the sender to go online, which defeats the purpose of having an offline payment system.
I beleive there are a couple of ways this scheme might be useful nonetheless:
-
Offline vending machines: Imagine you have an offline vending machine that accepts payments from anyone. The vending machine could use this scheme to verify payments without needing to go online itself. We can assume that the sender is able to go online and create a valid token, but the receiver doesn't need to be online to verify it.
-
Offline marketplaces: Imagine you have an offline marketplace where buyers and sellers can trade goods and services. Before going to the marketplace the sender already knows where he will be spending the money. The sender could create a valid token before going to the marketplace, using the merchants public key as a lock, and adding a refund clause to redeem any unspent ecash after it expires. In this case, neither the sender nor the receiver needs to go online to complete the transaction.
How to use this
Pretty much all cashu wallets allow you to send tokens offline. This is because all that the wallet needs to do is to look if it can create the desired amount from the proofs stored locally. If yes, it will automatically create the token offline.
Receiving offline tokens is currently only supported by nutstash (experimental).
To create an offline receivable token, the sender needs to lock it to the receiver's public key. Currently there is no refund clause! So be careful that you don't get accidentally locked out of your funds!

The receiver can then inspect the token and decide if it is safe to accept without a swap. If all checks are green, they can accept the token offline without trusting the sender.

The receiver will see the unswapped tokens on the wallet homescreen. They will need to manually swap them later when they are online again.
 Later when the receiver is online again, they can swap the token for a fresh one.
Later when the receiver is online again, they can swap the token for a fresh one.
Summary
We learned that offline transactions are possible with ecash, but there are some limitations. It either requires trusting the sender, or relying on either the sender or receiver to be online to verify the tokens, or create tokens that can be verified offline by the receiver.
I hope this short article was helpful in understanding how ecash works and its potential for offline transactions.
Cheers,
Gandlaf
-
@ 09fbf8f3:fa3d60f0
2024-11-02 08:00:29
> ### 第三方API合集:
免责申明:
在此推荐的 OpenAI API Key 由第三方代理商提供,所以我们不对 API Key 的 有效性 和 安全性 负责,请你自行承担购买和使用 API Key 的风险。
| 服务商 | 特性说明 | Proxy 代理地址 | 链接 | | --- | --- | --- | --- | | AiHubMix | 使用 OpenAI 企业接口,全站模型价格为官方 86 折(含 GPT-4 )| https://aihubmix.com/v1 | 官网 | | OpenAI-HK | OpenAI的API官方计费模式为,按每次API请求内容和返回内容tokens长度来定价。每个模型具有不同的计价方式,以每1,000个tokens消耗为单位定价。其中1,000个tokens约为750个英文单词(约400汉字)| https://api.openai-hk.com/ | 官网 | | CloseAI | CloseAI是国内规模最大的商用级OpenAI代理平台,也是国内第一家专业OpenAI中转服务,定位于企业级商用需求,面向企业客户的线上服务提供高质量稳定的官方OpenAI API 中转代理,是百余家企业和多家科研机构的专用合作平台。 | https://api.openai-proxy.org | 官网 | | OpenAI-SB | 需要配合Telegram 获取api key | https://api.openai-sb.com | 官网 |
持续更新。。。
推广:
访问不了openai,去
低调云购买VPN。官网:https://didiaocloud.xyz
邀请码:
w9AjVJit价格低至1元。
-
@ 502ab02a:a2860397
2025-05-05 07:36:59
แค่ลดการ spike แต่ไม่ได้หายไปไหน เฮียขอเล่าเรื่องผับ... ไม่ใช่ผับที่มีไฟสลัว ๆ เสียงเบสแน่น ๆ หรอกนะ แต่เป็น “ผับร่างกาย” ที่เปิดประตูรับแขกชื่อ “น้ำตาล” เข้าไปทุกวันแบบไม่รู้ตัว
ในโลกของสุขภาพ น้ำตาลก็เหมือนวัยรุ่นที่ชอบเข้าไปในผับหลังมืดค่ำทุกคืน ส่วน อินซูลิน ก็คือพีอาร์หน้าผับ มีหน้าที่เปิดประตูให้เด็กพวกนี้เข้าไปในเซลล์ พอวัยรุ่นแห่มาพร้อมกัน อินซูลินก็ต้องเร่งเปิดประตูรัว ๆ นั่นแหละที่เขาเรียกกันว่า insulin spike
หลายคนรู้ว่า spike บ่อย ๆ ไม่ดี เลยพยายามหาวิธี “ลด spike” บางคนดื่มน้ำส้มสายชูแอปเปิ้ล (ACV) บางคนกินผักใยสูงก่อนอาหาร บางคนจัดซุปใส่ไฟเบอร์แบบคุม ๆ มาเสริม เฮียบอกเลยว่า “ดี” อยู่ครับ... แต่ หลายคนเข้าใจว่า การลด spike เท่ากับการลดน้ำตาล จริง ๆ แล้วน้ำตาลไม่ได้หายไปไหนเลย มันแค่ เดินเข้าช้าลงเท่านั้นเอง
ลองนึกภาพตามนะเฮียจะเล่าให้ฟัง...เอาแบบเห็นภาพร่างนะ เปรียบเปรยเปรียบเปรย
ผับเปิด... วัยรุ่นต่อแถว ทุกครั้งที่เรากินคาร์บ โดยเฉพาะแป้งหรือของหวาน ร่างกายก็จะแปลงมันเป็นกลูโคส หรือน้ำตาลในกระแสเลือด เจ้ากลูโคสเหล่านี้ก็จะมาต่อแถวเข้า “ผับเซลล์” พอคนเยอะ อินซูลินก็ต้องออกมาทำงานหนัก พาแต่ละคนเข้าไปจัดสรรให้เรียบร้อย ทีนี้ถ้าน้ำตาลมาก และมาพร้อมกัน อินซูลินก็ต้อง “spike” คือพุ่งขึ้นเพื่อจัดการด่วน ซึ่งถ้าร่างกายทำแบบนี้บ่อย ๆ ไม่ดีเลย เพราะมันทำให้ระบบเสื่อม เกิด ภาวะดื้ออินซูลิน นึภภาพพนักงานทำงานกันแบบ ปาร์ตี้คืนวันสงกรานต์ในผับย่าน อาร์ซีเอ หรือข้าวสาร สุดท้ายก็มักนำไปสู่เบาหวาน ความอ้วน และความเสื่อมแบบค่อยเป็นค่อยไป
ACV, ไฟเบอร์ช่วยไหม? ช่วย แต่ไม่ได้ลดน้ำตาล เทคนิคกินผักก่อน กินน้ำส้มสายชู หรือเพิ่มไฟเบอร์สูง ๆ ก่อนคาร์บ มันช่วย ชะลอการดูดซึม ของน้ำตาลจริง ๆ เหมือนกับมีการ์ดหน้าผับมาตรวจบัตรก่อนเข้าทีละคน แถวมันเลยไม่กรูกันเข้าแบบม็อบ แต่มาเรื่อย ๆ ทีละคน ๆ พีอาร์หน้าประตูก็จัดการระบบได้เบาแรงขึ้น
ฟังดูดีใช่ไหม? ใช่... แต่ ไม่ได้แปลว่าวัยรุ่นเหล่านั้นจะไม่เข้าผับ สุดท้าย พวกเขาก็เข้าไปครบเหมือนเดิมอยู่ดี นั่นคือ ร่างกายก็ยังได้รับน้ำตาลเท่าเดิมนั่นแหละ ... แค่เข้าช้าลงเท่านั้น
แล้วมันดีตรงไหนล่ะ ถ้ามันไม่ได้ลดน้ำตาล? มันดีตรงที่ spike จะไม่พุ่งเร็ว พอชะลอได้ อินซูลินก็ไม่ต้องทำงานแบบโหม ซึ่งในระยะสั้น มันช่วยให้ระดับน้ำตาลในเลือดไม่แกว่งจัดเกินไป ดีต่อสมอง ไม่ทำให้ง่วงหลังมื้ออาหาร
แต่ถ้าเรายังเลือกกินอาหารที่แปลงเป็นน้ำตาลเยอะ ๆ อยู่ดี แม้จะกินช้าลง ยังไงน้ำตาลก็สะสม เหมือนวัยรุ่นที่เข้าผับช้าลง แต่จำนวนก็เท่าเดิม เฮียว่าเราควรหันมาถามตัวเองว่า...
แล้วเราจะเปิดผับให้ใครบ้างดีล่ะ? การจัดการ spike ที่ดีที่สุดไม่ใช่แค่ “ชะลอ” แต่คือ “ลดปริมาณกลูโคสตั้งแต่ต้นทาง” เลือกกินของที่ไม่สร้างน้ำตาลพรึ่บพรั่บ เช่น real food ที่มีไขมันดีและโปรตีนสูง อย่างไข่ เนื้อสัตว์ เครื่องใน น้ำมันสัตว์ น้ำมันสกัดเย็นที่มีทั้งพฤกษเคมีและพลังงานที่ดี ฯลฯ ซึ่งเป็นการบริหารซอย จำกัดจำนวนนักเที่ยวแต่แรก เพราะพวกนี้ไม่พาน้ำตาลมากองหน้าประตูเหมือนขนมปังโพรเซส น้ำหวานจัดๆ หรือเค้กแป้งขัดสีน้ำตาลครีมเยอะๆ
เห็นไหมว่า เฮียไม่ได้บอกให้เลิกกินของอร่อยเลยนะ แต่จะบอกว่า... ถ้าเราเข้าใจว่า การลด spike ไม่ใช่การลดน้ำตาล เราจะวางแผนกินได้ดีกว่าเดิมเยอะ
การลด spike อินซูลินด้วยไฟเบอร์หรือ ACV เป็นวิธี ช่วยผ่อนแรง ให้ร่างกาย แต่ไม่ใช่การ “ลดปริมาณน้ำตาลที่เข้าสู่ร่างกาย” น้ำตาลยังคงเข้าเท่าเดิม และถ้าทำแบบนี้ทุกวัน ทุกมื้อ ก็เหมือนเปิดผับรับวัยรุ่นทุกคืน ต่อให้เข้าช้า แต่ก็ยังเข้าครบอยู่ดี
ถ้าอยากมีสุขภาพดีจริง ๆ ไม่ใช่แค่ใส่การ์ดคอยคุม แต่ต้องคัดตั้งแต่ต้นซอยเลยว่าซอยนี้เข้าได้แค่ไหนตั้งแต่แรก ถ้าแข็งแรงซอยใหญ่แบบทองหล่อทั้งซอย ก็รับนักเที่ยวได้มาก ถ้าป่วย ซอยเล็กแบบซอยแจ่มจันทร์ ก็รับนักเที่ยวได้น้อย ระหว่างนี้ถ้าอยากจะขยายซอยเปิดรับนักเที่ยว คุณจะคุมสารอาหาร ออกกำลังกาย ตากแดด พักผ่อน ยังไงก็เรื่องของคุณแล้ว เลือกตามจริต
เลือกกินแบบรู้ต้นทาง... อินซูลินจะได้พัก ร่างกายจะได้หายใจและสุขภาพเราจะได้แข็งแรงแบบไม่ต้องเหนื่อยกับการควบคุมทีละมื้อทุกวัน และจงจำไว้เสมอว่า ร่างกายนั้นเป็นความสัมพันธ์อันลึกล้ำพัวพันยิ่งกว่า threesome หลายเท่าตัว ยิ่งศึกษาจะยิ่งรู้ว่า การมองเพียงจุดใดจุดหนึ่งคือความผิดพลาดแบบไม่รู้ตัวได้ง่ายๆเลยครับ ดังนั้นจึงเห็นว่า เราควรแยกเรื่องของการ "ลดการ spike" ออกจาก "ลดปริมาณน้ำตาลเข้าร่าง" เพราะมันแค่ชะลอแต่ไม่ได้ทำให้ที่กินเข้าไปหายไปไหน
ร่างกายมันเก่งนะครับ คุณคิดว่าลักไก่มันง่ายขนาดนั้นเลยเหรอ
พักเรื่องน้ำมันไว้วันนึง พอดีมีคนถามต่อเนื่องมาจาก ACV #pirateketo #กูต้องรู้มั๊ย #ม้วนหางสิลูกแค่ลดการ spike แต่ไม่ได้หายไปไหน เฮียขอเล่าเรื่องผับ... ไม่ใช่ผับที่มีไฟสลัว ๆ เสียงเบสแน่น ๆ หรอกนะ แต่เป็น “ผับร่างกาย” ที่เปิดประตูรับแขกชื่อ “น้ำตาล” เข้าไปทุกวันแบบไม่รู้ตัว
ในโลกของสุขภาพ น้ำตาลก็เหมือนวัยรุ่นที่ชอบเข้าไปในผับหลังมืดค่ำทุกคืน ส่วน อินซูลิน ก็คือพีอาร์หน้าผับ มีหน้าที่เปิดประตูให้เด็กพวกนี้เข้าไปในเซลล์ พอวัยรุ่นแห่มาพร้อมกัน อินซูลินก็ต้องเร่งเปิดประตูรัว ๆ นั่นแหละที่เขาเรียกกันว่า insulin spike
หลายคนรู้ว่า spike บ่อย ๆ ไม่ดี เลยพยายามหาวิธี “ลด spike” บางคนดื่มน้ำส้มสายชูแอปเปิ้ล (ACV) บางคนกินผักใยสูงก่อนอาหาร บางคนจัดซุปใส่ไฟเบอร์แบบคุม ๆ มาเสริม เฮียบอกเลยว่า “ดี” อยู่ครับ... แต่ หลายคนเข้าใจว่า การลด spike เท่ากับการลดน้ำตาล จริง ๆ แล้วน้ำตาลไม่ได้หายไปไหนเลย มันแค่ เดินเข้าช้าลงเท่านั้นเอง
ลองนึกภาพตามนะเฮียจะเล่าให้ฟัง...เอาแบบเห็นภาพร่างนะ เปรียบเปรยเปรียบเปรย
ผับเปิด... วัยรุ่นต่อแถว ทุกครั้งที่เรากินคาร์บ โดยเฉพาะแป้งหรือของหวาน ร่างกายก็จะแปลงมันเป็นกลูโคส หรือน้ำตาลในกระแสเลือด เจ้ากลูโคสเหล่านี้ก็จะมาต่อแถวเข้า “ผับเซลล์” พอคนเยอะ อินซูลินก็ต้องออกมาทำงานหนัก พาแต่ละคนเข้าไปจัดสรรให้เรียบร้อย ทีนี้ถ้าน้ำตาลมาก และมาพร้อมกัน อินซูลินก็ต้อง “spike” คือพุ่งขึ้นเพื่อจัดการด่วน ซึ่งถ้าร่างกายทำแบบนี้บ่อย ๆ ไม่ดีเลย เพราะมันทำให้ระบบเสื่อม เกิด ภาวะดื้ออินซูลิน นึภภาพพนักงานทำงานกันแบบ ปาร์ตี้คืนวันสงกรานต์ในผับย่าน อาร์ซีเอ หรือข้าวสาร สุดท้ายก็มักนำไปสู่เบาหวาน ความอ้วน และความเสื่อมแบบค่อยเป็นค่อยไป
ACV, ไฟเบอร์ช่วยไหม? ช่วย แต่ไม่ได้ลดน้ำตาล เทคนิคกินผักก่อน กินน้ำส้มสายชู หรือเพิ่มไฟเบอร์สูง ๆ ก่อนคาร์บ มันช่วย ชะลอการดูดซึม ของน้ำตาลจริง ๆ เหมือนกับมีการ์ดหน้าผับมาตรวจบัตรก่อนเข้าทีละคน แถวมันเลยไม่กรูกันเข้าแบบม็อบ แต่มาเรื่อย ๆ ทีละคน ๆ พีอาร์หน้าประตูก็จัดการระบบได้เบาแรงขึ้น
ฟังดูดีใช่ไหม? ใช่... แต่ ไม่ได้แปลว่าวัยรุ่นเหล่านั้นจะไม่เข้าผับ สุดท้าย พวกเขาก็เข้าไปครบเหมือนเดิมอยู่ดี นั่นคือ ร่างกายก็ยังได้รับน้ำตาลเท่าเดิมนั่นแหละ ... แค่เข้าช้าลงเท่านั้น
แล้วมันดีตรงไหนล่ะ ถ้ามันไม่ได้ลดน้ำตาล? มันดีตรงที่ spike จะไม่พุ่งเร็ว พอชะลอได้ อินซูลินก็ไม่ต้องทำงานแบบโหม ซึ่งในระยะสั้น มันช่วยให้ระดับน้ำตาลในเลือดไม่แกว่งจัดเกินไป ดีต่อสมอง ไม่ทำให้ง่วงหลังมื้ออาหาร
แต่ถ้าเรายังเลือกกินอาหารที่แปลงเป็นน้ำตาลเยอะ ๆ อยู่ดี แม้จะกินช้าลง ยังไงน้ำตาลก็สะสม เหมือนวัยรุ่นที่เข้าผับช้าลง แต่จำนวนก็เท่าเดิม เฮียว่าเราควรหันมาถามตัวเองว่า...
แล้วเราจะเปิดผับให้ใครบ้างดีล่ะ? การจัดการ spike ที่ดีที่สุดไม่ใช่แค่ “ชะลอ” แต่คือ “ลดปริมาณกลูโคสตั้งแต่ต้นทาง” เลือกกินของที่ไม่สร้างน้ำตาลพรึ่บพรั่บ เช่น real food ที่มีไขมันดีและโปรตีนสูง อย่างไข่ เนื้อสัตว์ เครื่องใน น้ำมันสัตว์ น้ำมันสกัดเย็นที่มีทั้งพฤกษเคมีและพลังงานที่ดี ฯลฯ ซึ่งเป็นการบริหารซอย จำกัดจำนวนนักเที่ยวแต่แรก เพราะพวกนี้ไม่พาน้ำตาลมากองหน้าประตูเหมือนขนมปังโพรเซส น้ำหวานจัดๆ หรือเค้กแป้งขัดสีน้ำตาลครีมเยอะๆ
เห็นไหมว่า เฮียไม่ได้บอกให้เลิกกินของอร่อยเลยนะ แต่จะบอกว่า... ถ้าเราเข้าใจว่า การลด spike ไม่ใช่การลดน้ำตาล เราจะวางแผนกินได้ดีกว่าเดิมเยอะ
การลด spike อินซูลินด้วยไฟเบอร์หรือ ACV เป็นวิธี ช่วยผ่อนแรง ให้ร่างกาย แต่ไม่ใช่การ “ลดปริมาณน้ำตาลที่เข้าสู่ร่างกาย” น้ำตาลยังคงเข้าเท่าเดิม และถ้าทำแบบนี้ทุกวัน ทุกมื้อ ก็เหมือนเปิดผับรับวัยรุ่นทุกคืน ต่อให้เข้าช้า แต่ก็ยังเข้าครบอยู่ดี
ถ้าอยากมีสุขภาพดีจริง ๆ ไม่ใช่แค่ใส่การ์ดคอยคุม แต่ต้องคัดตั้งแต่ต้นซอยเลยว่าซอยนี้เข้าได้แค่ไหนตั้งแต่แรก ถ้าแข็งแรงซอยใหญ่แบบทองหล่อทั้งซอย ก็รับนักเที่ยวได้มาก ถ้าป่วย ซอยเล็กแบบซอยแจ่มจันทร์ ก็รับนักเที่ยวได้น้อย ระหว่างนี้ถ้าอยากจะขยายซอยเปิดรับนักเที่ยว คุณจะคุมสารอาหาร ออกกำลังกาย ตากแดด พักผ่อน ยังไงก็เรื่องของคุณแล้ว เลือกตามจริต
เลือกกินแบบรู้ต้นทาง... อินซูลินจะได้พัก ร่างกายจะได้หายใจและสุขภาพเราจะได้แข็งแรงแบบไม่ต้องเหนื่อยกับการควบคุมทีละมื้อทุกวัน และจงจำไว้เสมอว่า ร่างกายนั้นเป็นความสัมพันธ์อันลึกล้ำพัวพันยิ่งกว่า threesome หลายเท่าตัว ยิ่งศึกษาจะยิ่งรู้ว่า การมองเพียงจุดใดจุดหนึ่งคือความผิดพลาดแบบไม่รู้ตัวได้ง่ายๆเลยครับ ดังนั้นจึงเห็นว่า เราควรแยกเรื่องของการ "ลดการ spike" ออกจาก "ลดปริมาณน้ำตาลเข้าร่าง" เพราะมันแค่ชะลอแต่ไม่ได้ทำให้ที่กินเข้าไปหายไปไหน
ร่างกายมันเก่งนะครับ คุณคิดว่าลักไก่มันง่ายขนาดนั้นเลยเหรอ
พักเรื่องน้ำมันไว้วันนึง พอดีมีคนถามต่อเนื่องมาจาก ACV #pirateketo #กูต้องรู้มั๊ย #ม้วนหางสิลูก #siamstr
-
@ 005bc4de:ef11e1a2
2025-05-05 07:31:15
How does MSTR buy bitcoin without bumping the price?
Michael Saylor buys bitcoin and he has a handy tool to track his purchases, at, well, https://saylortracker.com
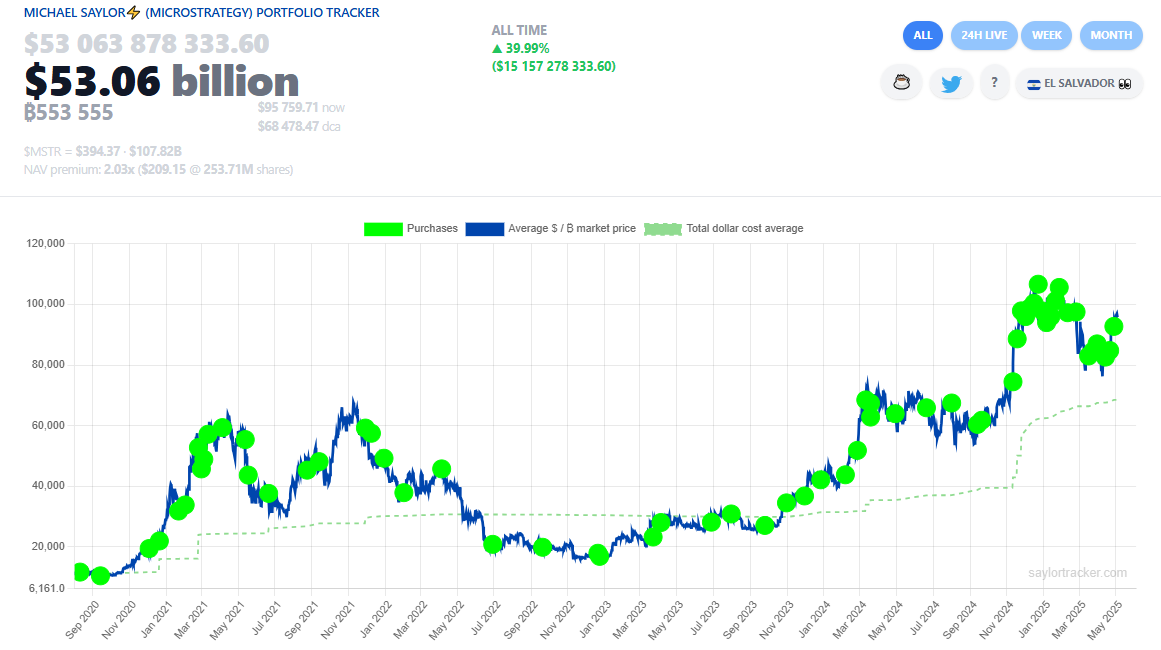
Mondays have been Saylor's buy-days, and rumors are that he may be at it again.
Yet, with all the mega-buying, why does it seem like the price doesn't jump? This is a question that comes to my mind seemingly each week now with the next MSTR buy.
Grok AI seems to imply that even though Saylor's purchases are huge, they're still not big enough to move the market. Average daily volume traded for BTC seems to be in the $15 billion upwards to $60 billion. So, Saylor's 1 to 2 or 4 billion dollar purchases evidently still aren't enough to eat up the order book.
This is a little hard to swallow considering that Grok estimated, "MicroStrategy owns approximately 2.81% of all Bitcoin in circulation and 2.64% of the total Bitcoin supply that will ever exist." I guess that other 97% is just moving their bitcoin around, back-and-forth?
The standard answer I've heard as to why the market doesn't move has been, "Oh, MSTR buys bitcoin over-the-counter, not off of exchanges where the prices come from."
That's a simple elevator-ride one sentence answer that seems plausible. I could meet someone on the street and say, "Hey, you got any bitcoin and do you wanna sell it?" If they said, "Yeah, and sure," then I could hand them some cash and they could send some BTC to me. The exchanges would be unmoved by this over the counter transaction.
Or, I might be interested in buying a Beanie Babie tie-dyed PEACE bear. The market, ebay, seems to list them around $8.99. But, if I buy a hundred of them off that bitcoin guy on the sidewalk, ebay and the price their isn't affected at all. Not are the 79 "watchers" keeping an eye on the PEACE bear.
But still, to me, that one-line OTC answer somehow seems off. Seriously, does Saylor have connections with people who want to sell thousands or tens of thousands of bitcoin? Every week? Who are these people with all that bitcoin to sell? Can Saylor connect me to a seller of 100 tie-dyed PEACE bears?
Maybe Saylor actually does have those kinds of connections to make those kinds of purchases. Or, maybe Grok is right and Saylor's moves aren't as big-fish as they seem. Anyway, I don't know, and those are circles that I don't move in. And, after all, I guess I still really don't know how he buys so much without moving the market.
!HBIT
-
@ 866e0139:6a9334e5
2025-05-05 06:18:34
\ \ Autor: Marcel Bühler. Dieser Beitrag wurde mit dem Pareto-Client geschrieben. Sie finden alle Texte der Friedenstaube und weitere Texte zum Thema Frieden hier. Die neuesten Pareto-Artikel finden Sie in unserem Telegram-Kanal.
Die neuesten Artikel der Friedenstaube gibt es jetzt auch im eigenen Friedenstaube-Telegram-Kanal.
"Die Ausrufung des Notstands ist der Notstand. Er eröffnet die Möglichkeit eines Endes der Rechtsstaatlichkeit"
Prof. em. Richard K. Sherwin NY Law School
Die von Präsident Donald Trump initiierten Friedensbemühungen zur Beendigung des russisch-ukrainischen Krieges scheinen keinen Erfolg zu bringen. Während Russland darauf beharrt, dass die im Herbst 2022 offiziell in die Russische Föderation aufgenommenenRegionen Lugansk, Donezk, Saporoschje und Cherson von der ukrainischen Armee vollständig geräumt werden, will Präsident Selenskij nicht einmal auf die Krim verzichten und deren Zugehörigkeit zu Russland seit 2014 anerkennen.
Während die Ukraine Sicherheitsgarantien für die Zeit nach einem möglichen Waffenstillstand bzw. Friedensabkommen fordert, besteht Russland weiterhin auf einer weitgehenden Demilitarisierung der ukrainischen Armee und besonders ein Verbot aller ultranationalen bzw. nazistischen Einheiten welche vor allem in der ukrainischen Nationalgarde konzentriert sind.
Nur ein Rohstoffdeal zwischen Washington und Kiew ist offenbar zustande gekommen, da Trump für die vielen Milliarden Dollar, welche in den letzten Jahren in die Ukraine "investiert" wurden, eine Gegenleistung bekommen möchte (nach dem "Ukraine Democracy Defense Lend-Lease Act" vom 19.1.2022 welcher von Präsident Biden am 9.5.2022 unterzeichnet wurde).
Im Rahmen einer Armeereform ist die Ukrainische Nationalgarde auf Anfang April 2025 in 2 Armeekorps mit je fünf Brigaden aufgeteilt worden: das erste Armeekorps wird von der 12. Brigade "Asow", das zweite Armeekorps von der 13. Brigade "Chartia" angeführt welche ursprünglich aus Freiwilligenbataillonen hervorgingen. Insgesamt dürfte es sich bei den 10 Brigaden um ca. 40'000 Mann handeln. Hier eine kurze Selbstdarstellung der Nationalgarde, in der auch der Kommandant, Alexander Pivnenko, zu Wort kommt (leider nur auf ukrainisch):
https://www.youtube.com/watch?v=0fjc6QHumcY
Alexander Syrskij, der aktuelle ukrainische Oberfehlshaber, hat kürzlich den Befehl erlassen, dass die mehr als 100'000 Mann der von der Bevölkerung gefürchteten Rekrutierungstruppe "TZK" ("Територіальний центр комплектування та соціальної підтримки") nun ebenfalls als Kampftruppen an die Front müssen, da die Mobilisierung weiterer ukrainischer Männer weitgehend gescheitert sei. Gleichzeitig wird über die Senkung des Mobilisierungsalters auf 18 Jahre und ein möglicher Einzug von Frauen diskutiert (die bereits als Freiwillige mitkämpfen).

Für die Zeit um den 9. Mai ("Tag des Sieges") hat Russland einen weiteren einseitigen Waffenstillstand ausgerufen, den die Ukrainer vermutlich wie an Ostern für Gegenangriffe an der Front oder Provokationen in Russland (z.B. Anschläge oder Drohnenangriffe in/auf Moskau nutzen werden). Über die Osterfeiertage hatten sich beide Seiten wie üblich gegenseitig beschuldigt, die verkündete Waffenruhe wiederholt gebrochen zu haben.
Die Kämpfe und die Opferung von Abertausenden dürften also bis auf weiteres weitergehen, auch wenn sie den Kriegsverlauf nicht mehr entscheidend ändern werden. Die Verlustrate beträgt aktuell ca. 1:10 zuungunsten der Ukrainer, da die Russen mittlerweile bei allen Waffensystemen überlegen sind, nicht nur bei der Artillerie und der Luftwaffe sondern auch im Bereich der Drohnen und der elektronischen Kriegsführung.
Wie es dazu kommen konnte, dass die Ukraine aus einem zwar hochkorrupten, aber relativ freien Land zu einem totalitären Militärregime wurde, zeigt ein neues Video eines jungen Ukrainers aus Mariupol, der die dortigen Kämpfe im Frühjahr 2022 im Keller überlebte und es aber vorzog, dort zu bleiben und die russische Staatsbürgerschaft anzunehmen. Aus Sicherheitsgründen nennt er seinen ukrainischen Namen nicht. Seine sachliche Darstellung ist weit davon entfernt, russische oder westliche Propaganda zu sein, sondern stellt eine nüchterne und auf persönlicher Erfahrung basierende Analyse der Ereignisse in der Ukraine seit 2014 dar.
Besonders eindrücklich zeigt er mit Filmmaterial auf, wie nach dem rechtswidrigen Putsch in Kiew, welcher von den Rechtsnationalen als "Revolution der Würde" bezeichnet wird und von Kräften aus dem Westen massiv unterstützt wurde (z.B. durch US-AID), besonders die ukrainische Jugend indoktriniert und militarisiert und auf den kommenden Krieg mit Russland vorbereitet wurde. Hier muss man unwillkürlich an die HJ (Hitler Jugend) denken, deren Schicksal am Ende des 2. WK allgemein bekannt sein dürfte. Es lohnt sich, den rund 35minütigen Beitrag zweimal anzusehen, um alles richtig zu verstehen und aufzunehmen (auf englisch mit slawischem Akzent):
https://www.youtube.com/watch?v=ba_NPxVXVyc
Den 1. Mai habe ich dieses Jahr am Stand der Schweizer Friedensbewegung im Areal der ehemaligen Stadt Zürcher Kaserne verbracht und dabei auch für den neu gegründeten Verein "Bewegung für Neutralität" (BENE) geworben. Der bekannte Friedensforscher Daniele Ganser wird diesen und nächsten Monat an den grossen Schweizer Bahnhöfen eine Plakatwerbung für die immerwährende Neutralität der Schweiz starten (siehe Entwurf im Anhang).
Zu Frieden und Völkerverständigung gibt es keine Alternative, dazu gehört auch das Studium und die Analyse des ukrainischen Nationalismus und Faschismus ("Stepan Bandera Ideologie"), dessen Ursprung und Entwicklung in den letzten rund 100 Jahren bis in die heutige Zeit.
Nur die Rüstungslobby kann mit der viel zitierten "Friedensdividende" nichts anfangen!
Marcel Bühler ist freier Mitarbeiter und Rechercheur aus Zürich. Dieser Beitrag erschien zuerst in seinem Newsletter.
LASSEN SIE DER FRIEDENSTAUBE FLÜGEL WACHSEN!
Hier können Sie die Friedenstaube abonnieren und bekommen die Artikel zugesandt.
Schon jetzt können Sie uns unterstützen:
- Für 50 CHF/EURO bekommen Sie ein Jahresabo der Friedenstaube.
- Für 120 CHF/EURO bekommen Sie ein Jahresabo und ein T-Shirt/Hoodie mit der Friedenstaube.
- Für 500 CHF/EURO werden Sie Förderer und bekommen ein lebenslanges Abo sowie ein T-Shirt/Hoodie mit der Friedenstaube.
- Ab 1000 CHF werden Sie Genossenschafter der Friedenstaube mit Stimmrecht (und bekommen lebenslanges Abo, T-Shirt/Hoodie).
Für Einzahlungen in CHF (Betreff: Friedenstaube):
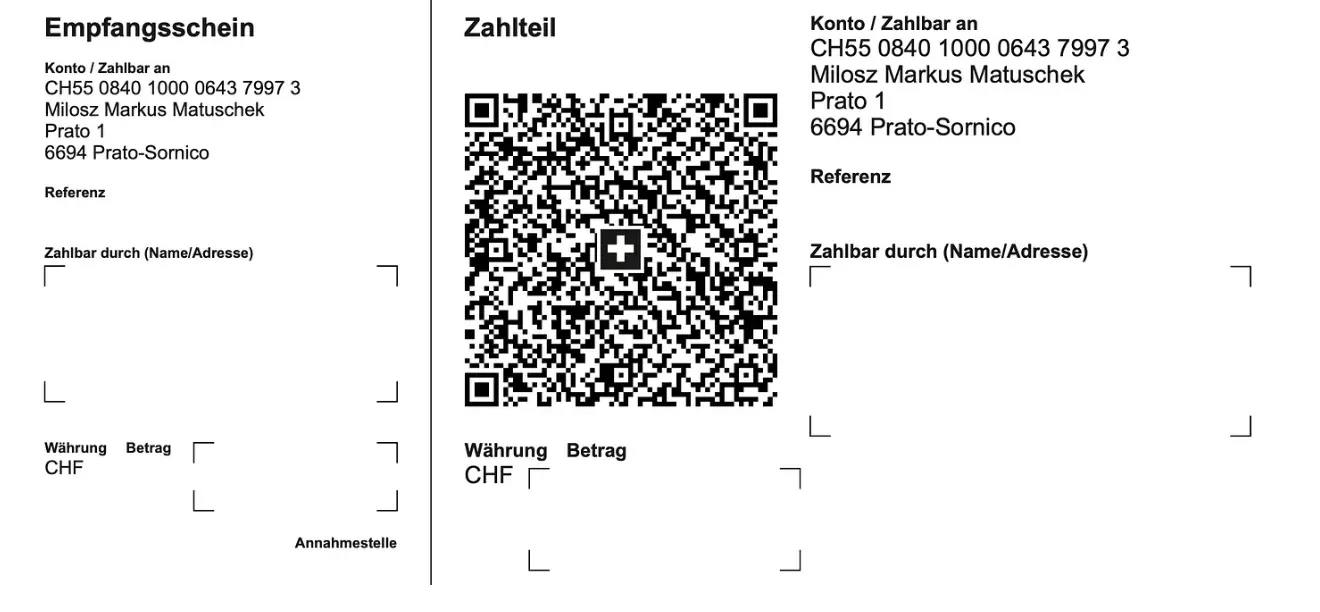
Für Einzahlungen in Euro:
Milosz Matuschek
IBAN DE 53710520500000814137
BYLADEM1TST
Sparkasse Traunstein-Trostberg
Betreff: Friedenstaube
Wenn Sie auf anderem Wege beitragen wollen, schreiben Sie die Friedenstaube an: friedenstaube@pareto.space
Sie sind noch nicht auf Nostr and wollen die volle Erfahrung machen (liken, kommentieren etc.)? Zappen können Sie den Autor auch ohne Nostr-Profil! Erstellen Sie sich einen Account auf Start. Weitere Onboarding-Leitfäden gibt es im Pareto-Wiki.
\
-
@ 57d1a264:69f1fee1
2025-05-05 05:26:34
The European Accessibility Act is coming, now is a great time for accessibility trainings!. In my Accessibility for Designer workshop, you will learn how to design accessible mockups that prevent issues in visual design, interactions, navigation, and content. You will be able to spot problems early, fix them in your designs, and communicate accessibility clearly with your team. This is a practical workshop with hands-on exercises, not just theory. You’ll actively apply accessibility principles to real design scenarios and mockups. And will get access to my accessibility resources: checklists, annotation kits and more.
When? 4 sessions of 2 hours + Q and As, on: - Mon, June 16, - Tue, June 17, Mon, - June 23 and Tue, - June 24. 9:30 – 12:00 PM PT or 18:30 – 21:00 CET
Register with 15% discount ($255) https://ti.to/smashingmagazine/online-workshops-2022/with/87vynaoqc0/discount/welcometomyworkshop
originally posted at https://stacker.news/items/971772
-
@ 4c48cf05:07f52b80
2024-10-30 01:03:42
I believe that five years from now, access to artificial intelligence will be akin to what access to the Internet represents today. It will be the greatest differentiator between the haves and have nots. Unequal access to artificial intelligence will exacerbate societal inequalities and limit opportunities for those without access to it.
Back in April, the AI Index Steering Committee at the Institute for Human-Centered AI from Stanford University released The AI Index 2024 Annual Report.
Out of the extensive report (502 pages), I chose to focus on the chapter dedicated to Public Opinion. People involved with AI live in a bubble. We all know and understand AI and therefore assume that everyone else does. But, is that really the case once you step out of your regular circles in Seattle or Silicon Valley and hit Main Street?
Two thirds of global respondents have a good understanding of what AI is
The exact number is 67%. My gut feeling is that this number is way too high to be realistic. At the same time, 63% of respondents are aware of ChatGPT so maybe people are confounding AI with ChatGPT?
If so, there is so much more that they won't see coming.
This number is important because you need to see every other questions and response of the survey through the lens of a respondent who believes to have a good understanding of what AI is.
A majority are nervous about AI products and services
52% of global respondents are nervous about products and services that use AI. Leading the pack are Australians at 69% and the least worried are Japanise at 23%. U.S.A. is up there at the top at 63%.
Japan is truly an outlier, with most countries moving between 40% and 60%.
Personal data is the clear victim
Exaclty half of the respondents believe that AI companies will protect their personal data. And the other half believes they won't.
Expected benefits
Again a majority of people (57%) think that it will change how they do their jobs. As for impact on your life, top hitters are getting things done faster (54%) and more entertainment options (51%).
The last one is a head scratcher for me. Are people looking forward to AI generated movies?

Concerns
Remember the 57% that thought that AI will change how they do their jobs? Well, it looks like 37% of them expect to lose it. Whether or not this is what will happen, that is a very high number of people who have a direct incentive to oppose AI.
Other key concerns include:
- Misuse for nefarious purposes: 49%
- Violation of citizens' privacy: 45%
Conclusion
This is the first time I come across this report and I wil make sure to follow future annual reports to see how these trends evolve.
Overall, people are worried about AI. There are many things that could go wrong and people perceive that both jobs and privacy are on the line.
Full citation: Nestor Maslej, Loredana Fattorini, Raymond Perrault, Vanessa Parli, Anka Reuel, Erik Brynjolfsson, John Etchemendy, Katrina Ligett, Terah Lyons, James Manyika, Juan Carlos Niebles, Yoav Shoham, Russell Wald, and Jack Clark, “The AI Index 2024 Annual Report,” AI Index Steering Committee, Institute for Human-Centered AI, Stanford University, Stanford, CA, April 2024.
The AI Index 2024 Annual Report by Stanford University is licensed under Attribution-NoDerivatives 4.0 International.
-
@ 57d1a264:69f1fee1
2025-05-05 05:15:02
Crabtree's Framework for Evaluating Human-Centered Research
Picture this: You've spent three weeks conducting qualitative research for a finance app redesign. You carefully recruited 12 participants, conducted in-depth interviews, and identified patterns around financial anxiety and decision paralysis. You're excited to present your findings when the inevitable happens:
"But are these results statistically significant?"
"Just 12 people? How can we make decisions that affect thousands of users based on conversations with just 12 people?"
As UX professionals, we regularly face stakeholders who evaluate our qualitative research using criteria designed for quantitative methods... This misalignment undermines the unique value qualitative research brings to product development.
Continue reading https://uxpsychology.substack.com/p/beyond-numbers-how-to-properly-evaluate
originally posted at https://stacker.news/items/971767
-
@ 09fbf8f3:fa3d60f0
2024-10-25 18:43:59
在线直播:
央视体育版CCTV5:
央视体育版CCTV16 :
翡翠台:
-
@ 826e9f89:ffc5c759
2025-04-12 21:34:24
What follows began as snippets of conversations I have been having for years, on and off, here and there. It will likely eventually be collated into a piece I have been meaning to write on “payments” as a whole. I foolishly started writing this piece years ago, not realizing that the topic is gargantuan and for every week I spend writing it I have to add two weeks to my plan. That may or may not ever come to fruition, but in the meantime, Tether announced it was issuing on Taproot Assets and suddenly everybody is interested again. This is as good a catalyst as any to carve out my “stablecoin thesis”, such as it exists, from “payments”, and put it out there for comment and feedback.
In contrast to the “Bitcoiner take” I will shortly revert to, I invite the reader to keep the following potential counterargument in mind, which might variously be termed the “shitcoiner”, “realist”, or “cynical” take, depending on your perspective: that stablecoins have clear product-market-fit. Now, as a venture capitalist and professional thinkboi focusing on companies building on Bitcoin, I obviously think that not only is Bitcoin the best money ever invented and its monetization is pretty much inevitable, but that, furthermore, there is enormous, era-defining long-term potential for a range of industries in which Bitcoin is emerging as superior technology, even aside from its role as money. But in the interest not just of steelmanning but frankly just of honesty, I would grudgingly agree with the following assessment as of the time of writing: the applications of crypto (inclusive of Bitcoin but deliberately wider) that have found product-market-fit today, and that are not speculative bets on future development and adoption, are: Bitcoin as savings technology, mining as a means of monetizing energy production, and stablecoins.
I think there are two typical Bitcoiner objections to stablecoins of significantly greater importance than all others: that you shouldn’t be supporting dollar hegemony, and that you don’t need a blockchain. I will elaborate on each of these, and for the remainder of the post will aim to produce a synthesis of three superficially contrasting (or at least not obviously related) sources of inspiration: these objections, the realisation above that stablecoins just are useful, and some commentary on technical developments in Bitcoin and the broader space that I think inform where things are likely to go. As will become clear as the argument progresses, I actually think the outcome to which I am building up is where things have to go. I think the technical and economic incentives at play make this an inevitability rather than a “choice”, per se. Given my conclusion, which I will hold back for the time being, this is a fantastically good thing, hence I am motivated to write this post at all!
Objection 1: Dollar Hegemony
I list this objection first because there isn’t a huge amount to say about it. It is clearly a normative position, and while I more or less support it personally, I don’t think that it is material to the argument I am going on to make, so I don’t want to force it on the reader. While the case for this objection is probably obvious to this audience (isn’t the point of Bitcoin to destroy central banks, not further empower them?) I should at least offer the steelman that there is a link between this and the realist observation that stablecoins are useful. The reason they are useful is because people prefer the dollar to even shitter local fiat currencies. I don’t think it is particularly fruitful to say that they shouldn’t. They do. Facts don’t care about your feelings. There is a softer bridging argument to be made here too, to the effect that stablecoins warm up their users to the concept of digital bearer (ish) assets, even though these particular assets are significantly scammier than Bitcoin. Again, I am just floating this, not telling the reader they should or shouldn’t buy into it.
All that said, there is one argument I do want to put my own weight behind, rather than just float: stablecoin issuance is a speculative attack on the institution of fractional reserve banking. A “dollar” Alice moves from JPMorgan to Tether embodies two trade-offs from Alice’s perspective: i) a somewhat opaque profile on the credit risk of the asset: the likelihood of JPMorgan ever really defaulting on deposits vs the operator risk of Tether losing full backing and/or being wrench attacked by the Federal Government and rugging its users. These risks are real but are almost entirely political. I’m skeptical it is meaningful to quantify them, but even if it is, I am not the person to try to do it. Also, more transparently to Alice, ii) far superior payment rails (for now, more on this to follow).
However, from the perspective of the fiat banking cartel, fractional reserve leverage has been squeezed. There are just as many notional dollars in circulation, but there the backing has been shifted from levered to unlevered issuers. There are gradations of relevant objections to this: while one might say, Tether’s backing comes from Treasuries, so you are directly funding US debt issuance!, this is a bit silly in the context of what other dollars one might hold. It’s not like JPMorgan is really competing with the Treasury to sell credit into the open market. Optically they are, but this is the core of the fiat scam. Via the guarantees of the Federal Reserve System, JPMorgan can sell as much unbacked credit as it wants knowing full well the difference will be printed whenever this blows up. Short-term Treasuries are also JPMorgan’s most pristine asset safeguarding its equity, so the only real difference is that Tether only holds Treasuries without wishing more leverage into existence. The realization this all builds up to is that, by necessity,
Tether is a fully reserved bank issuing fiduciary media against the only dollar-denominated asset in existence whose value (in dollar terms) can be guaranteed. Furthermore, this media arguably has superior “moneyness” to the obvious competition in the form of US commercial bank deposits by virtue of its payment rails.
That sounds pretty great when you put it that way! Of course, the second sentence immediately leads to the second objection, and lets the argument start to pick up steam …
Objection 2: You Don’t Need a Blockchain
I don’t need to explain this to this audience but to recap as briefly as I can manage: Bitcoin’s value is entirely endogenous. Every aspect of “a blockchain” that, out of context, would be an insanely inefficient or redundant modification of a “database”, in context is geared towards the sole end of enabling the stability of this endogenous value. Historically, there have been two variations of stupidity that follow a failure to grok this: i) “utility tokens”, or blockchains with native tokens for something other than money. I would recommend anybody wanting a deeper dive on the inherent nonsense of a utility token to read Only The Strong Survive, in particular Chapter 2, Crypto Is Not Decentralized, and the subsection, Everything Fights For Liquidity, and/or Green Eggs And Ham, in particular Part II, Decentralized Finance, Technically. ii) “real world assets” or, creating tokens within a blockchain’s data structure that are not intended to have endogenous value but to act as digital quasi-bearer certificates to some or other asset of value exogenous to this system. Stablecoins are in this second category.
RWA tokens definitionally have to have issuers, meaning some entity that, in the real world, custodies or physically manages both the asset and the record-keeping scheme for the asset. “The blockchain” is at best a secondary ledger to outsource ledger updates to public infrastructure such that the issuer itself doesn’t need to bother and can just “check the ledger” whenever operationally relevant. But clearly ownership cannot be enforced in an analogous way to Bitcoin, under both technical and social considerations. Technically, Bitcoin’s endogenous value means that whoever holds the keys to some or other UTXOs functionally is the owner. Somebody else claiming to be the owner is yelling at clouds. Whereas, socially, RWA issuers enter a contract with holders (whether legally or just in terms of a common-sense interpretation of the transaction) such that ownership of the asset issued against is entirely open to dispute. That somebody can point to “ownership” of the token may or may not mean anything substantive with respect to the physical reality of control of the asset, and how the issuer feels about it all.
And so, one wonders, why use a blockchain at all? Why doesn’t the issuer just run its own database (for the sake of argument with some or other signature scheme for verifying and auditing transactions) given it has the final say over issuance and redemption anyway? I hinted at an answer above: issuing on a blockchain outsources this task to public infrastructure. This is where things get interesting. While it is technically true, given the above few paragraphs, that, you don’t need a blockchain for that, you also don’t need to not use a blockchain for that. If you want to, you can.
This is clearly the case given stablecoins exist at all and have gone this route. If one gets too angry about not needing a blockchain for that, one equally risks yelling at clouds! And, in fact, one can make an even stronger argument, more so from the end users’ perspective. These products do not exist in a vacuum but rather compete with alternatives. In the case of stablecoins, the alternative is traditional fiat money, which, as stupid as RWAs on a blockchain are, is even dumber. It actually is just a database, except it’s a database that is extremely annoying to use, basically for political reasons because the industry managing these private databases form a cartel that never needs to innovate or really give a shit about its customers at all. In many, many cases, stablecoins on blockchains are dumb in the abstract, but superior to the alternative methods of holding and transacting in dollars existing in other forms. And note, this is only from Alice’s perspective of wanting to send and receive, not a rehashing of the fractional reserve argument given above. This is the essence of their product-market-fit. Yell at clouds all you like: they just are useful given the alternative usually is not Bitcoin, it’s JPMorgan’s KYC’d-up-the-wazoo 90s-era website, more than likely from an even less solvent bank.
So where does this get us? It might seem like we are back to “product-market-fit, sorry about that” with Bitcoiners yelling about feelings while everybody else makes do with their facts. However, I think we have introduced enough material to move the argument forward by incrementally incorporating the following observations, all of which I will shortly go into in more detail: i) as a consequence of making no technical sense with respect to what blockchains are for, today’s approach won’t scale; ii) as a consequence of short-termist tradeoffs around socializing costs, today’s approach creates an extremely unhealthy and arguably unnatural market dynamic in the issuer space; iii) Taproot Assets now exist and handily address both points i) and ii), and; iv) eCash is making strides that I believe will eventually replace even Taproot Assets.
To tease where all this is going, and to get the reader excited before we dive into much more detail: just as Bitcoin will eat all monetary premia, Lightning will likely eat all settlement, meaning all payments will gravitate towards routing over Lightning regardless of the denomination of the currency at the edges. Fiat payments will gravitate to stablecoins to take advantage of this; stablecoins will gravitate to TA and then to eCash, and all of this will accelerate hyperbitcoinization by “bitcoinizing” payment rails such that an eventual full transition becomes as simple as flicking a switch as to what denomination you want to receive.
I will make two important caveats before diving in that are more easily understood in light of having laid this groundwork: I am open to the idea that it won’t be just Lightning or just Taproot Assets playing the above roles. Without veering into forecasting the entire future development of Bitcoin tech, I will highlight that all that really matters here are, respectively: a true layer 2 with native hashlocks, and a token issuance scheme that enables atomic routing over such a layer 2 (or combination of such). For the sake of argument, the reader is welcome to swap in “Ark” and “RGB” for “Lightning” and “TA” both above and in all that follows. As far as I can tell, this makes no difference to the argument and is even exciting in its own right. However, for the sake of simplicity in presentation, I will stick to “Lightning” and “TA” hereafter.
1) Today’s Approach to Stablecoins Won’t Scale
This is the easiest to tick off and again doesn’t require much explanation to this audience. Blockchains fundamentally don’t scale, which is why Bitcoin’s UTXO scheme is a far better design than ex-Bitcoin Crypto’s’ account-based models, even entirely out of context of all the above criticisms. This is because Bitcoin transactions can be batched across time and across users with combinations of modes of spending restrictions that provide strong economic guarantees of correct eventual net settlement, if not perpetual deferral. One could argue this is a decent (if abstrusely technical) definition of “scaling” that is almost entirely lacking in Crypto.
What we see in ex-Bitcoin crypto is so-called “layer 2s” that are nothing of the sort, forcing stablecoin schemes in these environments into one of two equally poor design choices if usage is ever to increase: fees go higher and higher, to the point of economic unviability (and well past it) as blocks fill up, or move to much more centralized environments that increasingly are just databases, and hence which lose the benefits of openness thought to be gleaned by outsourcing settlement to public infrastructure. This could be in the form of punting issuance to a bullshit “layer 2” that is a really a multisig “backing” a private execution environment (to be decentralized any daw now) or an entirely different blockchain that is just pretending even less not to be a database to begin with. In a nutshell, this is a decent bottom-up explanation as to why Tron has the highest settlement of Tether.
This also gives rise to the weirdness of “gas tokens” - assets whose utility as money is and only is in the form of a transaction fee to transact a different kind of money. These are not quite as stupid as a “utility token,” given at least they are clearly fulfilling a monetary role and hence their artificial scarcity can be justified. But they are frustrating from Bitcoiners’ and users’ perspectives alike: users would prefer to pay transaction fees on dollars in dollars, but they can’t because the value of Ether, Sol, Tron, or whatever, is the string and bubblegum that hold their boondoggles together. And Bitcoiners wish this stuff would just go away and stop distracting people, whereas this string and bubblegum is proving transiently useful.
All in all, today’s approach is fine so long as it isn’t being used much. It has product-market fit, sure, but in the unenviable circumstance that, if it really starts to take off, it will break, and even the original users will find it unusable.
2) Today’s Approach to Stablecoins Creates an Untenable Market Dynamic
Reviving the ethos of you don’t need a blockchain for that, notice the following subtlety: while the tokens representing stablecoins have value to users, that value is not native to the blockchain on which they are issued. Tether can (and routinely does) burn tokens on Ethereum and mint them on Tron, then burn on Tron and mint on Solana, and so on. So-called blockchains “go down” and nobody really cares. This makes no difference whatsoever to Tether’s own accounting, and arguably a positive difference to users given these actions track market demand. But it is detrimental to the blockchain being switched away from by stripping it of “TVL” that, it turns out, was only using it as rails: entirely exogenous value that leaves as quickly as it arrived.
One underdiscussed and underappreciated implication of the fact that no value is natively running through the blockchain itself is that, in the current scheme, both the sender and receiver of a stablecoin have to trust the same issuer. This creates an extremely powerful network effect that, in theory, makes the first-to-market likely to dominate and in practice has played out exactly as this theory would suggest: Tether has roughly 80% of the issuance, while roughly 19% goes to the political carve-out of USDC that wouldn’t exist at all were it not for government interference. Everybody else combined makes up the final 1%.
So, Tether is a full reserve bank but also has to be everybody’s bank. This is the source of a lot of the discomfort with Tether, and which feeds into the original objection around dollar hegemony, that there is an ill-defined but nonetheless uneasy feeling that Tether is slowly morphing into a CBDC. I would argue this really has nothing to do with Tether’s own behavior but rather is a consequence of the market dynamic inevitably created by the current stablecoin scheme. There is no reason to trust any other bank because nobody really wants a bank, they just want the rails. They want something that will retain a nominal dollar value long enough to spend it again. They don’t care what tech it runs on and they don’t even really care about the issuer except insofar as having some sense they won’t get rugged.
Notice this is not how fiat works. Banks can, of course, settle between each other, thus enabling their users to send money to customers of other banks. This settlement function is actually the entire point of central banks, less the money printing and general corruption enabled (we might say, this was the historical point of central banks, which have since become irredeemably corrupted by this power). This process is clunkier than stablecoins, as covered above, but the very possibility of settlement means there is no gigantic network effect to being the first commercial issuer of dollar balances. If it isn’t too triggering to this audience, one might suggest that the money printer also removes the residual concern that your balances might get rugged! (or, we might again say, you guarantee you don’t get rugged in the short term by guaranteeing you do get rugged in the long term).
This is a good point at which to introduce the unsettling observation that broader fintech is catching on to the benefits of stablecoins without any awareness whatsoever of all the limitations I am outlining here. With the likes of Stripe, Wise, Robinhood, and, post-Trump, even many US megabanks supposedly contemplating issuing stablecoins (obviously within the current scheme, not the scheme I am building up to proposing), we are forced to boggle our minds considering how on earth settlement is going to work. Are they going to settle through Ether? Well, no, because i) Ether isn’t money, it’s … to be honest, I don’t think anybody really knows what it is supposed to be, or if they once did they aren’t pretending anymore, but anyway, Stripe certainly hasn’t figured that out yet so, ii) it won’t be possible to issue them on layer 1s as soon as there is any meaningful volume, meaning they will have to route through “bullshit layer 2 wrapped Ether token that is really already a kind of stablecoin for Ether.”
The way they are going to try to fix this (anybody wanna bet?) is routing through DEXes, which is so painfully dumb you should be laughing and, if you aren’t, I would humbly suggest you don’t get just how dumb it is. What this amounts to is plugging the gap of Ether’s lack of moneyness (and wrapped Ether’s hilarious lack of moneyness) with … drum roll … unknowable technical and counterparty risk and unpredictable cost on top of reverting to just being a database. So, in other words, all of the costs of using a blockchain when you don’t strictly need to, and none of the benefits. Stripe is going to waste billions of dollars getting sandwich attacked out of some utterly vanilla FX settlement it is facilitating for clients who have even less of an idea what is going on and why North Korea now has all their money, and will eventually realize they should have skipped their shitcoin phase and gone straight to understanding Bitcoin instead …
3) Bitcoin (and Taproot Assets) Fixes This
To tie together a few loose ends, I only threw in the hilariously stupid suggestion of settling through wrapped Ether on Ether on Ether in order to tee up the entirely sensible suggestion of settling through Lightning. Again, not that this will be new to this audience, but while issuance schemes have been around on Bitcoin for a long time, the breakthrough of Taproot Assets is essentially the ability to atomically route through Lightning.
I will admit upfront that this presents a massive bootstrapping challenge relative to the ex-Bitcoin Crypto approach, and it’s not obvious to me if or how this will be overcome. I include this caveat to make it clear I am not suggesting this is a given. It may not be, it’s just beyond the scope of this post (or frankly my ability) to predict. This is a problem for Lightning Labs, Tether, and whoever else decides to step up to issue. But even highlighting this as an obvious and major concern invites us to consider an intriguing contrast: scaling TA stablecoins is hardest at the start and gets easier and easier thereafter. The more edge liquidity there is in TA stables, the less of a risk it is for incremental issuance; the more TA activity, the more attractive deploying liquidity is into Lightning proper, and vice versa. With apologies if this metaphor is even more confusing than it is helpful, one might conceive of the situation as being that there is massive inertia to bootstrap, but equally there could be positive feedback in driving the inertia to scale. Again, I have no idea, and it hasn’t happened yet in practice, but in theory it’s fun.
More importantly to this conversation, however, this is almost exactly the opposite dynamic to the current scheme on other blockchains, which is basically free to start, but gets more and more expensive the more people try to use it. One might say it antiscales (I don’t think that’s a real word, but if Taleb can do it, then I can do it too!).
Furthermore, the entire concept of “settling in Bitcoin” makes perfect sense both economically and technically: economically because Bitcoin is money, and technically because it can be locked in an HTLC and hence can enable atomic routing (i.e. because Lightning is a thing). This is clearly better than wrapped Eth on Eth on Eth or whatever, but, tantalisingly, is better than fiat too! The core message of the payments tome I may or may not one day write is (or will be) that fiat payments, while superficially efficient on the basis of centralized and hence costless ledger amendments, actually have a hidden cost in the form of interbank credit. Many readers will likely have heard me say this multiple times and in multiple settings but, contrary to popular belief, there is no such thing as a fiat debit. Even if styled as a debit, all fiat payments are credits and all have credit risk baked into their cost, even if that is obscured and pushed to the absolute foundational level of money printing to keep banks solvent and hence keep payment channels open.
Furthermore! this enables us to strip away the untenable market dynamic from the point above. The underappreciated and underdiscussed flip side of the drawback of the current dynamic that is effectively fixed by Taproot Assets is that there is no longer a mammoth network effect to a single issuer. Senders and receivers can trust different issuers (i.e. their own banks) because those banks can atomically settle a single payment over Lightning. This does not involve credit. It is arguably the only true debit in the world across both the relevant economic and technical criteria: it routes through money with no innate credit risk, and it does so atomically due to that money’s native properties.
Savvy readers may have picked up on a seed I planted a while back and which can now delightfully blossom:
This is what Visa was supposed to be!
Crucially, this is not what Visa is now. Visa today is pretty much the bank that is everybody’s counterparty, takes a small credit risk for the privilege, and oozes free cash flow bottlenecking global consumer payments.
But if you read both One From Many by Dee Hock (for a first person but pretty wild and extravagant take) and Electronic Value Exchange by David Stearns (for a third person, drier, but more analytical and historically contextualized take) or if you are just intimately familiar with the modern history of payments for whatever other reason, you will see that the role I just described for Lightning in an environment of unboundedly many banks issuing fiduciary media in the form of stablecoins is exactly what Dee Hock wanted to create when he envisioned Visa:
A neutral and open layer of value settlement enabling banks to create digital, interbank payment schemes for their customers at very low cost.
As it turns out, his vision was technically impossible with fiat, hence Visa, which started as a cooperative amongst member banks, was corrupted into a duopolistic for-profit rent seeker in curious parallel to the historical path of central banks …
4) eCash
To now push the argument to what I think is its inevitable conclusion, it’s worth being even more vigilant on the front of you don’t need a blockchain for that. I have argued that there is a role for a blockchain in providing a neutral settlement layer to enable true debits of stablecoins. But note this is just a fancy and/or stupid way of saying that Bitcoin is both the best money and is programmable, which we all knew anyway. The final step is realizing that, while TA is nice in terms of providing a kind of “on ramp” for global payments infrastructure as a whole to reorient around Lightning, there is some path dependence here in assuming (almost certainly correctly) that the familiarity of stablecoins as “RWA tokens on a blockchain” will be an important part of the lure.
But once that transition is complete, or is well on its way to being irreversible, we may as well come full circle and cut out tokens altogether. Again, you really don’t need a blockchain for that, and the residual appeal of better rails has been taken care of with the above massive detour through what I deem to be the inevitability of Lightning as a settlement layer. Just as USDT on Tron arguably has better moneyness than a JPMorgan balance, so a “stablecoin” as eCash has better moneyness than as a TA given it is cheaper, more private, and has more relevantly bearer properties (in other words, because it is cash). The technical detail that it can be hashlocked is really all you need to tie this all together. That means it can be atomically locked into a Lightning routed debit to the recipient of a different issuer (or “mint” in eCash lingo, but note this means the same thing as what we have been calling fully reserved banks). And the economic incentive is pretty compelling too because, for all their benefits, there is still a cost to TAs given they are issued onchain and they require asset-specific liquidity to route on Lightning. Once the rest of the tech is in place, why bother? Keep your Lightning connectivity and just become a mint.
What you get at that point is dramatically superior private database to JPMorgan with the dramatically superior public rails of Lightning. There is nothing left to desire from “a blockchain” besides what Bitcoin is fundamentally for in the first place: counterparty-risk-free value settlement.
And as a final point with a curious and pleasing echo to Dee Hock at Visa, Calle has made the point repeatedly that David Chaum’s vision for eCash, while deeply philosophical besides the technical details, was actually pretty much impossible to operate on fiat. From an eCash perspective, fiat stablecoins within the above infrastructure setup are a dramatic improvement on anything previously possible. But, of course, they are a slippery slope to Bitcoin regardless …
Objections Revisited
As a cherry on top, I think the objections I highlighted at the outset are now readily addressed – to the extent the reader believes what I am suggesting is more or less a technical and economic inevitability, that is. While, sure, I’m not particularly keen on giving the Treasury more avenues to sell its welfare-warfare shitcoin, on balance the likely development I’ve outlined is an enormous net positive: it’s going to sell these anyway so I prefer a strong economic incentive to steadily transition not only to Lightning as payment rails but eCash as fiduciary media, and to use “fintech” as a carrot to induce a slow motion bank run.
As alluded to above, once all this is in place, the final step to a Bitcoin standard becomes as simple as an individual’s decision to want Bitcoin instead of fiat. On reflection, this is arguably the easiest part! It's setting up all the tech that puts people off, so trojan-horsing them with “faster, cheaper payment rails” seems like a genius long-term strategy.
And as to “needing a blockchain” (or not), I hope that is entirely wrapped up at this point. The only blockchain you need is Bitcoin, but to the extent people are still confused by this (which I think will take decades more to fully unwind), we may as well lean into dazzling them with whatever innovation buzzwords and decentralization theatre they were going to fall for anyway before realizing they wanted Bitcoin all along.
Conclusion
Stablecoins are useful whether you like it or not. They are stupid in the abstract but it turns out fiat is even stupider, on inspection. But you don’t need a blockchain, and using one as decentralization theatre creates technical debt that is insurmountable in the long run. Blockchain-based stablecoins are doomed to a utility inversely proportional to their usage, and just to rub it in, their ill-conceived design practically creates a commercial dynamic that mandates there only ever be a single issuer.
Given they are useful, it seems natural that this tension is going to blow up at some point. It also seems worthwhile observing that Taproot Asset stablecoins have almost the inverse problem and opposite commercial dynamic: they will be most expensive to use at the outset but get cheaper and cheaper as their usage grows. Also, there is no incentive towards a monopoly issuer but rather towards as many as are willing to try to operate well and provide value to their users.
As such, we can expect any sizable growth in stablecoins to migrate to TA out of technical and economic necessity. Once this has happened - or possibly while it is happening but is clearly not going to stop - we may as well strip out the TA component and just use eCash because you really don’t need a blockchain for that at all. And once all the money is on eCash, deciding you want to denominate it in Bitcoin is the simplest on-ramp to hyperbitcoinization you can possibly imagine, given we’ve spent the previous decade or two rebuilding all payments tech around Lightning.
Or: Bitcoin fixes this. The End.
- Allen, #892,125
thanks to Marco Argentieri, Lyn Alden, and Calle for comments and feedback
-
@ 8947a945:9bfcf626
2024-10-17 08:06:55

สวัสดีทุกคนบน Nostr ครับ รวมไปถึง watchersและ ผู้ติดตามของผมจาก Deviantart และ platform งานศิลปะอื่นๆนะครับ
ตั้งแต่ต้นปี 2024 ผมใช้ AI เจนรูปงานตัวละครสาวๆจากอนิเมะ และเปิด exclusive content ให้สำหรับผู้ที่ชื่นชอบผลงานของผมเป็นพิเศษ
ผมโพสผลงานผมทั้งหมดไว้ที่เวบ Deviantart และค่อยๆสร้างฐานผู้ติดตามมาเรื่อยๆอย่างค่อยเป็นค่อยไปมาตลอดครับ ทุกอย่างเติบโตไปเรื่อยๆของมัน ส่วนตัวผมมองว่ามันเป็นพิร์ตธุรกิจออนไลน์ ของผมพอร์ตนึงได้เลย
เมื่อวันที่ 16 กย.2024 มีผู้ติดตามคนหนึ่งส่งข้อความส่วนตัวมาหาผม บอกว่าชื่นชอบผลงานของผมมาก ต้องการจะขอซื้อผลงาน แต่ขอซื้อเป็น NFT นะ เสนอราคาซื้อขายต่อชิ้นที่สูงมาก หลังจากนั้นผมกับผู้ซื้อคนนี้พูดคุยกันในเมล์ครับ

นี่คือข้อสรุปสั่นๆจากการต่อรองซื้อขายครับ
(หลังจากนี้ผมขอเรียกผู้ซื้อว่า scammer นะครับ เพราะไพ่มันหงายมาแล้ว ว่าเขาคือมิจฉาชีพ)

- Scammer รายแรก เลือกผลงานที่จะซื้อ เสนอราคาซื้อที่สูงมาก แต่ต้องเป็นเวบไซต์ NFTmarket place ที่เขากำหนดเท่านั้น มันทำงานอยู่บน ERC20 ผมเข้าไปดูเวบไซต์ที่ว่านี้แล้วรู้สึกว่ามันดูแปลกๆครับ คนที่จะลงขายผลงานจะต้องใช้ email ในการสมัครบัญชีซะก่อน ถึงจะผูก wallet อย่างเช่น metamask ได้ เมื่อผูก wallet แล้วไม่สามารถเปลี่ยนได้ด้วย ตอนนั้นผมใช้ wallet ที่ไม่ได้ link กับ HW wallet ไว้ ทดลองสลับ wallet ไปๆมาๆ มันทำไม่ได้ แถมลอง log out แล้ว เลข wallet ก็ยังคาอยู่อันเดิม อันนี้มันดูแปลกๆแล้วหนึ่งอย่าง เวบนี้ค่า ETH ในการ mint 0.15 - 0.2 ETH … ตีเป็นเงินบาทนี่แพงบรรลัยอยู่นะครับ

-
Scammer รายแรกพยายามชักจูงผม หว่านล้อมผมว่า แหม เดี๋ยวเขาก็มารับซื้องานผมน่า mint งานเสร็จ รีบบอกเขานะ เดี๋ยวเขารีบกดซื้อเลย พอขายได้กำไร ผมก็ได้ค่า gas คืนได้ แถมยังได้กำไรอีก ไม่มีอะไรต้องเสีนจริงมั้ย แต่มันเป้นความโชคดีครับ เพราะตอนนั้นผมไม่เหลือทุนสำรองที่จะมาซื้อ ETH ได้ ผมเลยต่อรองกับเขาตามนี้ครับ :
-
ผมเสนอว่า เอางี้มั้ย ผมส่งผลงานของผมแบบ low resolution ให้ก่อน แลกกับให้เขาช่วยโอน ETH ที่เป็นค่า mint งานมาให้หน่อย พอผมได้ ETH แล้ว ผมจะ upscale งานของผม แล้วเมล์ไปให้ ใจแลกใจกันไปเลย ... เขาไม่เอา
- ผมเสนอให้ไปซื้อที่ร้านค้าออนไลน์ buymeacoffee ของผมมั้ย จ่ายเป็น USD ... เขาไม่เอา
- ผมเสนอให้ซื้อขายผ่าน PPV lightning invoice ที่ผมมีสิทธิ์เข้าถึง เพราะเป็น creator ของ Creatr ... เขาไม่เอา
- ผมยอกเขาว่างั้นก็รอนะ รอเงินเดือนออก เขาบอก ok
สัปดาห์ถัดมา มี scammer คนที่สองติดต่อผมเข้ามา ใช้วิธีการใกล้เคียงกัน แต่ใช้คนละเวบ แถมเสนอราคาซื้อที่สูงกว่าคนแรกมาก เวบที่สองนี้เลวร้ายค่าเวบแรกอีกครับ คือต้องใช้เมล์สมัครบัญชี ไม่สามารถผูก metamask ได้ พอสมัครเสร็จจะได้ wallet เปล่าๆมาหนึ่งอัน ผมต้องโอน ETH เข้าไปใน wallet นั้นก่อน เพื่อเอาไปเป็นค่า mint NFT 0.2 ETH
ผมบอก scammer รายที่สองว่า ต้องรอนะ เพราะตอนนี้กำลังติดต่อซื้อขายอยู่กับผู้ซื้อรายแรกอยู่ ผมกำลังรอเงินเพื่อมาซื้อ ETH เป็นต้นทุนดำเนินงานอยู่ คนคนนี้ขอให้ผมส่งเวบแรกไปให้เขาดูหน่อย หลังจากนั้นไม่นานเขาเตือนผมมาว่าเวบแรกมันคือ scam นะ ไม่สามารถถอนเงินออกมาได้ เขายังส่งรูป cap หน้าจอที่คุยกับผู้เสียหายจากเวบแรกมาให้ดูว่าเจอปัญหาถอนเงินไม่ได้ ไม่พอ เขายังบลัฟ opensea ด้วยว่าลูกค้าขายงานได้ แต่ถอนเงินไม่ได้
Opensea ถอนเงินไม่ได้ ตรงนี้แหละครับคือตัวกระตุกต่อมเอ๊ะของผมดังมาก เพราะ opensea อ่ะ ผู้ใช้ connect wallet เข้ากับ marketplace โดยตรง ซื้อขายกันเกิดขึ้น เงินวิ่งเข้าวิ่งออก wallet ของแต่ละคนโดยตรงเลย opensea เก็บแค่ค่า fee ในการใช้ platform ไม่เก็บเงินลูกค้าไว้ แถมปีนี้ค่า gas fee ก็ถูกกว่า bull run cycle 2020 มาก ตอนนี้ค่า gas fee ประมาณ 0.0001 ETH (แต่มันก็แพงกว่า BTC อยู่ดีอ่ะครับ)
ผมเลยเอาเรื่องนี้ไปปรึกษาพี่บิท แต่แอดมินมาคุยกับผมแทน ทางแอดมินแจ้งว่ายังไม่เคยมีเพื่อนๆมาปรึกษาเรื่องนี้ กรณีที่ผมทักมาถามนี่เป็นรายแรกเลย แต่แอดมินให้ความเห็นไปในทางเดียวกับสมมุติฐานของผมว่าน่าจะ scam ในเวลาเดียวกับผมเอาเรื่องนี้ไปถามในเพจ NFT community คนไทนด้วย ได้รับการ confirm ชัดเจนว่า scam และมีคนไม่น้อยโดนหลอก หลังจากที่ผมรู้ที่มาแล้ว ผมเลยเล่นสงครามปั่นประสาท scammer ทั้งสองคนนี้ครับ เพื่อดูว่าหลอกหลวงมิจฉาชีพจริงมั้ย
โดยวันที่ 30 กย. ผมเลยปั่นประสาน scammer ทั้งสองรายนี้ โดยการ mint ผลงานที่เขาเสนอซื้อนั่นแหละ ขึ้น opensea แล้วส่งข้อความไปบอกว่า
mint ให้แล้วนะ แต่เงินไม่พอจริงๆว่ะโทษที เลย mint ขึ้น opensea แทน พอดีบ้านจน ทำได้แค่นี้ไปถึงแค่ opensea รีบไปซื้อล่ะ มีคนจ้องจะคว้างานผมเยอะอยู่ ผมไม่คิด royalty fee ด้วยนะเฮ้ย เอาไปขายต่อไม่ต้องแบ่งกำไรกับผม
เท่านั้นแหละครับ สงครามจิตวิทยาก็เริ่มขึ้น แต่เขาจนมุม กลืนน้ำลายตัวเอง ช็อตเด็ดคือ
เขา : เนี่ยอุส่ารอ บอกเพื่อนในทีมว่าวันจันทร์ที่ 30 กย. ได้ของแน่ๆ เพื่อนๆในทีมเห็นงานผมแล้วมันสวยจริง เลยใส่เงินเต็มที่ 9.3ETH (+ capture screen ส่งตัวเลขยอดเงินมาให้ดู)ไว้รอโดยเฉพาะเลยนะ ผม : เหรอ ... งั้น ขอดู wallet address ที่มี transaction มาให้ดูหน่อยสิ เขา : 2ETH นี่มัน 5000$ เลยนะ ผม : แล้วไง ขอดู wallet address ที่มีการเอายอดเงิน 9.3ETH มาให้ดูหน่อย ไหนบอกว่าเตรียมเงินไว้มากแล้วนี่ ขอดูหน่อย ว่าใส่ไว้เมื่อไหร่ ... เอามาแค่ adrress นะเว้ย ไม่ต้องทะลึ่งส่ง seed มาให้ เขา : ส่งรูปเดิม 9.3 ETH มาให้ดู ผม : รูป screenshot อ่ะ มันไม่มีความหมายหรอกเว้ย ตัดต่อเอาก็ได้ง่ายจะตาย เอา transaction hash มาดู ไหนว่าเตรียมเงินไว้รอ 9.3ETH แล้วอยากซื้องานผมจนตัวสั่นเลยไม่ใช่เหรอ ถ้าจะส่ง wallet address มาให้ดู หรือจะช่วยส่ง 0.15ETH มาให้ยืม mint งานก่อน แล้วมากดซื้อ 2ETH ไป แล้วผมใช้ 0.15ETH คืนให้ก็ได้ จะซื้อหรือไม่ซื้อเนี่ย เขา : จะเอา address เขาไปทำไม ผม : ตัดจบ รำคาญ ไม่ขายให้ละ เขา : 2ETH = 5000 USD เลยนะ ผม : แล้วไง
ผมเลยเขียนบทความนี้มาเตือนเพื่อนๆพี่ๆทุกคนครับ เผื่อใครกำลังเปิดพอร์ตทำธุรกิจขาย digital art online แล้วจะโชคดี เจอของดีแบบผม
ทำไมผมถึงมั่นใจว่ามันคือการหลอกหลวง แล้วคนโกงจะได้อะไร

อันดับแรกไปพิจารณาดู opensea ครับ เป็นเวบ NFTmarketplace ที่ volume การซื้อขายสูงที่สุด เขาไม่เก็บเงินของคนจะซื้อจะขายกันไว้กับตัวเอง เงินวิ่งเข้าวิ่งออก wallet ผู้ซื้อผู้ขายเลย ส่วนทางเวบเก็บค่าธรรมเนียมเท่านั้น แถมค่าธรรมเนียมก็ถูกกว่าเมื่อปี 2020 เยอะ ดังนั้นการที่จะไปลงขายงานบนเวบ NFT อื่นที่ค่า fee สูงกว่ากันเป็นร้อยเท่า ... จะทำไปทำไม
ผมเชื่อว่า scammer โกงเงินเจ้าของผลงานโดยการเล่นกับความโลภและความอ่อนประสบการณ์ของเจ้าของผลงานครับ เมื่อไหร่ก็ตามที่เจ้าของผลงานโอน ETH เข้าไปใน wallet เวบนั้นเมื่อไหร่ หรือเมื่อไหร่ก็ตามที่จ่ายค่า fee ในการ mint งาน เงินเหล่านั้นสิ่งเข้ากระเป๋า scammer ทันที แล้วก็จะมีการเล่นตุกติกต่อแน่นอนครับ เช่นถอนไม่ได้ หรือซื้อไม่ได้ ต้องโอนเงินมาเพิ่มเพื่อปลดล็อค smart contract อะไรก็ว่าไป แล้วคนนิสัยไม่ดีพวกเนี้ย ก็จะเล่นกับความโลภของคน เอาราคาเสนอซื้อที่สูงโคตรๆมาล่อ ... อันนี้ไม่ว่ากัน เพราะบนโลก NFT รูปภาพบางรูปที่ไม่ได้มีความเป็นศิลปะอะไรเลย มันดันขายกันได้ 100 - 150 ETH ศิลปินที่พยายามสร้างตัวก็อาจจะมองว่า ผลงานเรามีคนรับซื้อ 2 - 4 ETH ต่องานมันก็มากพอแล้ว (จริงๆมากเกินจนน่าตกใจด้วยซ้ำครับ)
บนโลกของ BTC ไม่ต้องเชื่อใจกัน โอนเงินไปหากันได้ ปิดสมุดบัญชีได้โดยไม่ต้องเชื่อใจกัน
บบโลกของ ETH "code is law" smart contract มีเขียนอยู่แล้ว ไปอ่าน มันไม่ได้ยากมากในการทำความเข้าใจ ดังนั้น การจะมาเชื่อคำสัญญาจากคนด้วยกัน เป็นอะไรที่ไม่มีเหตุผล
ผมไปเล่าเรื่องเหล่านี้ให้กับ community งานศิลปะ ก็มีทั้งเสียงตอบรับที่ดี และไม่ดีปนกันไป มีบางคนยืนยันเสียงแข็งไปในทำนองว่า ไอ้เรื่องแบบเนี้ยไม่ได้กินเขาหรอก เพราะเขาตั้งใจแน่วแน่ว่างานศิลป์ของเขา เขาไม่เอาเข้ามายุ่งในโลก digital currency เด็ดขาด ซึ่งผมก็เคารพมุมมองเขาครับ แต่มันจะดีกว่ามั้ย ถ้าเราเปิดหูเปิดตาให้ทันเทคโนโลยี โดยเฉพาะเรื่อง digital currency , blockchain โดนโกงทีนึงนี่คือหมดตัวกันง่ายกว่าเงิน fiat อีก
อยากจะมาเล่าให้ฟังครับ และอยากให้ช่วยแชร์ไปให้คนรู้จักด้วย จะได้ระวังตัวกัน
Note
- ภาพประกอบ cyber security ทั้งสองนี่ของผมเองครับ ทำเอง วางขายบน AdobeStock
- อีกบัญชีนึงของผม "HikariHarmony" npub1exdtszhpw3ep643p9z8pahkw8zw00xa9pesf0u4txyyfqvthwapqwh48sw กำลังค่อยๆเอาผลงานจากโลกข้างนอกเข้ามา nostr ครับ ตั้งใจจะมาสร้างงานศิลปะในนี้ เพื่อนๆที่ชอบงาน จะได้ไม่ต้องออกไปหาที่ไหน
ผลงานของผมครับ - Anime girl fanarts : HikariHarmony - HikariHarmony on Nostr - General art : KeshikiRakuen - KeshikiRakuen อาจจะเป็นบัญชี nostr ที่สามของผม ถ้าไหวครับ
-
@ 502ab02a:a2860397
2025-05-05 03:39:58
โครงการ “Meat Free Monday” หรือ “จันทร์ไร้เนื้อ” เริ่มต้นในปี 2009 โดยพอล แมคคาร์ทนีย์และลูกสาวสองคนของเขา มีเป้าหมายในการลดการบริโภคเนื้อสัตว์เพื่อสุขภาพของมนุษย์และสุขภาพของโลกอย่างน้อยสัปดาห์ละหนึ่งวัน โดยอ้างถึงเหตุผลด้านสุขภาพและสโครงการ “Meat Free Monday” หรือ “จันทร์ไร้เนื้อ” เริ่มต้นในปี 2009 โดยพอล แมคคาร์ทนีย์และลูกสาวสองคนของเขา มีเป้าหมายในการลดการบริโภคเนื้อสัตว์เพื่อสุขภาพของมนุษย์และสุขภาพของโลกอย่างน้อยสัปดาห์ละหนึ่งวัน โดยอ้างถึงเหตุผลด้านสุขภาพและสิ่งแวดล้อม
https://youtu.be/ulVFWJqXNg0?si=eMs-CxtPE1kjljLD เซอร์พอล แมคคาร์ทนีย์ได้ผลิตภาพยนตร์สั้นเรื่อง "One Day a Week" เพื่อส่งเสริมโครงการ MFM โดยเน้นถึงผลกระทบของการบริโภคเนื้อสัตว์ต่อสิ่งแวดล้อมและสุขภาพของมนุษย์ ภาพยนตร์นี้มีการปรากฏตัวของบุคคลที่มีชื่อเสียง เช่น วูดี้ ฮาร์เรลสัน และเอ็มมา สโตน
MFM ได้รับการสนับสนุนจากโรงเรียนมากกว่า 3,000 แห่งในสหราชอาณาจักร รวมถึงหน่วยงานการศึกษาท้องถิ่น เช่น เอดินบะระและทราฟฟอร์ด โดยมีการจัดทำชุดข้อมูลสำหรับโรงเรียนเพื่อส่งเสริมให้นักเรียนมีสุขภาพดีขึ้นและเป็นพลเมืองที่มีความรับผิดชอบต่อโลก แนวคิดนี้ได้รับการสนับสนุนจากองค์กรต่าง ๆ เช่น ProVeg International ซึ่งมีบทบาทในการส่งเสริมอาหารจากพืชในโรงเรียนผ่านโครงการ “School Plates” โดยให้คำปรึกษาเกี่ยวกับเมนูอาหาร คำแนะนำด้านโภชนาการ และการฝึกอบรมการทำอาหารจากพืช รวมถึงมีการสนับสนุนจากหน่วยงานท้องถิ่นและองค์กรต่างๆ ทั่วโลก เช่น เมืองเกนต์ในเบลเยียมที่มีการจัดวันพฤหัสบดีปลอดเนื้อสัตว์อย่างเป็นทางการ และเมืองเซาเปาโลในบราซิลที่มีการสนับสนุนจากสมาคมมังสวิรัติของบราซิล
อย่างไรก็ตาม มีข้อกังวลเกี่ยวกับการแทรกแซงขององค์กรเหล่านี้ในระบบการศึกษา โดยเฉพาะในโรงเรียนระดับ K-12 ที่มีการนำเสนออาหารจากพืชในวันจันทร์ โดยอ้างถึงประโยชน์ด้านสุขภาพและสิ่งแวดล้อม การดำเนินการดังกล่าวอาจส่งผลต่อการรับรู้ของเด็ก ๆ เกี่ยวกับเนื้อสัตว์ และอาจนำไปสู่การเปลี่ยนแปลงพฤติกรรมการบริโภคในระยะยาว
นอกจากนี้ ยังมีการวิพากษ์วิจารณ์เกี่ยวกับการใช้คำว่า “Meat Free” ซึ่งอาจสื่อถึงการขาดบางสิ่งบางอย่าง ProVeg UK แนะนำให้หลีกเลี่ยงการใช้คำนี้และใช้คำอื่นที่เน้นถึงความเป็นมิตรกับสิ่งแวดล้อมแทน
ในขณะที่การส่งเสริมการบริโภคอาหารจากพืชมีข้อดีในด้านสุขภาพและสิ่งแวดล้อม แต่การดำเนินการที่มีลักษณะเป็นการบังคับหรือแทรกแซงในระบบการศึกษาโดยไม่มีการให้ข้อมูลที่ครบถ้วนและเป็นกลาง อาจนำไปสู่การล้างสมองและการเปลี่ยนแปลงพฤติกรรมการบริโภคโดยไม่รู้ตัว ดังนั้น การส่งเสริมการบริโภคอาหารจากพืชควรเป็นไปอย่างโปร่งใส ให้ข้อมูลที่ครบถ้วน และเคารพสิทธิ์ในการเลือกของแต่ละบุคคล โดยเฉพาะในกลุ่มเด็กและเยาวชน
ProVeg UK ได้เสนอให้เปลี่ยนชื่อจาก “Meat-Free Monday” เป็น “Planet-Friendly Days” โดยให้เหตุผลว่าคำว่า “Meat-Free” อาจสื่อถึงการขาดบางสิ่งบางอย่าง และอาจทำให้ผู้บริโภคมองว่าเมนูดังกล่าวไม่น่าสนใจ การใช้คำว่า “Planet-Friendly” ช่วยเน้นถึงความเป็นมิตรกับสิ่งแวดล้อมและส่งเสริมการบริโภคอาหารจากพืชในแง่บวกมากขึ้น
นอกจากนี้ทาง ProVeg UK ดำเนินโครงการ “School Plates” เพื่อช่วยโรงเรียนในการปรับปรุงเมนูอาหารให้มีความยั่งยืนมากขึ้น โดยให้คำปรึกษาเกี่ยวกับเมนูอาหาร คำแนะนำด้านโภชนาการ และการฝึกอบรมการทำอาหารจากพืช นอกจากนี้ยังมีการจัดกิจกรรมเสริม เช่น การแข่งขันออกแบบโปสเตอร์และชั้นเรียนทำอาหารจากพืช เพื่อส่งเสริมการเรียนรู้เกี่ยวกับระบบอาหารและกระตุ้นให้เด็ก ๆ ลองชิมเมนูใหม่ ๆ
ในส่วนของ ProVeg International ก็ยังสนับสนุนโครงการระดับชาติ เช่น “National School Meals Week” ในปี 2020 โดยให้คำแนะนำแก่โรงเรียนในการจัดเมนูอาหารที่ลดการบริโภคเนื้อสัตว์ และเสนอให้ใช้คำที่เน้นถึงรสชาติหรือส่วนผสมหลักของเมนู เลี่ยงการใช้คำว่า “meat-free” หรือ “vegan” ซึ่งอาจมีผลกระทบต่อการเลือกเมนูของผู้บริโภค แล้วยังมีการส่งเสริมการบริโภคอาหารจากพืชผ่านกิจกรรมต่าง ๆ เช่น “Veggie Challenge” ซึ่งเป็นโปรแกรมออนไลน์ฟรีที่สอนการทำอาหารจากพืช พร้อมให้คำแนะนำและสูตรอาหารรายวัน เพื่อช่วยให้ผู้เข้าร่วมสามารถเปลี่ยนแปลงพฤติกรรมการบริโภคได้อย่างยั่งยืน
จากข้อมูลข้างต้น แสดงให้เห็นว่า ProVeg International มีบทบาทในการส่งเสริมการบริโภคอาหารจากพืชผ่านหลายช่องทาง โดยเฉพาะในระบบการศึกษาและโครงการอาหารโรงเรียน เพื่อสนับสนุนการเปลี่ยนแปลงพฤติกรรมการบริโภคในระยะยาว
คำถามคือ ทำไมต้องเริ่มจากโรงเรียน? ก็เพราะเด็กยังไม่รู้จัก “ฟังร่างกายตัวเอง” ยังเชื่อในสิ่งที่ครู พ่อแม่ หรือคนในทีวีบอก ถ้าเด็กถูกสอนว่า “เนื้อวัวทำลายโลก” และ “ไก่ หมู คือปีศาจ” เด็กคนนั้นจะโตมาโดยมอง “ของจริง” เป็นของแปลก และมอง “ของปลอม” เป็นพระเอก
วันนี้ห้ามกินเนื้อ พรุ่งนี้อาจห้ามพูดถึงเนื้อ และวันหนึ่ง...เขาอาจห้ามเราผลิตเนื้อจริงเลยก็ได้
อย่าเข้าใจผิดว่าเฮียต่อต้านผักนะ เฮียชอบผักที่ขึ้นเองตามธรรมชาติ แต่เฮียไม่ชอบ "ผักที่มากับนโยบาย" ไม่ชอบ "จานอาหารที่ถูกกำหนดด้วยวาระซ่อนเร้น"
Meat Free Monday อาจเป็นแค่หนึ่งวันในสัปดาห์ แต่ถ้าเราไม่ตั้งคำถาม มันอาจกลายเป็นชีวิตทั้งชีวิตที่ถูกออกแบบไว้ล่วงหน้า
ที่น่าสนใจอีกอย่างนึงคือ MFM เป็นองค์กรไม่แสวงหาผลกำไรที่ดำเนินการภายใต้การสนับสนุนของ Charities Aid Foundation (หมายเลขทะเบียนการกุศล 268369) อย่างไรก็ตาม "ไม่มีข้อมูลสาธารณะเกี่ยวกับจำนวนเงินทุนหรือแหล่งเงินทุนที่เฉพาะเจาะจงที่สนับสนุนโครงการนี้"
#pirateketo #กูต้องรู้มั๊ย #ม้วนหางสิลูก #siamstr
-
@ 8947a945:9bfcf626
2024-10-17 07:33:00
Hello everyone on Nostr and all my watchersand followersfrom DeviantArt, as well as those from other art platforms
I have been creating and sharing AI-generated anime girl fanart since the beginning of 2024 and have been running member-exclusive content on Patreon.
I also publish showcases of my artworks to Deviantart. I organically build up my audience from time to time. I consider it as one of my online businesses of art. Everything is slowly growing
On September 16, I received a DM from someone expressing interest in purchasing my art in NFT format and offering a very high price for each piece. We later continued the conversation via email.
Here’s a brief overview of what happened
- The first scammer selected the art they wanted to buy and offered a high price for each piece. They provided a URL to an NFT marketplace site running on the Ethereum (ETH) mainnet or ERC20. The site appeared suspicious, requiring email sign-up and linking a MetaMask wallet. However, I couldn't change the wallet address later. The minting gas fees were quite expensive, ranging from 0.15 to 0.2 ETH
-
The scammers tried to convince me that the high profits would easily cover the minting gas fees, so I had nothing to lose. Luckily, I didn’t have spare funds to purchase ETH for the gas fees at the time, so I tried negotiating with them as follows:
-
I offered to send them a lower-quality version of my art via email in exchange for the minting gas fees, but they refused.
- I offered them the option to pay in USD through Buy Me a Coffee shop here, but they refused.
- I offered them the option to pay via Bitcoin using the Lightning Network invoice , but they refused.
- I asked them to wait until I could secure the funds, and they agreed to wait.
The following week, a second scammer approached me with a similar offer, this time at an even higher price and through a different NFT marketplace website.
This second site also required email registration, and after navigating to the dashboard, it asked for a minting fee of 0.2 ETH. However, the site provided a wallet address for me instead of connecting a MetaMask wallet.
I told the second scammer that I was waiting to make a profit from the first sale, and they asked me to show them the first marketplace. They then warned me that the first site was a scam and even sent screenshots of victims, including one from OpenSea saying that Opensea is not paying.
This raised a red flag, and I began suspecting I might be getting scammed. On OpenSea, funds go directly to users' wallets after transactions, and OpenSea charges a much lower platform fee compared to the previous crypto bull run in 2020. Minting fees on OpenSea are also significantly cheaper, around 0.0001 ETH per transaction.
I also consulted with Thai NFT artist communities and the ex-chairman of the Thai Digital Asset Association. According to them, no one had reported similar issues, but they agreed it seemed like a scam.
After confirming my suspicions with my own research and consulting with the Thai crypto community, I decided to test the scammers’ intentions by doing the following
I minted the artwork they were interested in, set the price they offered, and listed it for sale on OpenSea. I then messaged them, letting them know the art was available and ready to purchase, with no royalty fees if they wanted to resell it.
They became upset and angry, insisting I mint the art on their chosen platform, claiming they had already funded their wallet to support me. When I asked for proof of their wallet address and transactions, they couldn't provide any evidence that they had enough funds.
Here’s what I want to warn all artists in the DeviantArt community or other platforms If you find yourself in a similar situation, be aware that scammers may be targeting you.
My Perspective why I Believe This is a Scam and What the Scammers Gain
From my experience with BTC and crypto since 2017, here's why I believe this situation is a scam, and what the scammers aim to achieve
First, looking at OpenSea, the largest NFT marketplace on the ERC20 network, they do not hold users' funds. Instead, funds from transactions go directly to users’ wallets. OpenSea’s platform fees are also much lower now compared to the crypto bull run in 2020. This alone raises suspicion about the legitimacy of other marketplaces requiring significantly higher fees.
I believe the scammers' tactic is to lure artists into paying these exorbitant minting fees, which go directly into the scammers' wallets. They convince the artists by promising to purchase the art at a higher price, making it seem like there's no risk involved. In reality, the artist has already lost by paying the minting fee, and no purchase is ever made.
In the world of Bitcoin (BTC), the principle is "Trust no one" and “Trustless finality of transactions” In other words, transactions are secure and final without needing trust in a third party.
In the world of Ethereum (ETH), the philosophy is "Code is law" where everything is governed by smart contracts deployed on the blockchain. These contracts are transparent, and even basic code can be read and understood. Promises made by people don’t override what the code says.
I also discuss this issue with art communities. Some people have strongly expressed to me that they want nothing to do with crypto as part of their art process. I completely respect that stance.
However, I believe it's wise to keep your eyes open, have some skin in the game, and not fall into scammers’ traps. Understanding the basics of crypto and NFTs can help protect you from these kinds of schemes.
If you found this article helpful, please share it with your fellow artists.
Until next time Take care
Note
- Both cyber security images are mine , I created and approved by AdobeStock to put on sale
- I'm working very hard to bring all my digital arts into Nostr to build my Sats business here to my another npub "HikariHarmony" npub1exdtszhpw3ep643p9z8pahkw8zw00xa9pesf0u4txyyfqvthwapqwh48sw
Link to my full gallery - Anime girl fanarts : HikariHarmony - HikariHarmony on Nostr - General art : KeshikiRakuen
-
@ c3c7122c:607731d7
2025-04-12 04:05:06
Help!
Calling all El Salvador Nostriches! If you currently live in SV, I need your help and am offering several bounties (0.001, 0.01, and 0.1 BTC).
In Brief
In short, I am pursuing El Salvador citizenship by birthright (through my grandmother). I’ve struggled to progress because her name varies on different documents. I need someone to help me push harder to get past this barrier, or connect me with information or people who can work on my behalf. I am offering:
- 0.001 BTC (100k sats) for information that will help me progress from my current situation
- 0.01 BTC (1 MM sats) to get me in touch with someone that is more impactful than the immigration lawyer I already spoke with
- 0.1 BTC (10 MM sats) if your efforts help me obtain citizenship for me or my father
Background
My grandma married my grandfather (an American Marine) and moved to the states where my father was born. I have some official and unofficial documents where her name varies in spelling, order of first/middle name, and addition of her father’s last name. So every doc basically has a different name for her. I was connected with an english-speaking immigration lawyer in SV who hit a dead end when searching for her official ID because the city hall in her city had burned down so there was no record of her info. He gave up at that point. I find it odd that it was so easy to change your name back then, but they are more strict now with the records from that time.
I believe SV citizenship is my birthright and have several personal reasons for pursuing this. I want someone to act on my behalf who will try harder to work the system (by appeal, loophole, or even bribe if I have to). If you are local and can help me with this, I’d greatly appreciate any efforts you make.
Cheers!
Corey San Diego
-
@ e6817453:b0ac3c39
2024-10-06 11:21:27
Hey folks, today we're diving into an exciting and emerging topic: personal artificial intelligence (PAI) and its connection to sovereignty, privacy, and ethics. With the rapid advancements in AI, there's a growing interest in the development of personal AI agents that can work on behalf of the user, acting autonomously and providing tailored services. However, as with any new technology, there are several critical factors that shape the future of PAI. Today, we'll explore three key pillars: privacy and ownership, explainability, and bias.
1. Privacy and Ownership: Foundations of Personal AI
At the heart of personal AI, much like self-sovereign identity (SSI), is the concept of ownership. For personal AI to be truly effective and valuable, users must own not only their data but also the computational power that drives these systems. This autonomy is essential for creating systems that respect the user's privacy and operate independently of large corporations.
In this context, privacy is more than just a feature—it's a fundamental right. Users should feel safe discussing sensitive topics with their AI, knowing that their data won’t be repurposed or misused by big tech companies. This level of control and data ownership ensures that users remain the sole beneficiaries of their information and computational resources, making privacy one of the core pillars of PAI.
2. Bias and Fairness: The Ethical Dilemma of LLMs
Most of today’s AI systems, including personal AI, rely heavily on large language models (LLMs). These models are trained on vast datasets that represent snapshots of the internet, but this introduces a critical ethical challenge: bias. The datasets used for training LLMs can be full of biases, misinformation, and viewpoints that may not align with a user’s personal values.
This leads to one of the major issues in AI ethics for personal AI—how do we ensure fairness and minimize bias in these systems? The training data that LLMs use can introduce perspectives that are not only unrepresentative but potentially harmful or unfair. As users of personal AI, we need systems that are free from such biases and can be tailored to our individual needs and ethical frameworks.
Unfortunately, training models that are truly unbiased and fair requires vast computational resources and significant investment. While large tech companies have the financial means to develop and train these models, individual users or smaller organizations typically do not. This limitation means that users often have to rely on pre-trained models, which may not fully align with their personal ethics or preferences. While fine-tuning models with personalized datasets can help, it's not a perfect solution, and bias remains a significant challenge.
3. Explainability: The Need for Transparency
One of the most frustrating aspects of modern AI is the lack of explainability. Many LLMs operate as "black boxes," meaning that while they provide answers or make decisions, it's often unclear how they arrived at those conclusions. For personal AI to be effective and trustworthy, it must be transparent. Users need to understand how the AI processes information, what data it relies on, and the reasoning behind its conclusions.
Explainability becomes even more critical when AI is used for complex decision-making, especially in areas that impact other people. If an AI is making recommendations, judgments, or decisions, it’s crucial for users to be able to trace the reasoning process behind those actions. Without this transparency, users may end up relying on AI systems that provide flawed or biased outcomes, potentially causing harm.
This lack of transparency is a major hurdle for personal AI development. Current LLMs, as mentioned earlier, are often opaque, making it difficult for users to trust their outputs fully. The explainability of AI systems will need to be improved significantly to ensure that personal AI can be trusted for important tasks.
Addressing the Ethical Landscape of Personal AI
As personal AI systems evolve, they will increasingly shape the ethical landscape of AI. We’ve already touched on the three core pillars—privacy and ownership, bias and fairness, and explainability. But there's more to consider, especially when looking at the broader implications of personal AI development.
Most current AI models, particularly those from big tech companies like Facebook, Google, or OpenAI, are closed systems. This means they are aligned with the goals and ethical frameworks of those companies, which may not always serve the best interests of individual users. Open models, such as Meta's LLaMA, offer more flexibility and control, allowing users to customize and refine the AI to better meet their personal needs. However, the challenge remains in training these models without significant financial and technical resources.
There’s also the temptation to use uncensored models that aren’t aligned with the values of large corporations, as they provide more freedom and flexibility. But in reality, models that are entirely unfiltered may introduce harmful or unethical content. It’s often better to work with aligned models that have had some of the more problematic biases removed, even if this limits some aspects of the system’s freedom.
The future of personal AI will undoubtedly involve a deeper exploration of these ethical questions. As AI becomes more integrated into our daily lives, the need for privacy, fairness, and transparency will only grow. And while we may not yet be able to train personal AI models from scratch, we can continue to shape and refine these systems through curated datasets and ongoing development.
Conclusion
In conclusion, personal AI represents an exciting new frontier, but one that must be navigated with care. Privacy, ownership, bias, and explainability are all essential pillars that will define the future of these systems. As we continue to develop personal AI, we must remain vigilant about the ethical challenges they pose, ensuring that they serve the best interests of users while remaining transparent, fair, and aligned with individual values.
If you have any thoughts or questions on this topic, feel free to reach out—I’d love to continue the conversation!
-
@ df478568:2a951e67
2025-05-04 20:45:59
So I've worked on this cashu cards idea for a few thousand blocks. The plan is to sell them, while also keeping them open source. I had many of these ideas swarming around in my head for tens of thousands of blocks and fighting with doubt. That's the ultimate final boss. We, bitcoiners have the power to use bitcoin as a
- Store of value
- Medium of exchange
- Unit of account.
Nostr gives us the power to speak feeely. That's an often underlooked aspect of this new protocol. Bitcoin is great for sending value, but it's not tue most efficient way to communicate. There are ways to add messages to the base-chain, but that's not robust enough to build a marketplace. The marketplace consists of people speaking and exchanging value. Nostr provides us this value.
Since we are free to communicate witout censorship on nostr, we are free to use the protocol for almost anything we can imagine. It's a public space without communication restrictions and information verification system with a web of trust and active development. Think of all the bitcoin merch on Etsy. There are posters, T-shirts, coffee cups and more sold on the government/corporate controlled Internet.I'm selling merch on nostr to show them how to sell merch on nostr.
Birthday Cards And Other Stuff
![Front of the Cashu Card birthday card (https://r2.primal.net/cache/b/70/1b/b701bff0067f6c339bf3d0d05b27e72787e7869cd2c35ea59f1d0f5416102d66.jpg)
Wait, But Why✏ is a blog from Tim Urban who has a unique perapective on life. He sells Birthday Cards, Christmas cards, plush toys and coffee cups on this blog. I always thought it was cool that he monitized his articles by his inspired me to sell some of my own greeting cards, coffee cups, and other stuff. I'm building a store like that for my blog, but I want sats, obviously...So I printed some birthday cards at an actual print shop and was shocked at how great they looked. Now I'm selling some on my store. I'm selling them for 15,000 sats, but each card recieves 1,000 sats in Cashu(in the form of a QR code inside the card) I plan to donate some sats to cashu project and split up the profits with BitPopart who desigbed the cartoon characters. I would like to use zapsplits in Shopstr. I hear the NIP is easy to implment. I should vibe code it or something. Nevertheless, I'm using sats as a medium of exchange, store of value, ans unit of account. If bitcoin jumps over the moon, I'll need to adjust my prices. I have some ideas for other stuff to sell too. I prefer making as much as I can by myself. I'm not using a loom to make shirts, but I want to make t-shirts with Custom QR codes and nostr art.
Shop My Store
...So check out my store at https://shopstr.zapthisblog.com. It will help support me writing this blog, give me bitcoin IT experience, and make me feel like I'm contributing something of value to the bitcoin movement. My goal is for plebs to use these cards to educate their children, family and friends. How many times have you heard, "Bitcoin is just a speculative asset?" Bitcoin is an abstract idea built from abstract math, a tossed salad of computer science, Austrian Economics, obscure political philosophy, and math they don't teach you in high school.
Don't say, "buy bitcoin." Show people bitcoin is used like money. Give them something they can see, touch, and use. They can scan the QR code and watch the sats appear on their phone by magic with a message: Happy Birthday!
npub1marc26z8nh3xkj5rcx7ufkatvx6ueqhp5vfw9v5teq26z254renshtf3g0
-
@ 6830c409:ff17c655
2025-05-04 20:23:30
Disclaimer: No artificial intelligence tool has been used to write this article except Grammarly.
There are some things that no one* wants to talk about in a public forum. One of those things is how we clean ourselves after using the toilet. Being a South Asian, I find the bathroom etiquette a bit different from where I am now- in the US. I don't think it is something we have to keep mum about.
[*Mostly]
Earlier, I had read a "Quora WAR" where there was a fierce fight between fellow Western country people vs Indians. Indians advocated using water and the West despised that and advocated using dry wipes/toilet paper. Recently (Yesterday), I remembered this Quora debate and I was curious, when was the commercial production of toilet tissues started? And what were the hygiene methods followed before that.
Obviously, My reading started with Wikipedia. And from there, it was a rabbit-hole. I don't know how, I kept on reading for almost 2 hours. And this piece is out of my understanding of things I read during that mere 2 hours.
We take it for granted today, but toilet paper has a fascinating story spanning thousands of years. From creative ancient solutions to the modern perforated roll, humanity's quest for comfort and cleanliness reveals surprising ingenuity.
Time Before Toilet Paper
Historically, people used whatever they had in their habitat, to clean themselves. This varied from grass, leaves, tree barks, etc. And yes, many civilizations insisted and used water as the main cleaning method. But this was mainly based on the availability of clean water.
Wherever the availability of water was in question, people got creative! Ancient Romans used "tersorium"- basically it is a sea sponge on a stick. They sock it in vinegar or salt water between uses. These were communal.
Greeks preferred smooth pottery fragments with rounded edges. Of course, no one wanted the other end of the digestive tract injured! :D
Early Chinese civilizations wrapped cloth around wooden sticks shaped like spatulas.
Medieval Europeans show their class divisions even in the bathroom! The wealthy used wool, hemp, or even lace. While commoners made do with whatever cloth they had- sometimes, their own sleeves (- today, YUCK!). In the 1700s rural Americas, people turned to nature, using corncobs and seashells.
No matter what we think about these methods, every civilization and every class of people in those valued one thing - Cleanliness.
True Toilet Paper Pioneers
We all know China invented paper somewhere near 100 AD. By the 6th century, Emporer Yandgi's court records show that he used 15,000 sheets of paper annually, just for his personal hygiene!
Early Chinese toilet papers were made from rice straw, hemp, and bamboo. They boiled the material, churned it into a pulp, flattened and dry it, and then cut into shape before using it. By 14th century, the imperial court enjoyed "Perfumed paper sheets". Records show that the royal family alone used almost 0.75 million sheets yearly!!
However, not everyone was happy with this invention. Traveling Muslim merchants described the Chinese practice as "Haraam" (foul), they always preferred using water.
The West Catches Up
Western toilet paper development took longer. Sir John Harrington invented the flushing toilet in 1596, though it would not become common for centuries. By the 1700s, newspapers became a popular bathroom staple.
The commercial breakthrough came only in 1857 when American entrepreneur Joseph Gayetty found a way for the commercial production of toilet papers. But at that time it was sold in another name - "Medicated Paper for Water-Closet". He sold it 500 sheets for 50 cents. Only then the use of "Toilet papers" really arrived in the West.
Rolling into Modern Era
Later in the 19th century, manufacturers found the best and most economical way to produce and store toilet paper - as "Rolls" like we see today. Seth Wheeler of Albany patented perforated wrapping paper in 1871. and the first modern perforated toilet paper roll came out in 1891, making the "tearing" much easier - literally and figuratively! :D
That was the same time home plumbing was improving a lot which resulted in having the toilets inside the home itself. With that, the consumption of toilet paper rose - first as a vanity symbol and later as a common addition to the shopping list.
Big Business in Bathrooms
Brothers - Clarence and Edward Irvin Scott founded Scott Paper Company in Philadelphia in 1879, initially cutting and packaging toilet paper for retailers to sell under their brands. The company grew after 1896 when Arthur Hoyt Scott joined. They started mass-producing their brand of toilet paper. By 1910, they had built the largest paper mill in Chester, marking the industrialization of toilet paper production.
Meanwhile, that old paper made of concoction in China became popular there by the 16th century.
From Luxury to Necessity
We humans always run behind an unknown "comfort". The story of toilet paper is also not so different from that. Imagine using the pottery fragments in place of that "plush quilted ultra-soft scented bathroom tissues". This everyday item we rarely think about represents centuries of innovation and cultural evolution.
Next time you pull a pack of tissue papers from the back aisle of Costco, spare a "thanks" for your ancestors and their corncobs, sea sponges, and pottery fragments.
And maybe soon, you might be "Zapping" to buy tissue papers.
Final Thoughts
The COVID-19 pandemic time gave us some lessons as well as some "FailArmy" videos. One of those videos was people fighting over the last available toilet paper pack in some shop. After the pandemic, there has been a surge in American homes installing Bidet faucets in their bathrooms. A bit late, but the West is now catching up again with the East! :D
Let me know if you liked this article - leave a reaction/comment. Cheers.
-
@ e6817453:b0ac3c39
2024-09-30 14:52:23
In the modern world of AI, managing vast amounts of data while keeping it relevant and accessible is a significant challenge, mainly when dealing with large language models (LLMs) and vector databases. One approach that has gained prominence in recent years is integrating vector search with metadata, especially in retrieval-augmented generation (RAG) pipelines. Vector search and metadata enable faster and more accurate data retrieval. However, the process of pre- and post-search filtering results plays a crucial role in ensuring data relevance.
The Vector Search and Metadata Challenge
In a typical vector search, you create embeddings from chunks of text, such as a PDF document. These embeddings allow the system to search for similar items and retrieve them based on relevance. The challenge, however, arises when you need to combine vector search results with structured metadata. For example, you may have timestamped text-based content and want to retrieve the most relevant content within a specific date range. This is where metadata becomes critical in refining search results.
Unfortunately, most vector databases treat metadata as a secondary feature, isolating it from the primary vector search process. As a result, handling queries that combine vectors and metadata can become a challenge, particularly when the search needs to account for a dynamic range of filters, such as dates or other structured data.
LibSQL and vector search metadata
LibSQL is a more general-purpose SQLite-based database that adds vector capabilities to regular data. Vectors are presented as blob columns of regular tables. It makes vector embeddings and metadata a first-class citizen that naturally builds deep integration of these data points.
create table if not exists conversation ( id varchar(36) primary key not null, startDate real, endDate real, summary text, vectorSummary F32_BLOB(512) );It solves the challenge of metadata and vector search and eliminates impedance between vector data and regular structured data points in the same storage.
As you can see, you can access vector-like data and start date in the same query.
select c.id ,c.startDate, c.endDate, c.summary, vector_distance_cos(c.vectorSummary, vector(${vector})) distance from conversation where ${startDate ? `and c.startDate >= ${startDate.getTime()}` : ''} ${endDate ? `and c.endDate <= ${endDate.getTime()}` : ''} ${distance ? `and distance <= ${distance}` : ''} order by distance limit ${top};vector_distance_cos calculated as distance allows us to make a primitive vector search that does a full scan and calculates distances on rows. We could optimize it with CTE and limit search and distance calculations to a much smaller subset of data.
This approach could be calculation intensive and fail on large amounts of data.
Libsql offers a way more effective vector search based on FlashDiskANN vector indexed.
vector_top_k('idx_conversation_vectorSummary', ${vector} , ${top}) ivector_top_k is a table function that searches for the top of the newly created vector search index. As you can see, we could use only vector as a function parameter, and other columns could be used outside of the table function. So, to use a vector index together with different columns, we need to apply some strategies.
Now we get a classical problem of integration vector search results with metadata queries.
Post-Filtering: A Common Approach
The most widely adopted method in these pipelines is post-filtering. In this approach, the system first retrieves data based on vector similarities and then applies metadata filters. For example, imagine you’re conducting a vector search to retrieve conversations relevant to a specific question. Still, you also want to ensure these conversations occurred in the past week.
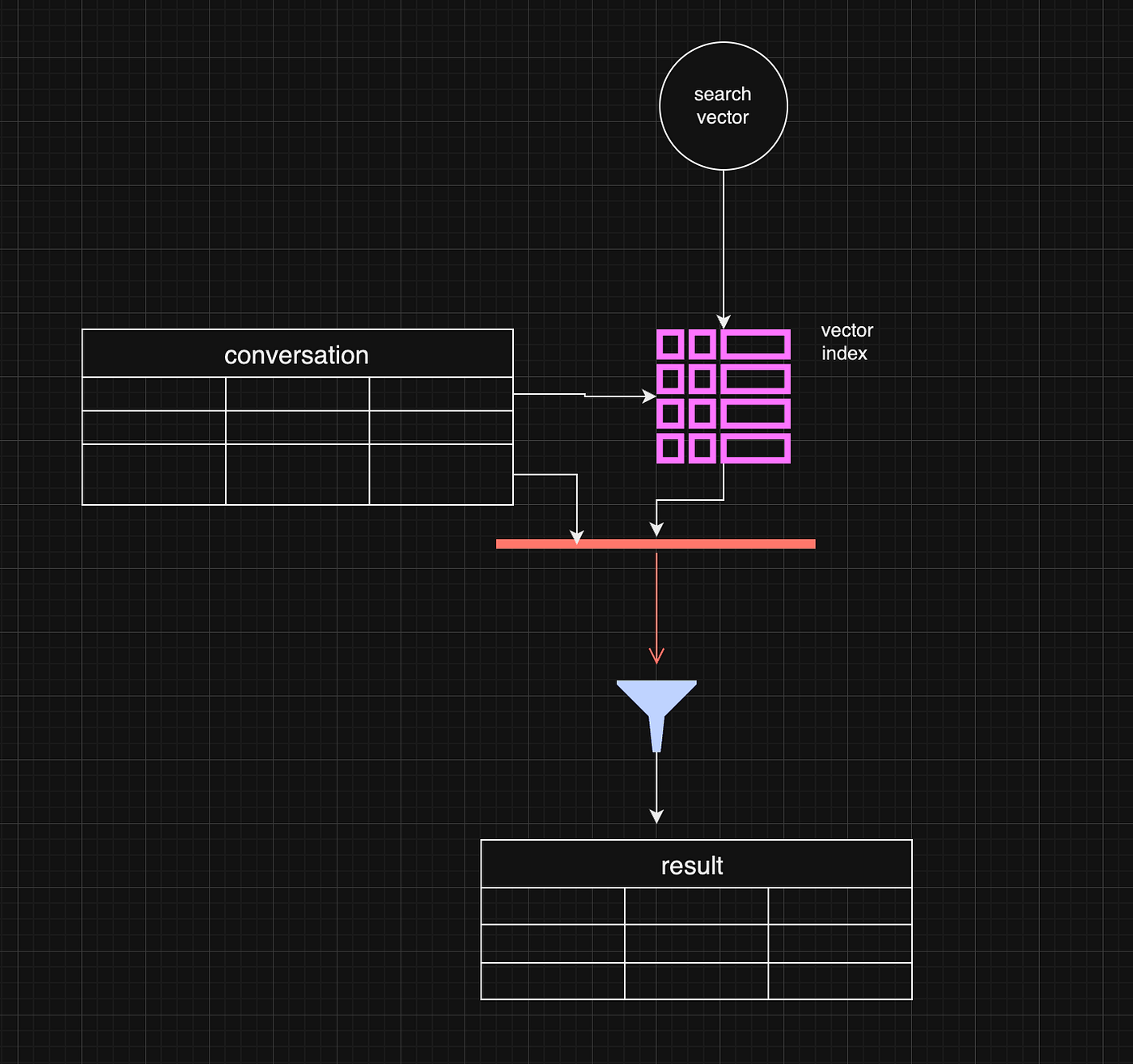
Post-filtering allows the system to retrieve the most relevant vector-based results and subsequently filter out any that don’t meet the metadata criteria, such as date range. This method is efficient when vector similarity is the primary factor driving the search, and metadata is only applied as a secondary filter.
const sqlQuery = ` select c.id ,c.startDate, c.endDate, c.summary, vector_distance_cos(c.vectorSummary, vector(${vector})) distance from vector_top_k('idx_conversation_vectorSummary', ${vector} , ${top}) i inner join conversation c on i.id = c.rowid where ${startDate ? `and c.startDate >= ${startDate.getTime()}` : ''} ${endDate ? `and c.endDate <= ${endDate.getTime()}` : ''} ${distance ? `and distance <= ${distance}` : ''} order by distance limit ${top};However, there are some limitations. For example, the initial vector search may yield fewer results or omit some relevant data before applying the metadata filter. If the search window is narrow enough, this can lead to complete results.
One working strategy is to make the top value in vector_top_K much bigger. Be careful, though, as the function's default max number of results is around 200 rows.
Pre-Filtering: A More Complex Approach
Pre-filtering is a more intricate approach but can be more effective in some instances. In pre-filtering, metadata is used as the primary filter before vector search takes place. This means that only data that meets the metadata criteria is passed into the vector search process, limiting the scope of the search right from the beginning.
While this approach can significantly reduce the amount of irrelevant data in the final results, it comes with its own challenges. For example, pre-filtering requires a deeper understanding of the data structure and may necessitate denormalizing the data or creating separate pre-filtered tables. This can be resource-intensive and, in some cases, impractical for dynamic metadata like date ranges.
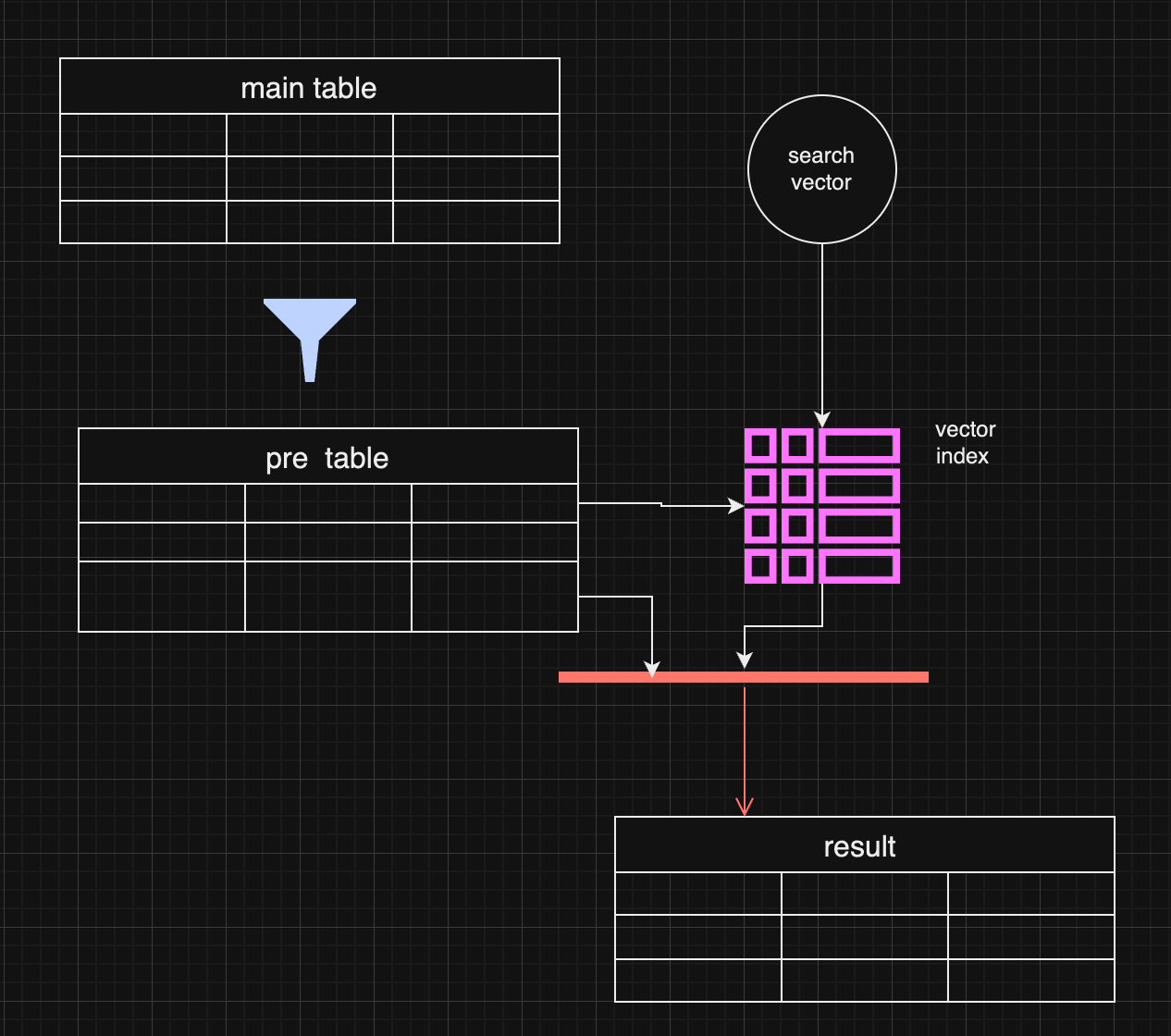
In certain use cases, pre-filtering might outperform post-filtering. For instance, when the metadata (e.g., specific date ranges) is the most important filter, pre-filtering ensures the search is conducted only on the most relevant data.
Pre-filtering with distance-based filtering
So, we are getting back to an old concept. We do prefiltering instead of using a vector index.
WITH FilteredDates AS ( SELECT c.id, c.startDate, c.endDate, c.summary, c.vectorSummary FROM YourTable c WHERE ${startDate ? `AND c.startDate >= ${startDate.getTime()}` : ''} ${endDate ? `AND c.endDate <= ${endDate.getTime()}` : ''} ), DistanceCalculation AS ( SELECT fd.id, fd.startDate, fd.endDate, fd.summary, fd.vectorSummary, vector_distance_cos(fd.vectorSummary, vector(${vector})) AS distance FROM FilteredDates fd ) SELECT dc.id, dc.startDate, dc.endDate, dc.summary, dc.distance FROM DistanceCalculation dc WHERE 1=1 ${distance ? `AND dc.distance <= ${distance}` : ''} ORDER BY dc.distance LIMIT ${top};It makes sense if the filter produces small data and distance calculation happens on the smaller data set.
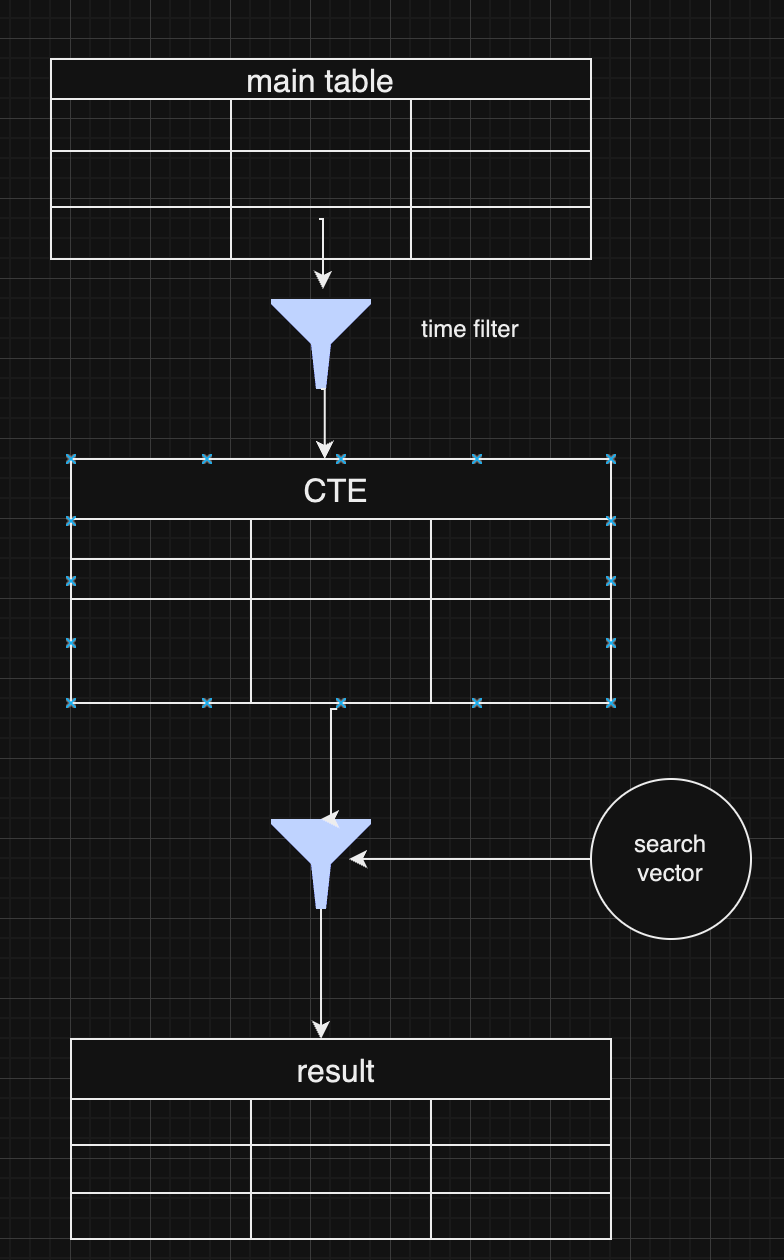
As a pro of this approach, you have full control over the data and get all results without omitting some typical values for extensive index searches.
Choosing Between Pre and Post-Filtering
Both pre-filtering and post-filtering have their advantages and disadvantages. Post-filtering is more accessible to implement, especially when vector similarity is the primary search factor, but it can lead to incomplete results. Pre-filtering, on the other hand, can yield more accurate results but requires more complex data handling and optimization.
In practice, many systems combine both strategies, depending on the query. For example, they might start with a broad pre-filtering based on metadata (like date ranges) and then apply a more targeted vector search with post-filtering to refine the results further.
Conclusion
Vector search with metadata filtering offers a powerful approach for handling large-scale data retrieval in LLMs and RAG pipelines. Whether you choose pre-filtering or post-filtering—or a combination of both—depends on your application's specific requirements. As vector databases continue to evolve, future innovations that combine these two approaches more seamlessly will help improve data relevance and retrieval efficiency further.
-
@ 3eba5ef4:751f23ae
2025-04-11 00:40:28
Crypto Insights
2025 MIT Bitcoin Expo: Spotlight on Freedom Tech
The 12th MIT Bitcoin Expo took place on April 5–6, centering this year’s theme on “Freedom Tech” and how technology can facilitate physical and social liberation.
-
Day 1 Recap: Mawarire delivered the keynote speech “Why Freedom Tech Matters,” and Dryja discussed how Bitcoin demonstrates resilience against nation-states. The morning sessions focused on corporate adoption, featuring speakers such as Paul Giordano from Marathon Digital and Bitcoin Core contributors like Gloria Zhao. The afternoon shifted toward more technical topics, including consensus cleanup, poisoning attacks, censorship resistance, and the Bitcoin Pipes protocol.
-
Day 2 Recap: The focus shifted to global impact. Mauricio Bartolomeo discussed the exfiltration of resources via Bitcoin, followed by a panel with activists from Venezuela, Russia, and Togo. Technical topics included: scaling self-custody, Steven Roose’s covenant soft fork proposals, the future of freedom tech, quantum resistance, and Tor.
Into Bitcoin Address Poisoning Attacks
In this article, Jameson Lopp highlights the rise of Bitcoin address poisoning attacks—an emerging form of social engineering. Attackers send transactions from newly generated wallets that mimic the beginning and end characters of a target's recently used address. If the target later copies an address from their transaction history, they may unknowingly send funds to the attacker instead of the intended recipient. Though the success rate per attack is low, the low cost of transactions enables attackers to attempt thousands in a short period.
Lopp also argues that such attacks are a byproduct of low transaction fees and that higher fees could deter them. He also suggests wallet-level defenses, such as warnings like, “Oh, this came from a similar looking address,” to help users avoid interaction.
Examining the Mitigation Strategy Against Timewarp Attacks
Timewarp attacks, first identified around 2011, allow a majority of malicious miners to manipulate block timestamps, artificially lower difficulty, and mine blocks every few seconds. The “Great Consensus Cleanup” soft fork proposal can mitigate this by requiring that the first block in a new difficulty period must have a time no earlier than a certain number of minutes before the last block of the previous period.
A report examines the details of this BIP.
Tokenization on Bitcoin: Building a Global Settlement Layer with Taproot Assets and Lightning
Bitcoin’s evolution into a multi-asset platform is accelerating with the advent of Taproot Assets and Lightning Network. The integration of these technologies combines Bitcoin’s decentralization and security with the speed and scalability of the Lightning Network. This report examines how Taproot Assets enable asset issuance, transfers, and swaps on Bitcoin’s base layer, and how the Lightning Network facilitates fast, low-cost transfers of those assets. We compare this approach to earlier attempts at Bitcoin asset issuance and analyze its market potential against other blockchains and traditional payment networks.
Solving Data Availability in Client-Side Validation With UTxO Binding
Issuing tokens on Bitcoin is attractive due to its security and dominance, but its limited functionality creates challenges. Client-side validation (CSV) is a common workaround, using off-chain data with on-chain verification, though it risks data loss and withholding. This paper introduces UTxO binding, a framework that links a Bitcoin UTxO to one on an auxiliary chain, providing data storage and programmability. The authors prove its security and implement it using Nervos CKB.
From State Differences to Scaling: Citrea’s Fee Mechanism for Bitcoin
The Citrea team has designed a new fee mechanism to enhance Bitcoin’s scalability without compromising security. It only records essential state differences (i.e., state slot changes) on the Bitcoin main chain, using zero-knowledge proofs to ensure verifiability and Bitcoin security while drastically reducing state inscription costs. Optimizations include: replacing
codefield withcode_hash, compressing state data using a highly efficient compression algorithm Brotli, and analyzing historical Ethereum block data to estimate each transaction’s impact on cumulative state differences—enabling a discount to each transaction.Second: A New Ark Implementation Launched on Bitcoin Signet
Second, a protocol based on Ark to improve Bitcoin transaction throughput, has launched Bark, a test implementation on Bitcoin Signet.
Ark makes Bitcoin transactions faster, cheaper, and more private, allowing more users and transactions per block. However, funds stored non-custodially via Ark can expire if unused, making it slightly less trustless than mainchain transactions.
BitLayer Optimizes BitVM Bridge Protocol and Demonstrates on Testnet
Bitlayer BitVM Bridge protocol is an optimized adaptation of the bridge protocol outlined in the BitVM2 paper, to improve efficiency, scalability, and security—especially for high-risk cross-chain transactions.
In this article, two key testnet demos on bitvmnet (a BitVM-dedicated testnet) demonstrate how the protocol can:
-
Effectively thwart fraudulent reclaim attempts by brokers.
-
Protect honest brokers from malicious or baseless challenges.
Cardano Enables Bitcoin DeFi via BitVMX and Lightning Hydra
Cardano is integrating with Bitcoin through Lightning Hydra and BitVMX to enable secure and scalable Bitcoin DeFi.
Zcash’s Tachyon Upgrade: Toward Scalable Oblivious Synchronization
Zcash has unveiled project Tachyon, a proposal to scale Zcash by changing how wallets sync and prove ownership of notes. Instead of scanning the entire blockchain, wallets track only their own nullifiers and receive succinct proofs from untrusted, oblivious sync servers. Transactions include proofs of wallet state (using recursive SNARKs), allowing nodes to verify them without keeping the full history. Notes are exchanged out-of-band, reducing on-chain data and improving privacy. In the nominal case, users get fast sync, lightweight wallets, and strong privacy, without the need to trust the network.
Podcast | Why the Future of Bitcoin Mining is Distributed
In this podcast, Professor Troy Cross discusses the centralization of Bitcoin mining and argues convincingly for hashrate decentralization. While economies of scale have led to mega mining operations, he sees economic imperative that will drive mining toward a globally distributed future—not dominated by the U.S.—ensuring neutrality and resilience against state-level threats.
Binance Report|Crypto Industry Map March 2025
This report provides an overview of projects using a framework that divides crypto into four core ecosystems—Infrastructure, DeFi, NFT, and Gaming—and four trending sectors: Stablecoins, RWA, AI, and DeSci.
For infrastructure, five key pillars are identified: scalability & fairness, data availability & tooling, security & privacy, cloud networks, and connectivity. The report also maps out and categorizes the major projects and solutions currently on the market.

Top Reads on Blockchain and Beyond
A Game-Theoretic Approach to Bitcoin’s Valuation in Equilibrium
The author presents a game-theoretic argument for why Bitcoin will emerge as the optimal unit of account in equilibrium. The argument is based upon the observation that a generally agreed upon unit of account that represents a constant share of total wealth (equal to the totality of all other economic utility) will naturally create price signals that passively stabilize the macroeconomy, without requiring external intervention.
Bitcoin’s unique properties—finite supply, inertness, fungibility, accessibility, and ownership history—position it as the leading candidate to emerge as this unit.
Neo: Lattice-Based Folding Scheme for CCS Over Small Fields and Pay-Per-Bit Commitments
This paper introduces Neo, a new lattice-based folding scheme for CCS, an NP-complete relation that generalizes R1CS, Plonkish, and AIR. Neo's folding scheme can be viewed as adapting the folding scheme in HyperNova (CRYPTO'24), which assumes elliptic-curve based linearly homomorphic commitments, to the lattice setting. Unlike HyperNova, Neo can use “small” prime fields (e.g., over the Goldilocks prime). Additionally, Neo provides plausible post-quantum security.
Social Scalability: Key to Massive Value Accumulation in Crypto
Social scalability, a concept first proposed by Nick Szabo in his 2017 article Money, Blockchains, and Social Scalability, is further explored in this thread. Here, “social scalability” refers to an institution's ability to allow the maximum number of people to have skin in the game and win. It’s seen as the main reason crypto has become a $2.9T asset class today and a key driver of value accumulation in the coming decade.
The author argues that two critical ingredients for long-term social scalability are credible neutrality and utility. Currently, only BTC and ETH have this potential, yet neither strikes a perfect balance between the two. The author notes that there is not yet a strong narrative around social scalability, and concludes by emphasizing the importance of focusing on long-term value and resisting the temptation of short-term market narratives.
-
-
@ 3b3a42d3:d192e325
2025-04-10 08:57:51
Atomic Signature Swaps (ASS) over Nostr is a protocol for atomically exchanging Schnorr signatures using Nostr events for orchestration. This new primitive enables multiple interesting applications like:
- Getting paid to publish specific Nostr events
- Issuing automatic payment receipts
- Contract signing in exchange for payment
- P2P asset exchanges
- Trading and enforcement of asset option contracts
- Payment in exchange for Nostr-based credentials or access tokens
- Exchanging GMs 🌞
It only requires that (i) the involved signatures be Schnorr signatures using the secp256k1 curve and that (ii) at least one of those signatures be accessible to both parties. These requirements are naturally met by Nostr events (published to relays), Taproot transactions (published to the mempool and later to the blockchain), and Cashu payments (using mints that support NUT-07, allowing any pair of these signatures to be swapped atomically.
How the Cryptographic Magic Works 🪄
This is a Schnorr signature
(Zₓ, s):s = z + H(Zₓ || P || m)⋅kIf you haven't seen it before, don't worry, neither did I until three weeks ago.
The signature scalar s is the the value a signer with private key
k(and public keyP = k⋅G) must calculate to prove his commitment over the messagemgiven a randomly generated noncez(Zₓis just the x-coordinate of the public pointZ = z⋅G).His a hash function (sha256 with the tag "BIP0340/challenge" when dealing with BIP340),||just means to concatenate andGis the generator point of the elliptic curve, used to derive public values from private ones.Now that you understand what this equation means, let's just rename
z = r + t. We can do that,zis just a randomly generated number that can be represented as the sum of two other numbers. It also follows thatz⋅G = r⋅G + t⋅G ⇔ Z = R + T. Putting it all back into the definition of a Schnorr signature we get:s = (r + t) + H((R + T)ₓ || P || m)⋅kWhich is the same as:
s = sₐ + twheresₐ = r + H((R + T)ₓ || P || m)⋅ksₐis what we call the adaptor signature scalar) and t is the secret.((R + T)ₓ, sₐ)is an incomplete signature that just becomes valid by add the secret t to thesₐ:s = sₐ + tWhat is also important for our purposes is that by getting access to the valid signature s, one can also extract t from it by just subtracting
sₐ:t = s - sₐThe specific value of
tdepends on our choice of the public pointT, sinceRis just a public point derived from a randomly generated noncer.So how do we choose
Tso that it requires the secret t to be the signature over a specific messagem'by an specific public keyP'? (without knowing the value oft)Let's start with the definition of t as a valid Schnorr signature by P' over m':
t = r' + H(R'ₓ || P' || m')⋅k' ⇔ t⋅G = r'⋅G + H(R'ₓ || P' || m')⋅k'⋅GThat is the same as:
T = R' + H(R'ₓ || P' || m')⋅P'Notice that in order to calculate the appropriate
Tthat requirestto be an specific signature scalar, we only need to know the public nonceR'used to generate that signature.In summary: in order to atomically swap Schnorr signatures, one party
P'must provide a public nonceR', while the other partyPmust provide an adaptor signature using that nonce:sₐ = r + H((R + T)ₓ || P || m)⋅kwhereT = R' + H(R'ₓ || P' || m')⋅P'P'(the nonce provider) can then add his own signature t to the adaptor signaturesₐin order to get a valid signature byP, i.e.s = sₐ + t. When he publishes this signature (as a Nostr event, Cashu transaction or Taproot transaction), it becomes accessible toPthat can now extract the signaturetbyP'and also make use of it.Important considerations
A signature may not be useful at the end of the swap if it unlocks funds that have already been spent, or that are vulnerable to fee bidding wars.
When a swap involves a Taproot UTXO, it must always use a 2-of-2 multisig timelock to avoid those issues.
Cashu tokens do not require this measure when its signature is revealed first, because the mint won't reveal the other signature if they can't be successfully claimed, but they also require a 2-of-2 multisig timelock when its signature is only revealed last (what is unavoidable in cashu for cashu swaps).
For Nostr events, whoever receives the signature first needs to publish it to at least one relay that is accessible by the other party. This is a reasonable expectation in most cases, but may be an issue if the event kind involved is meant to be used privately.
How to Orchestrate the Swap over Nostr?
Before going into the specific event kinds, it is important to recognize what are the requirements they must meet and what are the concerns they must address. There are mainly three requirements:
- Both parties must agree on the messages they are going to sign
- One party must provide a public nonce
- The other party must provide an adaptor signature using that nonce
There is also a fundamental asymmetry in the roles of both parties, resulting in the following significant downsides for the party that generates the adaptor signature:
- NIP-07 and remote signers do not currently support the generation of adaptor signatures, so he must either insert his nsec in the client or use a fork of another signer
- There is an overhead of retrieving the completed signature containing the secret, either from the blockchain, mint endpoint or finding the appropriate relay
- There is risk he may not get his side of the deal if the other party only uses his signature privately, as I have already mentioned
- There is risk of losing funds by not extracting or using the signature before its timelock expires. The other party has no risk since his own signature won't be exposed by just not using the signature he received.
The protocol must meet all those requirements, allowing for some kind of role negotiation and while trying to reduce the necessary hops needed to complete the swap.
Swap Proposal Event (kind:455)
This event enables a proposer and his counterparty to agree on the specific messages whose signatures they intend to exchange. The
contentfield is the following stringified JSON:{ "give": <signature spec (required)>, "take": <signature spec (required)>, "exp": <expiration timestamp (optional)>, "role": "<adaptor | nonce (optional)>", "description": "<Info about the proposal (optional)>", "nonce": "<Signature public nonce (optional)>", "enc_s": "<Encrypted signature scalar (optional)>" }The field
roleindicates what the proposer will provide during the swap, either the nonce or the adaptor. When this optional field is not provided, the counterparty may decide whether he will send a nonce back in a Swap Nonce event or a Swap Adaptor event using thenonce(optionally) provided by in the Swap Proposal in order to avoid one hop of interaction.The
enc_sfield may be used to store the encrypted scalar of the signature associated with thenonce, since this information is necessary later when completing the adaptor signature received from the other party.A
signature specspecifies thetypeand all necessary information for producing and verifying a given signature. In the case of signatures for Nostr events, it contain a template with all the fields, exceptpubkey,idandsig:{ "type": "nostr", "template": { "kind": "<kind>" "content": "<content>" "tags": [ … ], "created_at": "<created_at>" } }In the case of Cashu payments, a simplified
signature specjust needs to specify the payment amount and an array of mints trusted by the proposer:{ "type": "cashu", "amount": "<amount>", "mint": ["<acceptable mint_url>", …] }This works when the payer provides the adaptor signature, but it still needs to be extended to also work when the payer is the one receiving the adaptor signature. In the later case, the
signature specmust also include atimelockand the derived public keysYof each Cashu Proof, but for now let's just ignore this situation. It should be mentioned that the mint must be trusted by both parties and also support Token state check (NUT-07) for revealing the completed adaptor signature and P2PK spending conditions (NUT-11) for the cryptographic scheme to work.The
tagsare:"p", the proposal counterparty's public key (required)"a", akind:30455Swap Listing event or an application specific version of it (optional)
Forget about this Swap Listing event for now, I will get to it later...
Swap Nonce Event (kind:456) - Optional
This is an optional event for the Swap Proposal receiver to provide the public nonce of his signature when the proposal does not include a nonce or when he does not want to provide the adaptor signature due to the downsides previously mentioned. The
contentfield is the following stringified JSON:{ "nonce": "<Signature public nonce>", "enc_s": "<Encrypted signature scalar (optional)>" }And the
tagsmust contain:"e", akind:455Swap Proposal Event (required)"p", the counterparty's public key (required)
Swap Adaptor Event (kind:457)
The
contentfield is the following stringified JSON:{ "adaptors": [ { "sa": "<Adaptor signature scalar>", "R": "<Signer's public nonce (including parity byte)>", "T": "<Adaptor point (including parity byte)>", "Y": "<Cashu proof derived public key (if applicable)>", }, …], "cashu": "<Cashu V4 token (if applicable)>" }And the
tagsmust contain:"e", akind:455Swap Proposal Event (required)"p", the counterparty's public key (required)
Discoverability
The Swap Listing event previously mentioned as an optional tag in the Swap Proposal may be used to find an appropriate counterparty for a swap. It allows a user to announce what he wants to accomplish, what his requirements are and what is still open for negotiation.
Swap Listing Event (kind:30455)
The
contentfield is the following stringified JSON:{ "description": "<Information about the listing (required)>", "give": <partial signature spec (optional)>, "take": <partial signature spec (optional)>, "examples: [<take signature spec>], // optional "exp": <expiration timestamp (optional)>, "role": "<adaptor | nonce (optional)>" }The
descriptionfield describes the restrictions on counterparties and signatures the user is willing to accept.A
partial signature specis an incompletesignature specused in Swap Proposal eventskind:455where omitting fields signals that they are still open for negotiation.The
examplesfield is an array ofsignature specsthe user would be willing totake.The
tagsare:"d", a unique listing id (required)"s", the status of the listingdraft | open | closed(required)"t", topics related to this listing (optional)"p", public keys to notify about the proposal (optional)
Application Specific Swap Listings
Since Swap Listings are still fairly generic, it is expected that specific use cases define new event kinds based on the generic listing. Those application specific swap listing would be easier to filter by clients and may impose restrictions and add new fields and/or tags. The following are some examples under development:
Sponsored Events
This listing is designed for users looking to promote content on the Nostr network, as well as for those who want to monetize their accounts by sharing curated sponsored content with their existing audiences.
It follows the same format as the generic Swap Listing event, but uses the
kind:30456instead.The following new tags are included:
"k", event kind being sponsored (required)"title", campaign title (optional)
It is required that at least one
signature spec(giveand/ortake) must have"type": "nostr"and also contain the following tag["sponsor", "<pubkey>", "<attestation>"]with the sponsor's public key and his signature over the signature spec without the sponsor tag as his attestation. This last requirement enables clients to disclose and/or filter sponsored events.Asset Swaps
This listing is designed for users looking for counterparties to swap different assets that can be transferred using Schnorr signatures, like any unit of Cashu tokens, Bitcoin or other asset IOUs issued using Taproot.
It follows the same format as the generic Swap Listing event, but uses the
kind:30457instead.It requires the following additional tags:
"t", asset pair to be swapped (e.g."btcusd")"t", asset being offered (e.g."btc")"t", accepted payment method (e.g."cashu","taproot")
Swap Negotiation
From finding an appropriate Swap Listing to publishing a Swap Proposal, there may be some kind of negotiation between the involved parties, e.g. agreeing on the amount to be paid by one of the parties or the exact content of a Nostr event signed by the other party. There are many ways to accomplish that and clients may implement it as they see fit for their specific goals. Some suggestions are:
- Adding
kind:1111Comments to the Swap Listing or an existing Swap Proposal - Exchanging tentative Swap Proposals back and forth until an agreement is reached
- Simple exchanges of DMs
- Out of band communication (e.g. Signal)
Work to be done
I've been refining this specification as I develop some proof-of-concept clients to experience its flaws and trade-offs in practice. I left the signature spec for Taproot signatures out of the current document as I still have to experiment with it. I will probably find some important orchestration issues related to dealing with
2-of-2 multisig timelocks, which also affects Cashu transactions when spent last, that may require further adjustments to what was presented here.The main goal of this article is to find other people interested in this concept and willing to provide valuable feedback before a PR is opened in the NIPs repository for broader discussions.
References
- GM Swap- Nostr client for atomically exchanging GM notes. Live demo available here.
- Sig4Sats Script - A Typescript script demonstrating the swap of a Cashu payment for a signed Nostr event.
- Loudr- Nostr client under development for sponsoring the publication of Nostr events. Live demo available at loudr.me.
- Poelstra, A. (2017). Scriptless Scripts. Blockstream Research. https://github.com/BlockstreamResearch/scriptless-scripts
-
@ f7d424b5:618c51e8
2025-05-04 19:19:43
Listen to the new episode here!
Finally some good news. Good new games, worthwhile remakes, and bloggers facing the consequences of their actions. Gaming is healing. Let's talk about it!
Stuff cited:
Obligatory:
- Discuss this episode on OUR NEW FORUM
- Get the RSS and Subscribe (this is a new feed URL, but the old one redirects here too!)
- Get a modern podcast app to use that RSS feed on at newpodcastapps.com
- Or listen to the show on the forum using the embedded Podverse player!
- Send your complaints here
Reminder that this is a Value4Value podcast so any support you can give us via a modern podcasting app is greatly appreciated and we will never bow to corporate sponsors!
-
@ ec9bd746:df11a9d0
2025-04-06 08:06:08
🌍 Time Window:
🕘 When: Every even week on Sunday at 9:00 PM CET
🗺️ Where: https://cornychat.com/eurocornStart: 21:00 CET (Prague, UTC+1)
End: approx. 02:00 CET (Prague, UTC+1, next day)
Duration: usually 5+ hours.| Region | Local Time Window | Convenience Level | |-----------------------------------------------------|--------------------------------------------|---------------------------------------------------------| | Europe (CET, Prague) 🇨🇿🇩🇪 | 21:00–02:00 CET | ✅ Very Good; evening & night | | East Coast North America (EST) 🇺🇸🇨🇦 | 15:00–20:00 EST | ✅ Very Good; afternoon & early evening | | West Coast North America (PST) 🇺🇸🇨🇦 | 12:00–17:00 PST | ✅ Very Good; midday & afternoon | | Central America (CST) 🇲🇽🇨🇷🇬🇹 | 14:00–19:00 CST | ✅ Very Good; afternoon & evening | | South America West (Peru/Colombia PET/COT) 🇵🇪🇨🇴 | 15:00–20:00 PET/COT | ✅ Very Good; afternoon & evening | | South America East (Brazil/Argentina/Chile, BRT/ART/CLST) 🇧🇷🇦🇷🇨🇱 | 17:00–22:00 BRT/ART/CLST | ✅ Very Good; early evening | | United Kingdom/Ireland (GMT) 🇬🇧🇮🇪 | 20:00–01:00 GMT | ✅ Very Good; evening hours (midnight convenient) | | Eastern Europe (EET) 🇷🇴🇬🇷🇺🇦 | 22:00–03:00 EET | ✅ Good; late evening & early night (slightly late) | | Africa (South Africa, SAST) 🇿🇦 | 22:00–03:00 SAST | ✅ Good; late evening & overnight (late-night common) | | New Zealand (NZDT) 🇳🇿 | 09:00–14:00 NZDT (next day) | ✅ Good; weekday morning & afternoon | | Australia (AEDT, Sydney) 🇦🇺 | 07:00–12:00 AEDT (next day) | ✅ Good; weekday morning to noon | | East Africa (Kenya, EAT) 🇰🇪 | 23:00–04:00 EAT | ⚠️ Slightly late (night hours; late night common) | | Russia (Moscow, MSK) 🇷🇺 | 23:00–04:00 MSK | ⚠️ Slightly late (join at start is fine, very late night) | | Middle East (UAE, GST) 🇦🇪🇴🇲 | 00:00–05:00 GST (next day) | ⚠️ Late night start (midnight & early morning, but shorter attendance plausible)| | Japan/Korea (JST/KST) 🇯🇵🇰🇷 | 05:00–10:00 JST/KST (next day) | ⚠️ Early; convenient joining from ~07:00 onwards possible | | China (Beijing, CST) 🇨🇳 | 04:00–09:00 CST (next day) | ❌ Challenging; very early morning start (better ~07:00 onwards) | | India (IST) 🇮🇳 | 01:30–06:30 IST (next day) | ❌ Very challenging; overnight timing typically difficult|
-
@ dbc27e2e:b1dd0b0b
2025-04-05 20:44:00
This method focuses on the amount of water in the first pour, which ultimately defines the coffee’s acidity and sweetness (more water = more acidity, less water = more sweetness). For the remainder of the brew, the water is divided into equal parts according to the strength you wish to attain.

Dose:
20g coffee (Coarse ground coffee) 300mL water (92°C / 197.6°F) Time: 3:30Instructions:
- Pour 1: 0:00 > 50mL (42% of 120mL = 40% of total – less water in the ratio, targeting sweetness.)
- Pour 2: 0:45 > 70mL (58% of 120mL = 40% of total – the top up for 40% of total.)
- Pour 3: 1:30 > 60mL (The remaining water is 180mL / 3 pours = 60mL per pour)
- Pour 4: 2:10 > 60mL
- Pour 5: 2:40 > 60mL
- Remove the V60 at 3:30
-
@ 7ef5f1b1:0e0fcd27
2025-05-04 18:28:05
A monthly newsletter by The 256 Foundation

May 2025
Introduction:
Welcome to the fifth newsletter produced by The 256 Foundation! April was a jam-packed month for the Foundation with events ranging from launching three grant projects to the first official Ember One release. The 256 Foundation has been laser focused on our mission to dismantle the proprietary mining empire, signing off on a productive month with the one-finger salute to the incumbent mining cartel.
 [IMG-001] Hilarious meme from @CincoDoggos
[IMG-001] Hilarious meme from @CincoDoggosDive in to catch up on the latest news, mining industry developments, progress updates on grant projects, Actionable Advice on helping test Hydra Pool, and the current state of the Bitcoin network.
Definitions:
DOJ = Department of Justice
SDNY = Southern District of New York
BTC = Bitcoin
SD = Secure Digital
Th/s = Terahash per second
OSMU = Open Source Miners United
tx = transaction
PSBT = Partially Signed Bitcoin Transaction
FIFO = First In First Out
PPLNS = Pay Per Last N Shares
GB = Gigabyte
RAM = Random Access Memory
ASIC = Application Specific Integrated Circuit
Eh/s = Exahash per second
Ph/s = Petahash per second
News:
April 7: the first of a few notable news items that relate to the Samourai Wallet case, the US Deputy Attorney General, Todd Blanche, issued a memorandum titled “Ending Regulation By Prosecution”. The memo makes the DOJ’s position on the matter crystal clear, stating; “Specifically, the Department will no longer target virtual currency exchanges, mixing and tumbling services, and offline wallets for the acts of their end users or unwitting violations of regulations…”. However, despite the clarity from the DOJ, the SDNY (sometimes referred to as the “Sovereign District” for it’s history of acting independently of the DOJ) has yet to budge on dropping the charges against the Samourai Wallet developers. Many are baffled at the SDNY’s continued defiance of the Trump Administration’s directives, especially in light of the recent suspensions and resignations that swept through the SDNY office in the wake of several attorneys refusing to comply with the DOJ’s directive to drop the charges against New York City Mayor, Eric Adams. There is speculation that the missing piece was Trump’s pick to take the helm at the SDNY, Jay Clayton, who was yet to receive his Senate confirmation and didn’t officially start in his new role until April 22. In light of the Blanche Memo, on April 29, the prosecution and defense jointly filed a letter requesting additional time for the prosecution to determine it’s position on the matter and decide if they are going to do the right thing, comply with the DOJ, and drop the charges. Catch up on what’s at stake in this case with an appearance by Diverter on the Unbounded Podcast from April 24, the one-year anniversary of the Samourai Wallet developer’s arrest. This is the most important case facing Bitcoiners as the precedence set in this matter will have ripple effects that touch all areas of the ecosystem. The logic used by SDNY prosecutors argues that non-custodial wallet developers transfer money in the same way a frying pan transfers heat but does not “control” the heat. Essentially saying that facilitating the transfer of funds on behalf of the public by any means constitutes money transmission and thus requires a money transmitter license. All non-custodial wallets (software or hardware), node operators, and even miners would fall neatly into these dangerously generalized and vague definitions. If the SDNY wins this case, all Bitcoiners lose. Make a contribution to the defense fund here.
April 11: solo miner with ~230Th/s solves Block #891952 on Solo CK Pool, bagging 3.11 BTC in the process. This will never not be exciting to see a regular person with a modest amount of hashrate risk it all and reap all the mining reward. The more solo miners there are out there, the more often this should occur.
April 15: B10C publishes new article on mining centralization. The article analyzes the hashrate share of the currently five biggest pools and presents a Mining Centralization Index. The results demonstrate that only six pools are mining more than 95% of the blocks on the Bitcoin Network. The article goes on to explain that during the period between 2019 and 2022, the top two pools had ~35% of the network hashrate and the top six pools had ~75%. By December 2023 those numbers grew to the top two pools having 55% of the network hashrate and the top six having ~90%. Currently, the top six pools are mining ~95% of the blocks.
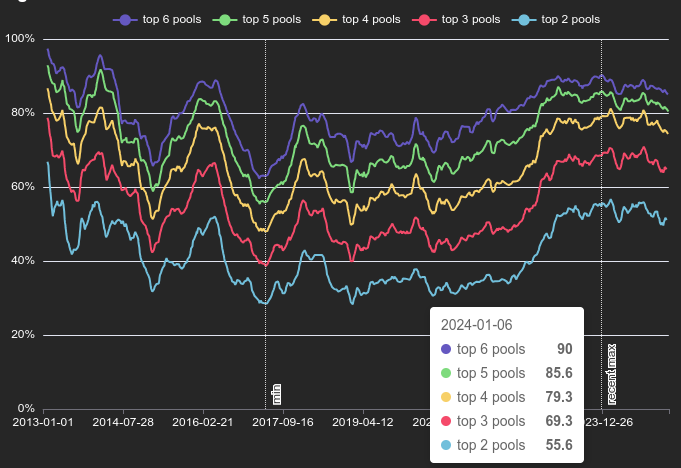 [IMG-002] Mining Centralization Index by @0xB10C
[IMG-002] Mining Centralization Index by @0xB10CB10C concludes the article with a solution that is worth highlighting: “More individuals home-mining with small miners help too, however, the home-mining hashrate is currently still negligible compared to the industrial hashrate.”
April 15: As if miner centralization and proprietary hardware weren’t reason enough to focus on open-source mining solutions, leave it to Bitmain to release an S21+ firmware update that blocks connections to OCEAN and Braiins pools. This is the latest known sketchy development from Bitmain following years of shady behavior like Antbleed where miners would phone home, Covert ASIC Boost where miners could use a cryptographic trick to increase efficiency, the infamous Fork Wars, mining empty blocks, and removing the SD card slots. For a mining business to build it’s entire operation on a fragile foundation like the closed and proprietary Bitmain hardware is asking for trouble. Bitcoin miners need to remain flexible and agile and they need to be able to adapt to changes instantly – the sort of freedoms that only open-source Bitcoin mining solutions are bringing to the table.
Free & Open Mining Industry Developments:
The development will not stop until Bitcoin mining is free and open… and then it will get even better. Innovators did not disappoint in April, here are nine note-worthy events:
April 5: 256 Foundation officially launches three more grant projects. These will be covered in detail in the Grant Project Updates section but April 5 was a symbolic day to mark the official start because of the 6102 anniversary. A reminder of the asymmetric advantage freedom tech like Bitcoin empowers individuals with to protect their rights and freedoms, with open-source development being central to those ends.
April 5: Low profile ICE Tower+ for the Bitaxe Gamma 601 introduced by @Pleb_Style featuring four heat pipes, 2 copper shims, and a 60mm Noctua fan resulting in up to 2Th/s. European customers can pick up the complete upgrade kit from the Pleb Style online store for $93.00.
 IMG-003] Pleb Style ICE Tower+ upgrade kit
IMG-003] Pleb Style ICE Tower+ upgrade kitApril 8: Solo Satoshi spells out issues with Bitaxe knockoffs, like Lucky Miner, in a detailed article titled The Hidden Cost of Bitaxe Clones. This concept can be confusing for some people initially, Bitaxe is open-source, right? So anyone can do whatever they want… right? Based on the specific open-source license of the Bitaxe hardware, CERN-OHL-S, and the firmware, GPLv3, derivative works are supposed to make the source available. Respecting the license creates a feed back loop where those who benefit from the open-source work of those who came before them contribute back their own modifications and source files to the open-source community so that others can benefit from the new developments. Unfortunately, when the license is disrespected what ends up happening is that manufacturers make undocumented changes to the components in the hardware and firmware which yields unexpected results creating a number of issues like the Bitaxe overheating, not connecting to WiFi, or flat out failure. This issue gets further compounded when the people who purchased the knockoffs go to a community support forum, like OSMU, for help. There, a number of people rack their brains and spend their valuable time trying to replicate the issues only to find out that they cannot replicate the issues since the person who purchased the knockoff has something different than the known Bitaxe model and the distributor who sold the knockoff did not document those changes. The open-source licenses are maintaining the end-users’ freedom to do what they want but if the license is disrespected then that freedom vanishes along with details about whatever was changed. There is a list maintained on the Bitaxe website of legitimate distributors who uphold the open-source licenses, if you want to buy a Bitaxe, use this list to ensure the open-source community is being supported instead of leeched off of.
April 8: The Mempool Open Source Project v3.2.0 launches with a number of highlights including a new UTXO bubble chart, address poisoning detection, and a tx/PSBT preview feature. The GitHub repo can be found here if you want to self-host an instance from your own node or you can access the website here. The Mempool Open Source Project is a great blockchain explorer with a rich feature set and helpful visualization tools.
 [IMG-004] Address poisoning example
[IMG-004] Address poisoning exampleApril 8: @k1ix publishes bitaxe-raw, a firmware for the ESP32S3 found on Bitaxes which enables the user to send and receive raw bytes over USB serial to and from the Bitaxe. This is a helpful tool for research and development and a tool that is being leveraged at The 256 Foundation for helping with the Mujina miner firmware development. The bitaxe-raw GitHub repo can be found here.
April 14: Rev.Hodl compiles many of his homestead-meets-mining adaptations including how he cooks meat sous-vide style, heats his tap water to 150°F, runs a hashing space heater, and how he upgraded his clothes dryer to use Bitcoin miners. If you are interested in seeing some creative and resourceful home mining integrations, look no further. The fact that Rev.Hodl was able to do all this with closed-source proprietary Bitcoin mining hardware makes a very bullish case for the innovations coming down the pike once the hardware and firmware are open-source and people can gain full control over their mining appliances.
April 21: Hashpool explained on The Home Mining Podcast, an innovative Bitcoin mining pool development that trades mining shares for ecash tokens. The pool issues an “ehash” token for every submitted share, the pool uses ecash epochs to approximate the age of those shares in a FIFO order as they accrue value, a rotating key set is used to eventually expire them, and finally the pool publishes verification proofs for each epoch and each solved block. The ehash is provably not inflatable and payouts are similar to the PPLNS model. In addition to the maturity window where ehash tokens are accruing value, there is also a redemption window where the ehash tokens can be traded in to the mint for bitcoin. There is also a bitcoin++ presentation from earlier this year where @vnprc explains the architecture.
April 26: Boerst adds a new page on stratum.work for block template details, you can click on any mining pool and see the extended details and visualization of their current block template. Updates happen in real-time. The page displays all available template data including the OP_RETURN field and if the pool is merge mining, like with RSK, then that will be displayed too. Stratum dot work is a great project that offers helpful mining insights, be sure to book mark it if you haven’t already.
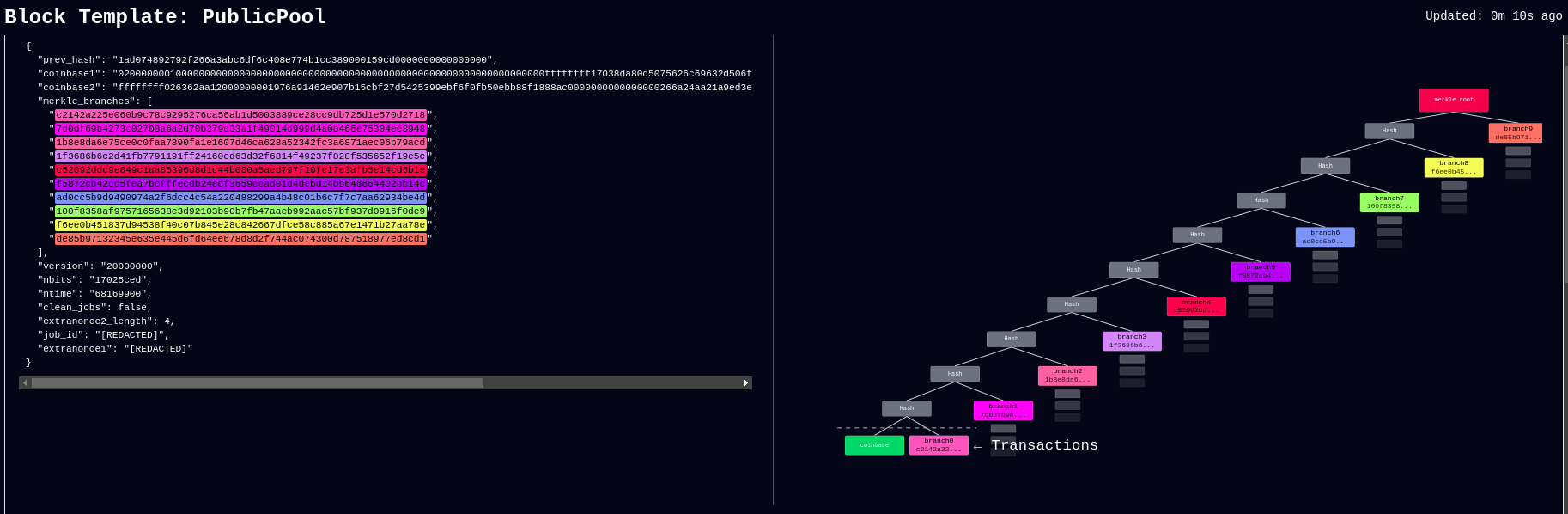 [IMG-005] New stratum.work live template page
[IMG-005] New stratum.work live template pageApril 27: Public Pool patches Nerdminer exploit that made it possible to create the impression that a user’s Nerdminer was hashing many times more than it actually was. This exploit was used by scammers trying to convince people that they had a special firmware for the Nerminer that would make it hash much better. In actuality, Public Pool just wasn’t checking to see if submitted shares were duplicates or not. The scammers would just tweak the Nerdminer firmware so that valid shares were getting submitted five times, creating the impression that the miner was hashing at five times the actual hashrate. Thankfully this has been uncovered by the open-source community and Public Pool quickly addressed it on their end.
Grant Project Updates:
Three grant projects were launched on April 5, Mujina Mining Firmware, Hydra Pool, and Libre Board. Ember One was the first fully funded grant and launched in November 2024 for a six month duration.
Ember One:
@skot9000 is the lead engineer on the Ember One and April 30 marked the conclusion of the first grant cycle after six months of development culminating in a standardized hashboard featuring a ~100W power consumption, 12-24v input voltage range, USB-C data communication, on-board temperature sensors, and a 125mm x 125mm formfactor. There are several Ember One versions on the road map, each with a different kind of ASIC chip but staying true to the standardized features listed above. The first Ember One, the 00 version, was built with the Bitmain BM1362 ASIC chips. The first official release of the Ember One, v3, is available here. v4 is already being worked on and will incorporate a few circuit safety mechanisms that are pretty exciting, like protecting the ASIC chips in the event of a power supply failure. The firmware for the USB adaptor is available here. Initial testing firmware for the Ember One 00 can be found here and full firmware support will be coming soon with Mujina. The Ember One does not have an on-board controller so a separate, USB connected, control board is required. Control board support is coming soon with the Libre Board. There is an in-depth schematic review that was recorded with Skot and Ryan, the lead developer for Mujina, you can see that video here. Timing for starting the second Ember One cycle is to be determined but the next version of the Ember One is planned to have the Intel BZM2 ASICs. Learn more at emberone.org
Mujina Mining Firmware:
@ryankuester is the lead developer for the Mujina firmware project and since the project launched on April 5, he has been working diligently to build this firmware from scratch in Rust. By using the bitaxe-raw firmware mentioned above, over the last month Ryan has been able to use a Bitaxe to simulate an Ember One so that he can start building the necessary interfaces to communicate with the range of sensors, ASICs, work handling, and API requests that will be necessary. For example, using a logic analyzer, this is what the first signs of life look like when communicating with an ASIC chip, the orange trace is a message being sent to the ASIC and the red trace below it is the ASIC responding [IMG-006]. The next step is to see if work can be sent to the ASIC and results returned. The GitHub repo for Mujina is currently set to private until a solid foundation has been built. Learn more at mujina.org
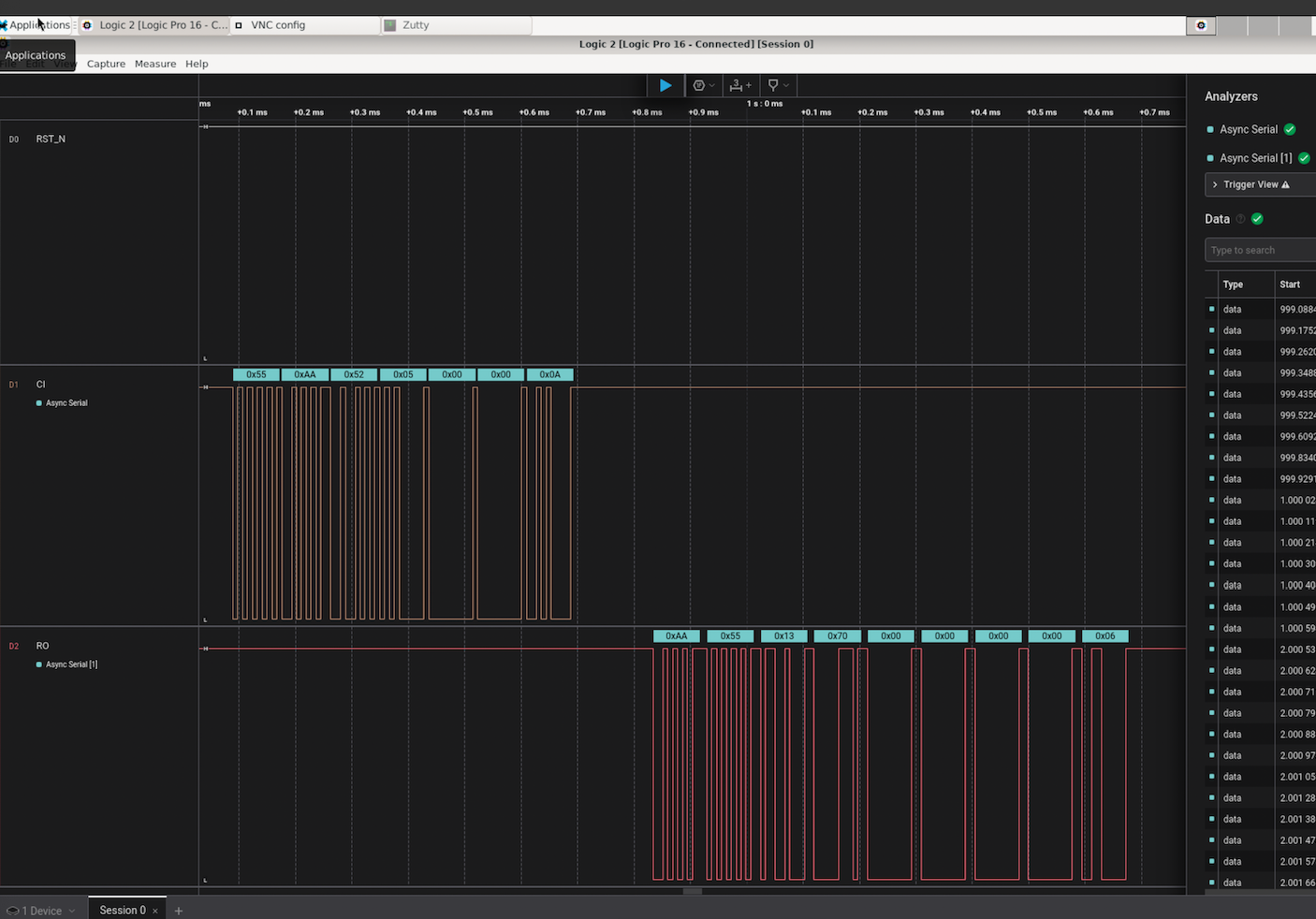 [IMG-006] First signs of life from an ASIC
[IMG-006] First signs of life from an ASICLibre Board:
@Schnitzel is the lead engineer for the Libre Board project and over the last month has been modifying the Raspberry Pi Compute Module I/O Board open-source design to fit the requirements for this project. For example, removing one of the two HDMI ports, adding the 40-pin header, and adapting the voltage regulator circuit so that it can accept the same 12-24vdc range as the Ember One hashboards. The GitHub repo can be found here, although there isn’t much to look at yet as the designs are still in the works. If you have feature requests, creating an issue in the GitHub repo would be a good place to start. Learn more at libreboard.org
Hydra Pool:
@jungly is the lead developer for Hydra Pool and over the last month he has developed a working early version of Hydra Pool specifically for the upcoming Telehash #2. Forked from CK Pool, this early version has been modified so that the payout goes to the 256 Foundation bitcoin address automatically. This way, users who are supporting the funderaiser with their hashrate do not need to copy/paste in the bitcoin address, they can just use any vanity username they want. Jungly was also able to get a great looking statistics dashboard forked from CKstats and modify it so that the data is populated from the Hydra Pool server instead of website crawling. After the Telehash, the next steps will be setting up deployment scripts for running Hydra Pool on a cloud server, support for storing shares in a database, and adding PPLNS support. The 256 Foundation is only running a publicly accessible server for the Telehash and the long term goals for Hydra Pool are that the users host their own instance. The 256 Foundation has no plans on becoming a mining pool operator. The following Actionable Advice column shows you how you can help test Hydra Pool. The GitHub repo for Hydra Pool can be found here. Learn more at hydrapool.org
Actionable Advice:
The 256 Foundation is looking for testers to help try out Hydra Pool. The current instance is on a hosted bare metal server in Florida and features 64 cores and 128 GB of RAM. One tester in Europe shared that they were only experiencing ~70ms of latency which is good. If you want to help test Hydra Pool out and give any feedback, you can follow the directions below and join The 256 Foundation public forum on Telegram here.
The first step is to configure your miner so that it is pointed to the Hydra Pool server. This can look different depending on your specific miner but generally speaking, from the settings page you can add the following URL:
stratum+tcp://stratum.hydrapool.org:3333On some miners, you don’t need the “stratum+tcp://” part or the port, “:3333”, in the URL dialog box and there may be separate dialog boxes for the port.
Use any vanity username you want, no need to add a BTC address. The test iteration of Hydra Pool is configured to payout to the 256 Foundation BTC address.
If your miner has a password field, you can just put “x” or “1234”, it doesn’t matter and this field is ignored.
Then save your changes and restart your miner. Here are two examples of what this can look like using a Futurebit Apollo and a Bitaxe:
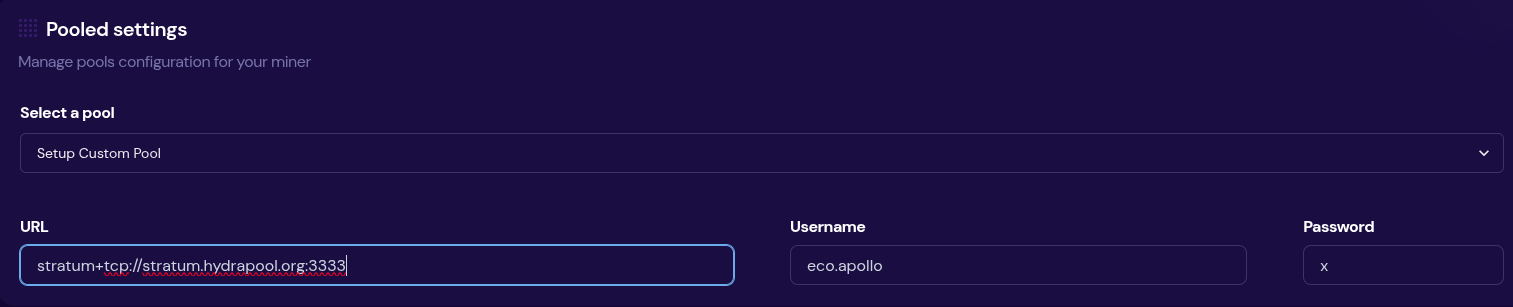 [IMG-007] Apollo configured to Hydra Pool
[IMG-007] Apollo configured to Hydra Pool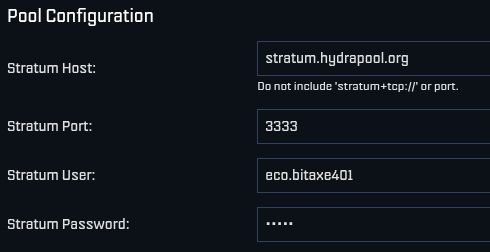 [IMG-008] Bitaxe Configured to Hydra Pool
[IMG-008] Bitaxe Configured to Hydra PoolOnce you get started, be sure to check stats.hydrapool.org to monitor the solo pool statistics.
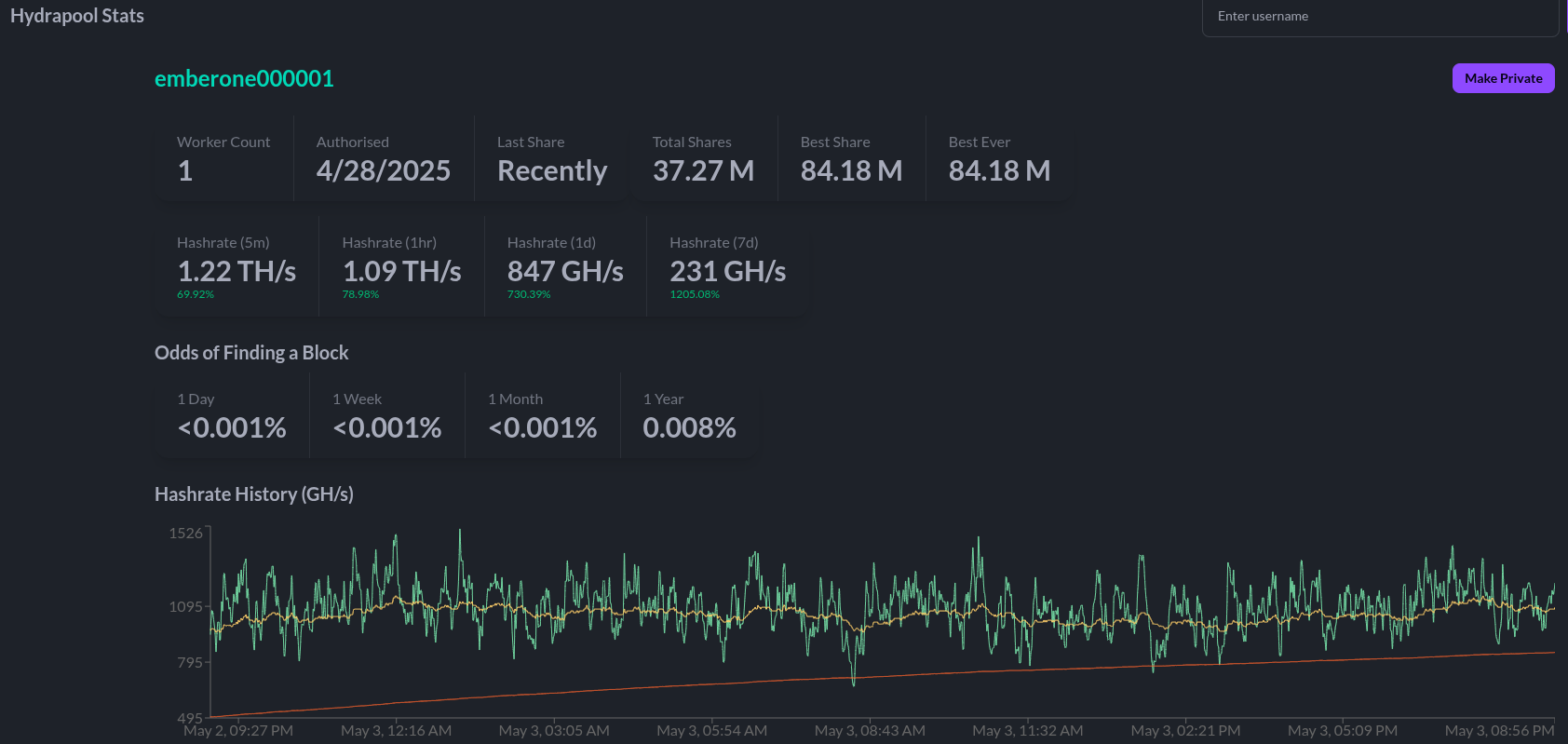 [IMG-009] Ember One hashing to Hydra Pool
[IMG-009] Ember One hashing to Hydra PoolAt the last Telehash there were over 350 entities pointing as much as 1.12Eh/s at the fundraiser at the peak. At the time the block was found there was closer to 800 Ph/s of hashrate. At this next Telehash, The 256 Foundation is looking to beat the previous records across the board. You can find all the Telehash details on the Meetup page here.
State of the Network:
Hashrate on the 14-day MA according to mempool.space increased from ~826 Eh/s to a peak of ~907 Eh/s on April 16 before cooling off and finishing the month at ~841 Eh/s, marking ~1.8% growth for the month.
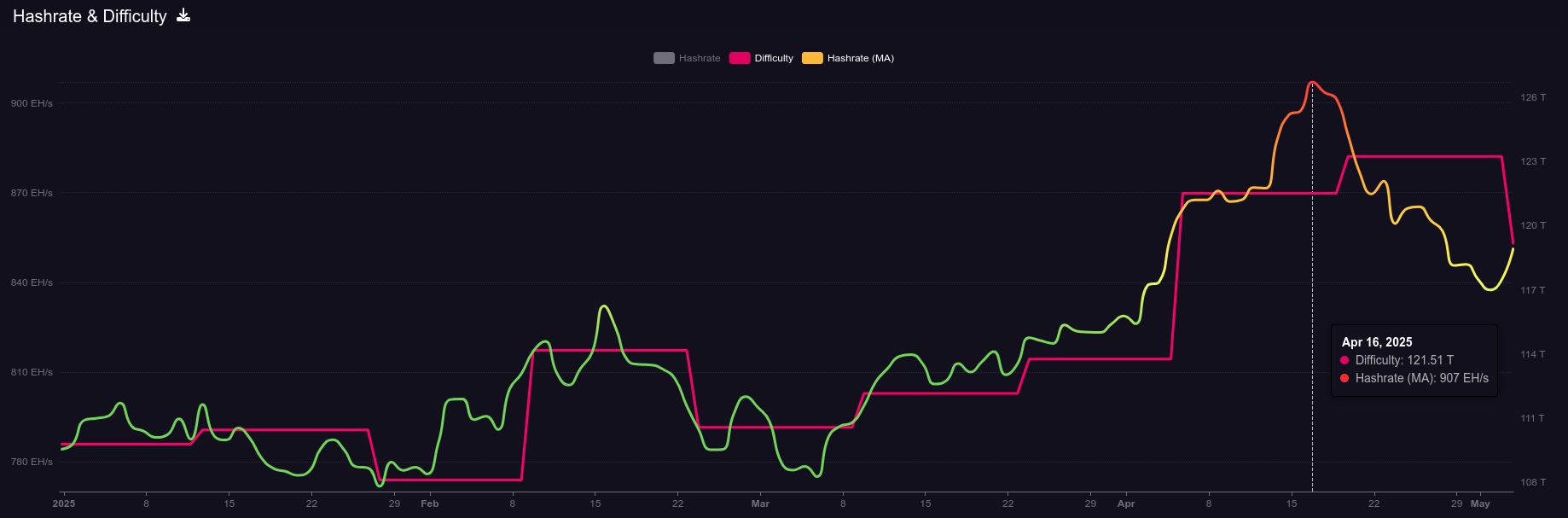 [IMG-010] 2025 hashrate/difficulty chart from mempool.space
[IMG-010] 2025 hashrate/difficulty chart from mempool.spaceDifficulty was 113.76T at it’s lowest in April and 123.23T at it’s highest, which is a 8.3% increase for the month. But difficulty dropped with Epoch #444 just after the end of the month on May 3 bringing a -3.3% downward adjustment. All together for 2025 up to Epoch #444, difficulty has gone up ~8.5%.
According to the Hashrate Index, ASIC prices have flat-lined over the last month. The more efficient miners like the <19 J/Th models are fetching $17.29 per terahash, models between 19J/Th – 25J/Th are selling for $11.05 per terahash, and models >25J/Th are selling for $3.20 per terahash. You can expect to pay roughly $4,000 for a new-gen miner with 230+ Th/s.
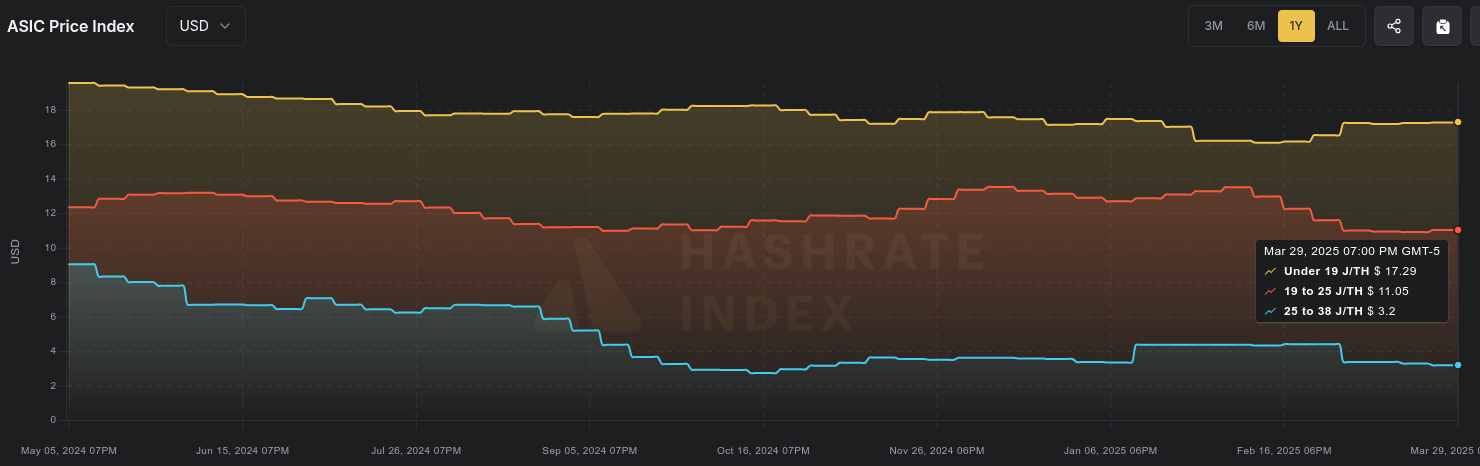 [IMG-011] Miner Prices from Luxor’s Hashrate Index
[IMG-011] Miner Prices from Luxor’s Hashrate IndexHashvalue over the month of April dropped from ~56,000 sats/Ph per day to ~52,000 sats/Ph per day, according to the new and improved Braiins Insights dashboard [IMG-012]. Hashprice started out at $46.00/Ph per day at the beginning of April and climbed to $49.00/Ph per day by the end of the month.
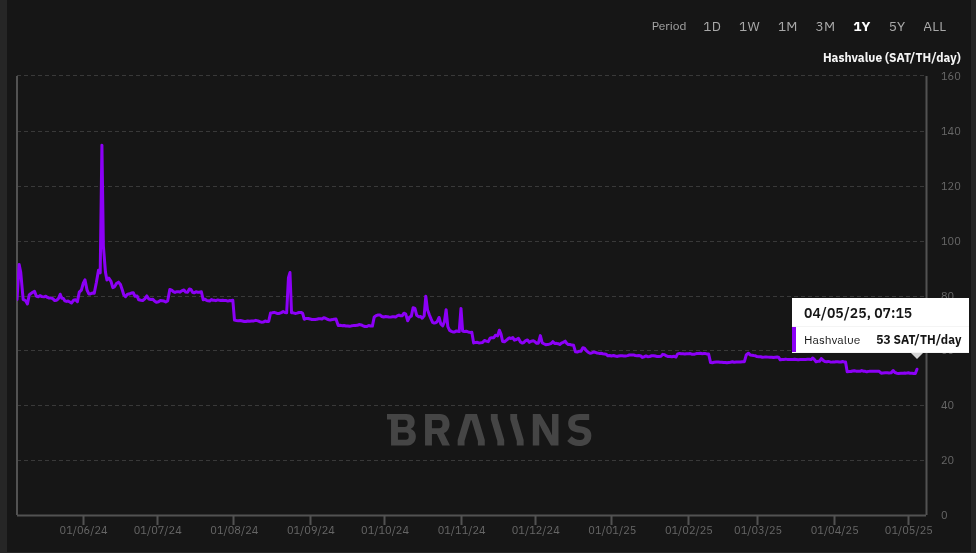 [IMG-012] Hashprice/Hashvalue from Braiins Insights
[IMG-012] Hashprice/Hashvalue from Braiins InsightsThe next halving will occur at block height 1,050,000 which should be in roughly 1,063 days or in other words ~154,650 blocks from time of publishing this newsletter.
Conclusion:
Thank you for reading the fifth 256 Foundation newsletter. Keep an eye out for more newsletters on a monthly basis in your email inbox by subscribing at 256foundation.org. Or you can download .pdf versions of the newsletters from there as well. You can also find these newsletters published in article form on Nostr.
If you haven’t done so already, be sure to RSVP for the Texas Energy & Mining Summit (“TEMS”) in Austin, Texas on May 6 & 7 for two days of the highest Bitcoin mining and energy signal in the industry, set in the intimate Bitcoin Commons, so you can meet and mingle with the best and brightest movers and shakers in the space.
 [IMG-013] TEMS 2025 flyer
[IMG-013] TEMS 2025 flyer While you’re at it, extend your stay and spend Cinco De Mayo with The 256 Foundation at our second fundraiser, Telehash #2. Everything is bigger in Texas, so set your expectations high for this one. All of the lead developers from the grant projects will be present to talk first-hand about how to dismantle the proprietary mining empire.
If you are interested in helping The 256 Foundation test Hydra Pool, then hopefully you found all the information you need to configure your miner in this issue.
 [IMG-014] FREE SAMOURAI
[IMG-014] FREE SAMOURAIIf you want to continue seeing developers build free and open solutions be sure to support the Samourai Wallet developers by making a tax-deductible contribution to their legal defense fund here. The first step in ensuring a future of free and open Bitcoin development starts with freeing these developers.
Live Free or Die,
-econoalchemist
-
@ c4f5e7a7:8856cac7
2024-09-27 08:20:16
Best viewed on Habla, YakiHonne or Highlighter.
TL;DR
This article explores the links between public, community-driven data sources (such as OpenStreetMap) and private, cryptographically-owned data found on networks such as Nostr.
The following concepts are explored:
- Attestations: Users signalling to their social graph that they believe something to be true by publishing Attestations. These social proofs act as a decentralised verification system that leverages your web-of-trust.
- Proof of Place: An oracle-based system where physical letters are sent to real-world locations, confirming the corresponding digital ownership via cryptographic proofs. This binds physical locations in meatspace with their digital representations in the Nostrverse.
- Check-ins: Foursquare-style check-ins that can be verified using attestations from place owners, ensuring authenticity. This approach uses web-of-trust to validate check-ins and location ownership over time.
The goal is to leverage cryptographic ownership where necessary while preserving the open, collaborative nature of public data systems.
Open Data in a public commons has a place and should not be thrown out with the Web 2.0 bathwater.
Cognitive Dissonance
Ever since discovering Nostr in August of 2022 I've been grappling with how BTC Map - a project that helps bitcoiners find places to spend sats - should most appropriately use this new protocol.
I am assuming, dear reader, that you are somewhat familiar with Nostr - a relatively new protocol for decentralised identity and communication. If you don’t know your nsec from your npub, please take some time to read these excellent posts: Nostr is Identity for the Internet and The Power of Nostr by @max and @lyn, respectively. Nostr is so much more than a short-form social media replacement.
The social features (check-ins, reviews, etc.) that Nostr unlocks for BTC Map are clear and exciting - all your silos are indeed broken - however, something fundamental has been bothering me for a while and I think it comes down to data ownership.
For those unfamiliar, BTC Map uses OpenStreetMap (OSM) as its main geographic database. OSM is centred on the concept of a commons of objectively verifiable data that is maintained by a global community of volunteer editors; a Wikipedia for maps. There is no data ownership; the data is free (as in freedom) and anyone can edit anything. It is the data equivalent of FOSS (Free and Open Source Software) - FOSD if you will, but more commonly referred to as Open Data.
In contrast, Notes and Other Stuff on Nostr (Places in this cartographic context) are explicitly owned by the controller of the private key. These notes are free to propagate, but they are owned.
How do we reconcile the decentralised nature of Nostr, where data is cryptographically owned by individuals, with the community-managed data commons of OpenStreetMap, where no one owns the data?
Self-sovereign Identity
Before I address this coexistence question, I want to talk a little about identity as it pertains to ownership. If something is to be owned, it has to be owned by someone or something - an identity.
All identities that are not self-sovereign are, by definition, leased to you by a 3rd party. You rent your Facebook identity from Meta in exchange for your data. You rent your web domain from your DNS provider in exchange for your money.
Taken to the extreme, you rent your passport from your Government in exchange for your compliance. You are you at the pleasure of others. Where Bitcoin separates money from the state; Nostr separates identity from the state.
Or, as @nvk said recently: "Don't build your house on someone else's land.".
https://i.nostr.build/xpcCSkDg3uVw0yku.png
While we’ve had the tools for self-sovereign digital identity for decades (think PGP keys or WebAuthN), we haven't had the necessary social use cases nor the corresponding social graph to elevate these identities to the mainstream. Nostr fixes this.
Nostr is PGP for the masses and will take cryptographic identities mainstream.
Full NOSTARD?
Returning to the coexistence question: the data on OpenStreetMap isn’t directly owned by anyone, even though the physical entities the data represents might be privately owned. OSM is a data commons.
We can objectively agree on the location of a tree or a fire hydrant without needing permission to observe and record it. Sure, you could place a tree ‘on Nostr’, but why should you? Just because something can be ‘on Nostr’ doesn’t mean it should be.
https://i.nostr.build/s3So2JVAqoY4E1dI.png
There might be a dystopian future where we can't agree on what a tree is nor where it's located, but I hope we never get there. It's at this point we'll need a Wikifreedia variant of OpenStreetMap.
While integrating Nostr identities into OpenStreetMap would be valuable, the current OSM infrastructure, tools, and community already provide substantial benefits in managing this data commons without needing to go NOSTR-native - there's no need to go Full NOSTARD. H/T to @princeySOV for the original meme.
https://i.nostr.build/ot9jtM5cZtDHNKWc.png
So, how do we appropriately blend cryptographically owned data with the commons?
If a location is owned in meatspace and it's useful to signal that ownership, it should also be owned in cyberspace. Our efforts should therefore focus on entities like businesses, while allowing the commons to manage public data for as long as it can successfully mitigate the tragedy of the commons.
The remainder of this article explores how we can:
- Verify ownership of a physical place in the real world;
- Link that ownership to the corresponding digital place in cyberspace.
As a side note, I don't see private key custodianship - or, even worse, permissioned use of Places signed by another identity's key - as any more viable than the rented identities of Web 2.0.
And as we all know, the Second Law of Infodynamics (no citation!) states that:
"The total amount of sensitive information leaked will always increase over time."
This especially holds true if that data is centralised.
Not your keys, not your notes. Not your keys, not your identity.
Places and Web-of-Trust
@Arkinox has been leading the charge on the Places NIP, introducing Nostr notes (kind 37515) that represent physical locations. The draft is well-crafted, with bonus points for linking back to OSM (and other location repositories) via NIP-73 - External Content IDs (championed by @oscar of @fountain).
However, as Nostr is permissionless, authenticity poses a challenge. Just because someone claims to own a physical location on the Internet doesn’t necessarily mean they have ownership or control of that location in the real world.
Ultimately, this problem can only be solved in a decentralised way by using Web-of-Trust - using your social graph and the perspectives of trusted peers to inform your own perspective. In the context of Places, this requires your network to form a view on which digital identity (public key / npub) is truly the owner of a physical place like your local coffee shop.
This requires users to:
- Verify the owner of a Place in cyberspace is the owner of a place in meatspace.
- Signal this verification to their social graph.
Let's look at the latter idea first with the concept of Attestations ...
Attestations
A way to signal to your social graph that you believe something to be true (or false for that matter) would be by publishing an Attestation note. An Attestation note would signify to your social graph that you think something is either true or false.
Imagine you're a regular at a local coffee shop. You publish an Attestation that says the shop is real and the owner behind the Nostr public key is who they claim to be. Your friends trust you, so they start trusting the shop's digital identity too.
However, attestations applied to Places are just a single use case. The attestation concept could be more widely applied across Nostr in a variety of ways (key rotation, identity linking, etc).
Here is a recent example from @lyn that would carry more signal if it were an Attestation:
https://i.nostr.build/lZAXOEwvRIghgFY4.png
Parallels can be drawn between Attestations and transaction confirmations on the Bitcoin timechain; however, their importance to you would be weighted by clients and/or Data Vending Machines in accordance with:
- Your social graph;
- The type or subject of the content being attested and by whom;
- Your personal preferences.
They could also have a validity duration to be temporally bound, which would be particularly useful in the case of Places.
NIP-25 (Reactions) do allow for users to up/downvote notes with optional content (e.g., emojis) and could work for Attestations, but I think we need something less ambiguous and more definitive.
‘This is true’ resonates more strongly than ‘I like this.’.
https://i.nostr.build/s8NIG2kXzUCLcoax.jpg
There are similar concepts in the Web 3 / Web 5 world such as Verified Credentials by tdb. However, Nostr is the Web 3 now and so wen Attestation NIP?
https://i.nostr.build/Cb047NWyHdJ7h5Ka.jpg
That said, I have seen @utxo has been exploring ‘smart contracts’ on nostr and Attestations may just be a relatively ‘dumb’ subset of the wider concept Nostr-native scripting combined with web-of-trust.
Proof of Place
Attestations handle the signalling of your truth, but what about the initial verification itself?
We already covered how this ultimately has to be derived from your social graph, but what if there was a way to help bootstrap this web-of-trust through the use of oracles? For those unfamiliar with oracles in the digital realm, they are simply trusted purveyors of truth.
Introducing Proof of Place, an out–of-band process where an oracle (such as BTC Map) would mail - yes physically mail- a shared secret to the address of the location being claimed in cyberspace. This shared secret would be locked to the public key (npub) making the claim, which, if unlocked, would prove that the associated private key (nsec) has physical access to the location in meatspace.
One way of doing this would be to mint a 1 sat cashu ecash token locked to the npub of the claimant and mail it to them. If they are able to redeem the token then they have cryptographically proven that they have physical access to the location.
Proof of Place is really nothing more than a weighted Attestation. In a web-of-trust Nostrverse, an oracle is simply a npub (say BTC Map) that you weigh heavily for its opinion on a given topic (say Places).
In the Bitcoin world, Proof of Work anchors digital scarcity in cyberspace to physical scarcity (energy and time) in meatspace and as @Gigi says in PoW is Essential:
"A failure to understand Proof of Work, is a failure to understand Bitcoin."
In the Nostrverse, Proof of Place helps bridge the digital and physical worlds.
@Gigi also observes in Memes vs The World that:
"In Bitcoin, the map is the territory. We can infer everything we care about by looking at the map alone."
https://i.nostr.build/dOnpxfI4u7EL2v4e.png
This isn’t true for Nostr.
In the Nostrverse, the map IS NOT the territory. However, Proof of Place enables us to send cryptographic drones down into the physical territory to help us interpret our digital maps. 🤯
Check-ins
Although not a draft NIP yet, @Arkinox has also been exploring the familiar concept of Foursquare-style Check-ins on Nostr (with kind 13811 notes).
For the uninitiated, Check-ins are simply notes that signal the publisher is at a given location. These locations could be Places (in the Nostr sense) or any other given digital representation of a location for that matter (such as OSM elements) if NIP-73 - External Content IDs are used.
Of course, not everyone will be a Check-in enjoyooor as the concept will not sit well with some people’s threat models and OpSec practices.
Bringing Check-ins to Nostr is possible (as @sebastix capably shows here), but they suffer the same authenticity issues as Places. Just because I say I'm at a given location doesn't mean that I am.
Back in the Web 2.0 days, Foursquare mitigated this by relying on the GPS position of the phone running their app, but this is of course spoofable.
How should we approach Check-in verifiability in the Nostrverse? Well, just like with Places, we can use Attestations and WoT. In the context of Check-ins, an Attestation from the identity (npub) of the Place being checked-in to would be a particularly strong signal. An NFC device could be placed in a coffee shop and attest to check-ins without requiring the owner to manually intervene - I’m sure @blackcoffee and @Ben Arc could hack something together over a weekend!
Check-ins could also be used as a signal for bonafide Place ownership over time.
Summary: Trust Your Bros
So, to recap, we have:
Places: Digital representations of physical locations on Nostr.
Check-ins: Users signalling their presence at a location.
Attestations: Verifiable social proofs used to confirm ownership or the truth of a claim.
You can visualise how these three concepts combine in the diagram below:
https://i.nostr.build/Uv2Jhx5BBfA51y0K.jpg
And, as always, top right trumps bottom left! We have:
Level 0 - Trust Me Bro: Anyone can check-in anywhere. The Place might not exist or might be impersonating the real place in meatspace. The person behind the npub may not have even been there at all.
Level 1 - Definitely Maybe Somewhere: This category covers the middle-ground of ‘Maybe at a Place’ and ‘Definitely Somewhere’. In these examples, you are either self-certifying that you have checked-in at an Attested Place or you are having others attest that you have checked-in at a Place that might not even exist IRL.
Level 2 - Trust Your Bros: An Attested Check-in at an Attested Place. Your individual level of trust would be a function of the number of Attestations and how you weigh them within your own social graph.
https://i.nostr.build/HtLAiJH1uQSTmdxf.jpg
Perhaps the gold standard (or should that be the Bitcoin standard?) would be a Check-in attested by the owner of the Place, which in itself was attested by BTC Map?
Or perhaps not. Ultimately, it’s the users responsibility to determine what they trust by forming their own perspective within the Nostrverse powered by web-of-trust algorithms they control. ‘Trust Me Bro’ or ‘Trust Your Bros’ - you decide.
As we navigate the frontier of cryptographic ownership and decentralised data, it’s up to us to find the balance between preserving the Open Data commons and embracing self-sovereign digital identities.
Thanks
With thanks to Arkinox, Avi, Ben Gunn, Kieran, Blackcoffee, Sebastix, Tomek, Calle, Short Fiat, Ben Weeks and Bitcoms for helping shape my thoughts and refine content, whether you know it or not!
-
@ 6ad3e2a3:c90b7740
2024-09-11 15:16:53
I’ve occasionally been called cynical because some of the sentiments I express strike people as negative. But cynical, to me, does not strictly mean negative. It means something more along the lines of “faithless” — as in lacking the basic faith humans thrive when believing what they take to be true, rather than expedient, and doing what they think is right rather than narrowly advantageous.
In other words, my primary negative sentiment — that the cynical utilitarian ethos among our educated classes has caused and is likely to cause catastrophic outcomes — stems from a sort of disappointed idealism, not cynicism.
On human nature itself I am anything but cynical. I am convinced the strongest, long-term incentives are always to believe what is true, no matter the cost, and to do what is right. And by “right,” I don’t mean do-gooding bullshit, but things like taking care of one’s health, immediate family and personal responsibilities while pursuing the things one finds most compelling and important.
That aside, I want to touch on two real-world examples of what I take to be actual cynicism. The first is the tendency to invoke principles only when they suit one’s agenda or desired outcome, but not to apply them when they do not. This kind of hypocrisy implies principles are just tools you invoke to gain emotional support for your side and that anyone actually applying them evenhandedly is a naive simpleton who doesn’t know how the game is played.
Twitter threads don’t show up on substack anymore, but I’d encourage you to read this one with respect to objecting to election outcomes. I could have used many others, but this one (probably not even most egregious) illustrates how empty words like “democracy” or “election integrity” are when thrown around by devoted partisans. They don’t actually believe in democracy, only in using the word to evoke the desired emotional response. People who wanted to coerce people to take a Pfizer shot don’t believe in “bodily autonomy.” It’s similarly just a phrase that’s invoked to achieve an end.
The other flavor of cynicism I’ve noticed is less about hypocrisy and more about nihilism:
 I’d encourage people to read the entire thread, but if you’re not on Twitter, it’s essentially about whether money (and apparently anything else) has essential qualities, or whether it is whatever peoples’ narratives tell them it is.
I’d encourage people to read the entire thread, but if you’re not on Twitter, it’s essentially about whether money (and apparently anything else) has essential qualities, or whether it is whatever peoples’ narratives tell them it is.In other words, is money whatever your grocer takes for the groceries, or do particular forms of money have qualities wherein they are more likely to be accepted over the long haul? The argument is yes, gold, for example had qualities that made it a better money (scarcity, durability, e.g.) than say seashells which are reasonably durable but not scarce. You could sell the story of seashells as a money (and some societies not close to the sea used them as such), but ultimately such a society would be vulnerable to massive inflation should one of its inhabitants ever stroll along a shore.
The thread morphed into whether everything is just narrative, or there is an underlying reality to which a narrative must correspond in order for it to be useful and true.
The notion that anything could be money if attached to the right story, or any music is good if it’s marketed properly is deeply cynical. I am not arguing people can’t be convinced to buy bad records — clearly they can — but that no matter how much you market it, it will not stand the test of time unless it is in fact good.
In order to sell something that does not add value, meaning or utility to someone’s life, something you suspect they are likely to regret buying in short order, it’s awfully useful to convince yourself that nothing has inherent meaning or value, that “storytelling is all that matters.”
I am not against marketing per se, and effective storytelling might in fact point someone in the right direction — a good story can help someone discover a truth. But that storytelling is everything, and by implication the extent to which a story has correlates in reality nothing, is the ethos of scammers, the refuge of nihilists who left someone else holding the bag and prefer not to think about it.
-
@ 866e0139:6a9334e5
2025-04-05 11:00:25
Autor: CJ Hopkins. Dieser Beitrag wurde mit dem Pareto-Client geschrieben. Sie finden alle Texte der Friedenstaube und weitere Texte zum Thema Frieden hier.**
Dieser Beitrag erschien zuerst auf dem Substack-Blog des Autors.
Er soll andauern, was er auch tut. Genau wie der nie endende Krieg in Orwells 1984 wird er vom Imperium gegen seine eigenen Untertanen geführt, aber nicht nur, um die Struktur der Gesellschaft intakt zu halten, sondern in unserem Fall auch, um die Gesellschaft in eine neo-totalitäre global-kapitalistische Dystopie zu verwandeln.
Bist du nicht vertraut mit dem Krieg gegen was auch immer?
Nun ja, okay, du erinnerst dich an den Krieg gegen den Terror.
Du erinnerst dich daran, als die „Freiheit und Demokratie“ von „den Terroristen“ angegriffen wurden und wir keine andere Wahl hatten, als uns unserer demokratischen Rechte und Prinzipien zu entledigen, einen nationalen „Notstand“ auszurufen, die verfassungsmäßigen Rechte der Menschen auszusetzen, einen Angriffskrieg gegen ein Land im Nahen Osten anzuzetteln, das für uns keinerlei Bedrohung darstellte, und unsere Straßen, Bahnhöfe, Flughäfen und alle anderen Orte mit schwer bewaffneten Soldaten zu füllen, denn sonst hätten „die Terroristen gewonnen“. Du erinnerst dich, als wir ein Offshore-Gulag bauten, um verdächtige Terroristen auf unbestimmte Zeit wegzusperren, die wir zuvor zu CIA-Geheimgefängnissen verschleppt hatten, wo wir sie gefoltert und gedemütigt haben, richtig?
Natürlich erinnerst du dich. Wer könnte das vergessen?
DIE FRIEDENSTAUBE FLIEGT AUCH IN IHR POSTFACH!
Hier können Sie die Friedenstaube abonnieren und bekommen die Artikel zugesandt, vorerst für alle kostenfrei, wir starten gänzlich ohne Paywall. (Die Bezahlabos fangen erst zu laufen an, wenn ein Monetarisierungskonzept für die Inhalte steht). Sie wollen der Genossenschaft beitreten oder uns unterstützen? Mehr Infos hier oder am Ende des Textes.
Erinnerst du dich, als die National Security Agency keine andere Wahl hatte, als ein geheimes „Terroristen-Überwachungsprogramm“ einzurichten, um Amerikaner auszuspionieren, oder sonst „hätten die Terroristen gewonnen“? Oder wie wäre es mit den „Anti-Terror“-Unterleibsuntersuchungen der TSA, der Behörde für Transportsicherheit, die nach über zwanzig Jahren immer noch in Kraft sind?
Und was ist mit dem Krieg gegen den Populismus? An den erinnerst du dich vielleicht nicht so gut.
Ich erinnere mich, denn ich habe zwei Bücher dazu veröffentlicht. Er begann im Sommer 2016, als das Imperium erkannte, dass „rechte Populisten“ die „Freiheit und Demokratie“ in Europa bedrohten und Trump in den USA auf dem Vormarsch war. Also wurde ein weiterer „Notstand“ ausgerufen – diesmal von der Gemeinschaft der Geheimdienste, den Medien, der akademischen Welt und der Kulturindustrie. Ja, genau, es war wieder einmal an der Zeit, unsere demokratischen Prinzipien hintanzustellen, „Hassrede“ in sozialen Medien zu zensieren, die Massen mit lächerlicher offizieller Propaganda über „Russiagate,“ „Hitlergate“ und so weiter zu bombardieren – sonst hätten „die Rechtspopulisten gewonnen.“
Der Krieg gegen den Populismus gipfelte in der Einführung des Neuen Normalen Reichs.

Im Frühjahr 2020 rief das Imperium einen globalen „gesundheitlichen Ausnahmezustand“ aus, als Reaktion auf ein Virus mit einer Überlebensrate von etwa 99,8 Prozent. Das Imperium hatte keine andere Wahl, als ganze Gesellschaften abzuriegeln, jeden dazu zu zwingen, in der Öffentlichkeit medizinisch aussehende Masken zu tragen, die Öffentlichkeit mit Propaganda und Lügen zu bombardieren, die Menschen dazu zu nötigen, sich einer Reihe experimenteller mRNA-„Impfungen“ zu unterziehen, Proteste gegen ihre Dekrete zu verbieten und systematisch diejenigen zu zensieren und zu verfolgen, die es wagten, ihre erfundenen „Fakten“ in Frage zu stellen oder ihr totalitäres Programm zu kritisieren.
Das Imperium hatte keine andere Wahl, als das alles zu tun, denn sonst hätten „die Covid-Leugner, die Impfgegner, die Verschwörungstheoretiker und all die anderen Extremisten gewonnen.“
Ich bin mir ziemlich sicher, dass du dich an all das erinnerst.
Und jetzt … nun, hier sind wir. Ja, du hast es erraten – es ist wieder einmal an der Zeit, kräftig auf die US-Verfassung und die Meinungsfreiheit zu scheißen, Menschen in irgendein salvadorianisches Höllenloch abzuschieben, das wir angemietet haben, weil ein Polizist ihre Tattoos nicht mochte, Universitätsstudenten wegen ihrer Anti-Israel-Proteste festzunehmen und zu verschleppen und natürlich die Massen mit Lügen und offizieller Propaganda zu bombardieren, denn … okay, alle zusammen jetzt: „sonst hätten die antisemitischen Terroristen und venezolanischen Banden gewonnen!“
Fängst du an, ein Muster zu erkennen? Ja? Willkommen beim Krieg gegen-was-auch-immer!
Wenn du die Zusammenhänge noch nicht ganz siehst, okay, lass es mich noch einmal ganz simpel erklären.
Das globale ideologische System, in dem wir alle leben, wird totalitär. (Dieses System ist der globale Kapitalismus, aber nenne es, wie du willst. Es ist mir scheißegal.) Es reißt die Simulation der Demokratie nieder, die es nicht mehr aufrechterhalten muss. Der Kalte Krieg ist vorbei. Der Kommunismus ist tot. Der globale Kapitalismus hat keine externen Feinde mehr. Also muss er die Massen nicht mehr mit demokratischen Rechten und Freiheiten besänftigen. Deshalb entzieht er uns diese Rechte nach und nach und konditioniert uns darauf, ihren Verlust hinzunehmen.
Er tut dies, indem er eine Reihe von „Notständen“ inszeniert, jeder mit einer anderen „Bedrohung“ für die „Demokratie,“ die „Freiheit,“ „Amerika“ oder „den Planeten“ – oder was auch immer. Jeder mit seinen eigenen „Monstern,“ die eine so große Gefahr für die „Freiheit“ oder was auch immer darstellen, dass wir unsere verfassungsmäßigen Rechte aufgeben und die demokratischen Werte ad absurdum führen müssen, denn: sonst „würden die Monster gewinnen.“

Es tut dies, indem es sein Antlitz von „links“ nach „rechts,“ dann zurück nach „links“, und dann zurück nach „rechts,“ dann nach „links“ und so weiter neigt, weil es unsere Kooperation dafür benötigt. Nicht die Kooperation von uns allen auf einmal. Nur eine kooperative demografische Gruppe auf einmal.
Es ist dabei erfolgreich – also das System – indem es unsere Angst und unseren Hass instrumentalisiert. Dem System ist es völlig egal, ob wir uns als „links“ oder „rechts“ identifizieren, aber es braucht uns gespalten in „links“ und „rechts,“ damit es unsere Angst und unseren Hass aufeinander nähren kann … eine Regierung, ein „Notfall,“ ein „Krieg“ nach dem anderen.
Da hast du es. Das ist der Krieg gegen was auch immer. Noch simpler kann ich es nicht erklären.
Oh, und noch eine letzte Sache … wenn du einer meiner ehemaligen Fans bist, wie Rob, die über meine „Einsichten“ oder Loyalitäten oder was auch immer verwirrt sind … nun, der Text, den du gerade gelesen hast, sollte das für dich klären. Ich stehe auf keiner Seite. Überhaupt keiner. Aber ich habe ein paar grundlegende demokratische Prinzipien. Und die richten sich nicht danach, was gerade populär ist oder wer im Weißen Haus sitzt.
Die Sache ist die: Ich muss mich morgens im Spiegel anschauen können ohne dort einen Heuchler oder … du weißt schon, einen Feigling zu sehen.
(Aus dem Amerikanischen übersetzt von René Boyke).
CJ Hopkins ist ein US-amerikanischer Dramatiker, Romanautor und politischer Satiriker. Zu seinen Werken zählen die Stücke Horse Country, Screwmachine/Eyecandy und The Extremists. Er hat sich als profilierter Kritiker des Corona-Regimes profiliert und veröffentlicht regelmäßig auf seinem Substack-Blog.
Sein aktuelles Buch:
https://x.com/CJHopkins_Z23/status/1907795633689264530
Hier in einem aktuellen Gespräch:
https://www.youtube.com/watch?v=wF-G32P0leI
LASSEN SIE DER FRIEDENSTAUBE FLÜGEL WACHSEN!
Hier können Sie die Friedenstaube abonnieren und bekommen die Artikel zugesandt. (Vorerst alle, da wir den Mailversand testen, später ca. drei Mails pro Woche.)
Schon jetzt können Sie uns unterstützen:
- Für 50 CHF/EURO bekommen Sie ein Jahresabo der Friedenstaube.
- Für 120 CHF/EURO bekommen Sie ein Jahresabo und ein T-Shirt/Hoodie mit der Friedenstaube.
- Für 500 CHF/EURO werden Sie Förderer und bekommen ein lebenslanges Abo sowie ein T-Shirt/Hoodie mit der Friedenstaube.
- Ab 1000 CHF werden Sie Genossenschafter der Friedenstaube mit Stimmrecht (und bekommen lebenslanges Abo, T-Shirt/Hoodie).
Für Einzahlungen in CHF (Betreff: Friedenstaube):
Für Einzahlungen in Euro:
Milosz Matuschek
IBAN DE 53710520500000814137
BYLADEM1TST
Sparkasse Traunstein-Trostberg
Betreff: Friedenstaube
Wenn Sie auf anderem Wege beitragen wollen, schreiben Sie die Friedenstaube an: milosz@pareto.space
Sie sind noch nicht auf Nostr and wollen die volle Erfahrung machen (liken, kommentieren etc.)? Zappen können Sie den Autor auch ohne Nostr-Profil! Erstellen Sie sich einen Account auf Start. Weitere Onboarding-Leitfäden gibt es im Pareto-Wiki.
-
@ da18e986:3a0d9851
2025-04-04 20:25:50
I'm making this tutorial for myself, as I plan to write many wiki pages describing DVM kinds, as a resource for DVMDash.
Wiki pages on Nostr are written using AsciiDoc. If you don't know ascii doc, get an LLM (like https://duck.ai) to help you format into the right syntax.
Here's the test wiki page I'm going to write:
``` = Simple AsciiDoc Demo
This is a simple demonstration of AsciiDoc syntax for testing purposes.
== Features
AsciiDoc offers many formatting options that are easy to use.
- Easy to learn
- Supports rich text formatting
- Can include code snippets
- Works great for documentation
[source,json]
{ "name": "Test", "version": "1.0", "active": true }
```
We're going to use nak to publish it
First, install
nakif you haven't alreadygo install github.com/fiatjaf/nak@latestNote: if you don't use Go a lot, you may need to first install it and then add it to your path so the
nakcommand is recognized by the terminal```
this is how to add it to your path on mac if using zsh
echo 'export PATH=$PATH:$(go env GOPATH)/bin' >> ~/.zshrc ```
And here's how to sign and publish this event with nak.
First, if you want to use your own nostr sec key, you can set the env variable to it and nak will use that if no secret key is specified
```
replace with your full secret key
export NOSTR_SECRET_KEY="nsec1zcdn..." ```
Now to sign and publish the event:
Note: inner double quotes need to be escaped with a
\before them in order to keep the formatting correct, because we're doing this in the terminalnak event -k 30818 -d "dvm-wiki-page-test" -t 'title=dvm wiki page test' -c "= Simple AsciiDoc Demo\n\nThis is a simple demonstration of AsciiDoc syntax for testing purposes. \n\n== Features\n\nAsciiDoc offers many formatting options that are easy to use. \n\n* Easy to learn \n* Supports rich text formatting \n* Can include code snippets \n* Works great for documentation \n\n[source,json] \n---- \n{ \"name\": \"Test\", \"version\": \"1.0\", \"active\": true } \n----" wss://relay.primal.net wss://relay.damus.io wss://relay.wikifreedia.xyzYou've now published your first wiki page! If done correctly, it will show up on wikistr.com, like mine did here: https://wikistr.com/dvm-wiki-page-test*da18e9860040f3bf493876fc16b1a912ae5a6f6fa8d5159c3de2b8233a0d9851
and on wikifreedia.xyz https://wikifreedia.xyz/dvm-wiki-page-test/dustind@dtdannen.github.io
-
@ 90c656ff:9383fd4e
2025-05-04 17:48:58
The Bitcoin network was designed to be secure, decentralized, and resistant to censorship. However, as its usage grows, an important challenge arises: scalability. This term refers to the network's ability to manage an increasing number of transactions without affecting performance or security. This challenge has sparked the speed dilemma, which involves balancing transaction speed with the preservation of decentralization and security that the blockchain or timechain provides.
Scalability is the ability of a system to increase its performance to meet higher demands. In the case of Bitcoin, this means processing a greater number of transactions per second (TPS) without compromising the network's core principles.
Currently, the Bitcoin network processes about 7 transactions per second, a number considered low compared to traditional systems, such as credit card networks, which can process thousands of transactions per second. This limit is directly due to the fixed block size (1 MB) and the average 10-minute interval for creating a new block in the blockchain or timechain.
The speed dilemma arises from the need to balance three essential elements: decentralization, security, and speed.
The Timechain/"Blockchain" Trilemma:
01 - Decentralization: The Bitcoin network is composed of thousands of independent nodes that verify and validate transactions. Increasing the block size or making them faster could raise computational requirements, making it harder for smaller nodes to participate and affecting decentralization. 02 - Security: Security comes from the mining process and block validation. Increasing transaction speed could compromise security, as it would reduce the time needed to verify each block, making the network more vulnerable to attacks. 03 - Speed: The need to confirm transactions quickly is crucial for Bitcoin to be used as a payment method in everyday life. However, prioritizing speed could affect both security and decentralization.
This dilemma requires balanced solutions to expand the network without sacrificing its core features.
Solutions to the Scalability Problem
Several solutions have been suggested to address the scalability and speed challenges in the Bitcoin network.
- On-Chain Optimization
01 - Segregated Witness (SegWit): Implemented in 2017, SegWit separates signature data from transactions, allowing more efficient use of space in blocks and increasing capacity without changing the block size. 02 - Increasing Block Size: Some proposals have suggested increasing the block size to allow more transactions per block. However, this could make the system more centralized as it would require greater computational power.
- Off-Chain Solutions
01 - Lightning Network: A second-layer solution that enables fast and low-cost transactions off the main blockchain or timechain. These transactions are later settled on the main network, maintaining security and decentralization. 02 - Payment Channels: Allow direct transactions between two users without the need to record every action on the network, reducing congestion. 03 - Sidechains: Proposals that create parallel networks connected to the main blockchain or timechain, providing more flexibility and processing capacity.
While these solutions bring significant improvements, they also present issues. For example, the Lightning Network depends on payment channels that require initial liquidity, limiting its widespread adoption. Increasing block size could make the system more susceptible to centralization, impacting network security.
Additionally, second-layer solutions may require extra trust between participants, which could weaken the decentralization and resistance to censorship principles that Bitcoin advocates.
Another important point is the need for large-scale adoption. Even with technological advancements, solutions will only be effective if they are widely used and accepted by users and developers.
In summary, scalability and the speed dilemma represent one of the greatest technical challenges for the Bitcoin network. While security and decentralization are essential to maintaining the system's original principles, the need for fast and efficient transactions makes scalability an urgent issue.
Solutions like SegWit and the Lightning Network have shown promising progress, but still face technical and adoption barriers. The balance between speed, security, and decentralization remains a central goal for Bitcoin’s future.
Thus, the continuous pursuit of innovation and improvement is essential for Bitcoin to maintain its relevance as a reliable and efficient network, capable of supporting global growth and adoption without compromising its core values.
Thank you very much for reading this far. I hope everything is well with you, and sending a big hug from your favorite Bitcoiner maximalist from Madeira. Long live freedom!
-
@ ee11a5df:b76c4e49
2024-09-11 08:16:37
Bye-Bye Reply Guy
There is a camp of nostr developers that believe spam filtering needs to be done by relays. Or at the very least by DVMs. I concur. In this way, once you configure what you want to see, it applies to all nostr clients.
But we are not there yet.
In the mean time we have ReplyGuy, and gossip needed some changes to deal with it.
Strategies in Short
- WEB OF TRUST: Only accept events from people you follow, or people they follow - this avoids new people entirely until somebody else that you follow friends them first, which is too restrictive for some people.
- TRUSTED RELAYS: Allow every post from relays that you trust to do good spam filtering.
- REJECT FRESH PUBKEYS: Only accept events from people you have seen before - this allows you to find new people, but you will miss their very first post (their second post must count as someone you have seen before, even if you discarded the first post)
- PATTERN MATCHING: Scan for known spam phrases and words and block those events, either on content or metadata or both or more.
- TIE-IN TO EXTERNAL SYSTEMS: Require a valid NIP-05, or other nostr event binding their identity to some external identity
- PROOF OF WORK: Require a minimum proof-of-work
All of these strategies are useful, but they have to be combined properly.
filter.rhai
Gossip loads a file called "filter.rhai" in your gossip directory if it exists. It must be a Rhai language script that meets certain requirements (see the example in the gossip source code directory). Then it applies it to filter spam.
This spam filtering code is being updated currently. It is not even on unstable yet, but it will be there probably tomorrow sometime. Then to master. Eventually to a release.
Here is an example using all of the techniques listed above:
```rhai // This is a sample spam filtering script for the gossip nostr // client. The language is called Rhai, details are at: // https://rhai.rs/book/ // // For gossip to find your spam filtering script, put it in // your gossip profile directory. See // https://docs.rs/dirs/latest/dirs/fn.data_dir.html // to find the base directory. A subdirectory "gossip" is your // gossip data directory which for most people is their profile // directory too. (Note: if you use a GOSSIP_PROFILE, you'll // need to put it one directory deeper into that profile // directory). // // This filter is used to filter out and refuse to process // incoming events as they flow in from relays, and also to // filter which events get/ displayed in certain circumstances. // It is only run on feed-displayable event kinds, and only by // authors you are not following. In case of error, nothing is // filtered. // // You must define a function called 'filter' which returns one // of these constant values: // DENY (the event is filtered out) // ALLOW (the event is allowed through) // MUTE (the event is filtered out, and the author is // automatically muted) // // Your script will be provided the following global variables: // 'caller' - a string that is one of "Process", // "Thread", "Inbox" or "Global" indicating // which part of the code is running your // script // 'content' - the event content as a string // 'id' - the event ID, as a hex string // 'kind' - the event kind as an integer // 'muted' - if the author is in your mute list // 'name' - if we have it, the name of the author // (or your petname), else an empty string // 'nip05valid' - whether nip05 is valid for the author, // as a boolean // 'pow' - the Proof of Work on the event // 'pubkey' - the event author public key, as a hex // string // 'seconds_known' - the number of seconds that the author // of the event has been known to gossip // 'spamsafe' - true only if the event came in from a // relay marked as SpamSafe during Process // (even if the global setting for SpamSafe // is off)
fn filter() {
// Show spam on global // (global events are ephemeral; these won't grow the // database) if caller=="Global" { return ALLOW; } // Block ReplyGuy if name.contains("ReplyGuy") || name.contains("ReplyGal") { return DENY; } // Block known DM spam // (giftwraps are unwrapped before the content is passed to // this script) if content.to_lower().contains( "Mr. Gift and Mrs. Wrap under the tree, KISSING!" ) { return DENY; } // Reject events from new pubkeys, unless they have a high // PoW or we somehow already have a nip05valid for them // // If this turns out to be a legit person, we will start // hearing their events 2 seconds from now, so we will // only miss their very first event. if seconds_known <= 2 && pow < 25 && !nip05valid { return DENY; } // Mute offensive people if content.to_lower().contains(" kike") || content.to_lower().contains("kike ") || content.to_lower().contains(" nigger") || content.to_lower().contains("nigger ") { return MUTE; } // Reject events from muted people // // Gossip already does this internally, and since we are // not Process, this is rather redundant. But this works // as an example. if muted { return DENY; } // Accept if the PoW is large enough if pow >= 25 { return ALLOW; } // Accept if their NIP-05 is valid if nip05valid { return ALLOW; } // Accept if the event came through a spamsafe relay if spamsafe { return ALLOW; } // Reject the rest DENY} ```
-
@ a5ee4475:2ca75401
2025-05-04 17:22:36
clients #list #descentralismo #english #article #finalversion
*These clients are generally applications on the Nostr network that allow you to use the same account, regardless of the app used, keeping your messages and profile intact.
**However, you may need to meet certain requirements regarding access and account NIP for some clients, so that you can access them securely and use their features correctly.
CLIENTS
Twitter like
- Nostrmo - [source] 🌐🤖🍎💻(🐧🪟🍎)
- Coracle - Super App [source] 🌐
- Amethyst - Super App with note edit, delete and other stuff with Tor [source] 🤖
- Primal - Social and wallet [source] 🌐🤖🍎
- Iris - [source] 🌐🤖🍎
- Current - [source] 🤖🍎
- FreeFrom 🤖🍎
- Openvibe - Nostr and others (new Plebstr) [source] 🤖🍎
- Snort 🌐(🤖[early access]) [source]
- Damus 🍎 [source]
- Nos 🍎 [source]
- Nostur 🍎 [source]
- NostrBand 🌐 [info] [source]
- Yana 🤖🍎🌐💻(🐧) [source]
- Nostribe [on development] 🌐 [source]
- Lume 💻(🐧🪟🍎) [info] [source]
- Gossip - [source] 💻(🐧🪟🍎)
- Camelus [early access] 🤖 [source]
Communities
- noStrudel - Gamified Experience [info] 🌐
- Nostr Kiwi [creator] 🌐
- Satellite [info] 🌐
- Flotilla - [source] 🌐🐧
- Chachi - [source] 🌐
- Futr - Coded in haskell [source] 🐧 (others soon)
- Soapbox - Comunnity server [info] [source] 🌐
- Ditto - Soapbox comunnity server 🌐 [source] 🌐
- Cobrafuma - Nostr brazilian community on Ditto [info] 🌐
- Zapddit - Reddit like [source] 🌐
- Voyage (Reddit like) [on development] 🤖
Wiki
Search
- Advanced nostr search - Advanced note search by isolated terms related to a npub profile [source] 🌐
- Nos Today - Global note search by isolated terms [info] [source] 🌐
- Nostr Search Engine - API for Nostr clients [source]
Website
App Store
ZapStore - Permitionless App Store [source]
Audio and Video Transmission
- Nostr Nests - Audio Chats 🌐 [info]
- Fountain - Podcast 🤖🍎 [info]
- ZapStream - Live streaming 🌐 [info]
- Corny Chat - Audio Chat 🌐 [info]
Video Streaming
Music
- Tidal - Music Streaming [source] [about] [info] 🤖🍎🌐
- Wavlake - Music Streaming [source] 🌐(🤖🍎 [early access])
- Tunestr - Musical Events [source] [about] 🌐
- Stemstr - Musical Colab (paid to post) [source] [about] 🌐
Images
- Pinstr - Pinterest like [source] 🌐
- Slidestr - DeviantArt like [source] 🌐
- Memestr - ifunny like [source] 🌐
Download and Upload
Documents, graphics and tables
- Mindstr - Mind maps [source] 🌐
- Docstr - Share Docs [info] [source] 🌐
- Formstr - Share Forms [info] 🌐
- Sheetstr - Share Spreadsheets [source] 🌐
- Slide Maker - Share slides 🌐 (advice: https://zaplinks.lol/ and https://zaplinks.lol/slides/ sites are down)
Health
- Sobrkey - Sobriety and mental health [source] 🌐
- NosFabrica - Finding ways for your health data 🌐
- LazerEyes - Eye prescription by DM [source] 🌐
Forum
- OddBean - Hacker News like [info] [source] 🌐
- LowEnt - Forum [info] 🌐
- Swarmstr - Q&A / FAQ [info] 🌐
- Staker News - Hacker News like 🌐 [info]
Direct Messenges (DM)
- 0xchat 🤖🍎 [source]
- Nostr Chat 🌐🍎 [source]
- Blowater 🌐 [source]
- Anigma (new nostrgram) - Telegram based [on development] [source]
- Keychat - Signal based [🤖🍎 on development] [source]
Reading
- Highlighter - Insights with a highlighted read 🌐 [info]
- Zephyr - Calming to Read 🌐 [info]
- Flycat - Clean and Healthy Feed 🌐 [info]
- Nosta - Check Profiles [on development] 🌐 [info]
- Alexandria - e-Reader and Nostr Knowledge Base (NKB) [source]
Writing
Lists
- Following - Users list [source] 🌐
- Listr - Lists [source] 🌐
- Nostr potatoes - Movies List source 💻(numpy)
Market and Jobs
- Shopstr - Buy and Sell [source] 🌐
- Nostr Market - Buy and Sell 🌐
- Plebeian Market - Buy and Sell [source] 🌐
- Ostrich Work - Jobs [source] 🌐
- Nostrocket - Jobs [source] 🌐
Data Vending Machines - DVM (NIP90)
(Data-processing tools)
AI
Games
- Chesstr - Chess 🌐 [source]
- Jestr - Chess [source] 🌐
- Snakestr - Snake game [source] 🌐
- DEG Mods - Decentralized Game Mods [info] [source] 🌐
Customization
Like other Services
- Olas - Instagram like [source] 🤖🍎🌐
- Nostree - Linktree like 🌐
- Rabbit - TweetDeck like [info] 🌐
- Zaplinks - Nostr links 🌐
- Omeglestr - Omegle-like Random Chats [source] 🌐
General Uses
- Njump - HTML text gateway source 🌐
- Filestr - HTML midia gateway [source] 🌐
- W3 - Nostr URL shortener [source] 🌐
- Playground - Test Nostr filters [source] 🌐
- Spring - Browser 🌐
Places
- Wherostr - Travel and show where you are
- Arc Map (Mapstr) - Bitcoin Map [info]
Driver and Delivery
- RoadRunner - Uber like [on development] ⏱️
- Arcade City - Uber like [on development] ⏱️ [info]
- Nostrlivery - iFood like [on development] ⏱️
OTHER STUFF
Lightning Wallets (zap)
- Alby - Native and extension [info] 🌐
- ZBD - Gaming and Social [info] 🤖🍎
- Wallet of Satoshi [info] 🤖🍎
- Minibits - Cashu mobile wallet [info] 🤖
- Blink - Opensource custodial wallet (KYC over 1000 usd) [source] 🤖🍎
- LNbits - App and extesion [source] 🤖🍎💻
- Zeus - [info] [source] 🤖🍎
Exchange
Media Server (Upload Links)
audio, image and video
- Nostr Build - [source] 🌐
- Nostr Check - [info] [source] 🌐
- NostPic - [source] 🌐
- Sovbit 🌐
- Voidcat - [source] 🌐
Without Nip: - Pomf - Upload larger videos [source] - Catbox - [source] - x0 - [source]
Donation and payments
- Zapper - Easy Zaps [source] 🌐
- Autozap [source] 🌐
- Zapmeacoffee 🌐
- Nostr Zap 💻(numpy)
- Creatr - Creators subscription 🌐
- Geyzer - Crowdfunding [info] [source] 🌐
- Heya! - Crowdfunding [source]
Security
- Secret Border - Generate offline keys 💻(java)
- Umbrel - Your private relay [source] 🌐
Extensions
- Nos2x - Account access keys 🌐
- Nsec.app 🌐 [info]
- Lume - [info] [source] 🐧🪟🍎
- Satcom - Share files to discuss - [info] 🌐
- KeysBand - Multi-key signing [source] 🌐
Code
- Nostrify - Share Nostr Frameworks 🌐
- Git Workshop (github like) [experimental] 🌐
- Gitstr (github like) [on development] ⏱️
- Osty [on development] [info] 🌐
- Python Nostr - Python Library for Nostr
Relay Check and Cloud
- Nostr Watch - See your relay speed 🌐
- NosDrive - Nostr Relay that saves to Google Drive
Bidges and Getways
- Matrixtr Bridge - Between Matrix & Nostr
- Mostr - Between Nostr & Fediverse
- Nostrss - RSS to Nostr
- Rsslay - Optimized RSS to Nostr [source]
- Atomstr - RSS/Atom to Nostr [source]
NOT RELATED TO NOSTR
Android Keyboards
Personal notes and texts
Front-ends
- Nitter - Twitter / X without your data [source]
- NewPipe - Youtube, Peertube and others, without account & your data [source] 🤖
- Piped - Youtube web without you data [source] 🌐
Other Services
- Brave - Browser [source]
- DuckDuckGo - Search [source]
- LLMA - Meta - Meta open source AI [source]
- DuckDuckGo AI Chat - Famous AIs without Login [source]
- Proton Mail - Mail [source]
Other open source index: Degoogled Apps
Some other Nostr index on:
-
@ c7aa97dc:0d12c810
2025-05-04 17:06:47
COLDCARDS’s new Co-Sign feature lets you use a multisig (2 of N) wallet where the second key (policy key) lives inside the same COLDCARD and signs only when a transaction meets the rules you set-for example:
- Maximum amount per send (e.g. 500k Sats)
- Wait time between sends, (e.g 144 blocks = 1 day)
- Only send to approved addresses,
- Only send after you provide a 2FA code
If a payment follows the rules, COLDCARD automatically signs the transaction with 2 keys which makes it feel like a single-sig wallet.
Break a rule and the device only signs with 1 key, so nothing moves unless you sign the transaction with a separate off-site recovery key.
It’s the convenience of singlesig with the guard-rails of multisig.
Use Cases Unlocked
Below you will find an overview of usecases unlocked by this security enhancing feature for everyday bitcoiners, families, and small businesses.

1. Travel Lock-Down Mode
Before you leave, set the wait-time to match the duration of your trip—say 14 days—and cap each spend at 50k sats. If someone finds the COLDCARD while you’re away, they can take only one 50k-sat nibble and then must wait the full two weeks—long after you’re back—to try again. When you notice your device is gone you can quickly restore your wallet with your backup seeds (not in your house of course) and move all the funds to a new wallet.
2. Shared-Safety Wallet for Parents or Friends
Help your parents or friends setup a COLDCARD with Co-Sign, cap each spend at 500 000 sats and enforce a 7-day gap between transactions. Everyday spending sails through; anything larger waits for your co-signature from your key. A thief can’t steal more than the capped amount per week, and your parents retains full sovereignty—if you disappear, they still hold two backup seeds and can either withdraw slowly under the limits or import those seeds into another signer and move everything at once.
3. My First COLDCARD Wallet
Give your kid a COLDCARD, but whitelist only their own addresses and set a 100k sat ceiling. They learn self-custody, yet external spends still need you to co-sign.
4. Weekend-Only Spending Wallet
Cap each withdrawal (e.g., 500k sats) and require a 72-hour gap between sends. You can still top-up Lightning channels or pay bills weekly, but attackers that have access to your device + pin will not be able to drain it immediately.
5. DIY Business Treasury
Finance staff use the COLDCARD to pay routine invoices under 0.1 BTC. Anything larger needs the co-founder’s off-site backup key.
6. Donation / Grant Disbursement Wallet
Publish the deposit address publicly, but allow outgoing payments only to a fixed list of beneficiary addresses. Even if attackers get the device, they can’t redirect funds to themselves—the policy key refuses to sign.
7. Phoenix Lightning Wallet Top-Up
Add a Phoenix Lightning wallet on-chain deposit addresses to the whitelist. The COLDCARD will co-sign only when you’re refilling channels. This is off course not limited to Phoenix wallet and can be used for any Lightning Node.
8. Deep Cold-Storage Bridge
Whitelist one or more addresses from your bitcoin vault. Day-to-day you sweep hot-wallet incoming funds (From a webshop or lightning node) into the COLDCARD, then push funds onward to deep cold storage. If the device is compromised, coins can only land safely in the vault.
9. Company Treasury → Payroll Wallets
List each employee’s salary wallet on the whitelist (watch out for address re-use) and cap the amount per send. Routine payroll runs smoothly, while attackers or rogue insiders can’t reroute funds elsewhere.
10. Phone Spending-Wallet Refills
Whitelist only some deposit addresses of your mobile wallet and set a small per-send cap. You can top up anytime, but an attacker with the device and PIN can’t drain more than the refill limit—and only to your own phone.
I hope these usecase are helpfull and I'm curious to hear what other use cases you think are possible with this co-signing feature.
For deeper technical details on how Co-Sign works, refer to the official documentation on the Coldcard website. https://coldcard.com/docs/coldcard-cosigning/
You can also watch their Video https://www.youtube.com/watch?v=MjMPDUWWegw
coldcard #coinkite #bitcoin #selfcustody #multisig #mk4 #ccq
nostr:npub1az9xj85cmxv8e9j9y80lvqp97crsqdu2fpu3srwthd99qfu9qsgstam8y8 nostr:npub12ctjk5lhxp6sks8x83gpk9sx3hvk5fz70uz4ze6uplkfs9lwjmsq2rc5ky
-
@ 90c656ff:9383fd4e
2025-05-04 17:06:06
In the Bitcoin system, the protection and ownership of funds are ensured by a cryptographic model that uses private and public keys. These components are fundamental to digital security, allowing users to manage and safeguard their assets in a decentralized way. This process removes the need for intermediaries, ensuring that only the legitimate owner has access to the balance linked to a specific address on the blockchain or timechain.
Private and public keys are part of an asymmetric cryptographic system, where two distinct but mathematically linked codes are used to guarantee the security and authenticity of transactions.
Private Key = A secret code, usually represented as a long string of numbers and letters.
Functions like a password that gives the owner control over the bitcoins tied to a specific address.
Must be kept completely secret, as anyone with access to it can move the corresponding funds.
Public Key = Mathematically derived from the private key, but it cannot be used to uncover the private key.
Functions as a digital address, similar to a bank account number, and can be freely shared to receive payments.
Used to verify the authenticity of signatures generated with the private key.
Together, these keys ensure that transactions are secure and verifiable, eliminating the need for intermediaries.
The functioning of private and public keys is based on elliptic curve cryptography. When a user wants to send bitcoins, they use their private key to digitally sign the transaction. This signature is unique for each operation and proves that the sender possesses the private key linked to the sending address.
Bitcoin network nodes check this signature using the corresponding public key to ensure that:
01 - The signature is valid. 02 - The transaction has not been altered since it was signed. 03 - The sender is the legitimate owner of the funds.
If the signature is valid, the transaction is recorded on the blockchain or timechain and becomes irreversible. This process protects funds against fraud and double-spending.
The security of private keys is one of the most critical aspects of the Bitcoin system. Losing this key means permanently losing access to the funds, as there is no central authority capable of recovering it.
- Best practices for protecting private keys include:
01 - Offline storage: Keep them away from internet-connected networks to reduce the risk of cyberattacks. 02 - Hardware wallets: Physical devices dedicated to securely storing private keys. 03 - Backups and redundancy: Maintain backup copies in safe and separate locations. 04 - Additional encryption: Protect digital files containing private keys with strong passwords and encryption.
- Common threats include:
01 - Phishing and malware: Attacks that attempt to trick users into revealing their keys. 02 - Physical theft: If keys are stored on physical devices. 03 - Loss of passwords and backups: Which can lead to permanent loss of funds.
Using private and public keys gives the owner full control over their funds, eliminating intermediaries such as banks or governments. This model places the responsibility of protection on the user, which represents both freedom and risk.
Unlike traditional financial systems, where institutions can reverse transactions or freeze accounts, in the Bitcoin system, possession of the private key is the only proof of ownership. This principle is often summarized by the phrase: "Not your keys, not your coins."
This approach strengthens financial sovereignty, allowing individuals to store and move value independently and without censorship.
Despite its security, the key-based system also carries risks. If a private key is lost or forgotten, there is no way to recover the associated funds. This has already led to the permanent loss of millions of bitcoins over the years.
To reduce this risk, many users rely on seed phrases, which are a list of words used to recover wallets and private keys. These phrases must be guarded just as carefully, as they can also grant access to funds.
In summary, private and public keys are the foundation of security and ownership in the Bitcoin system. They ensure that only rightful owners can move their funds, enabling a decentralized, secure, and censorship-resistant financial system.
However, this freedom comes with great responsibility, requiring users to adopt strict practices to protect their private keys. Loss or compromise of these keys can lead to irreversible consequences, highlighting the importance of education and preparation when using Bitcoin.
Thus, the cryptographic key model not only enhances security but also represents the essence of the financial independence that Bitcoin enables.
Thank you very much for reading this far. I hope everything is well with you, and sending a big hug from your favorite Bitcoiner maximalist from Madeira. Long live freedom!
-
@ c631e267:c2b78d3e
2025-04-04 18:47:27
Zwei mal drei macht vier, \ widewidewitt und drei macht neune, \ ich mach mir die Welt, \ widewide wie sie mir gefällt. \ Pippi Langstrumpf
Egal, ob Koalitionsverhandlungen oder politischer Alltag: Die Kontroversen zwischen theoretisch verschiedenen Parteien verschwinden, wenn es um den Kampf gegen politische Gegner mit Rückenwind geht. Wer den Alteingesessenen die Pfründe ernsthaft streitig machen könnte, gegen den werden nicht nur «Brandmauern» errichtet, sondern der wird notfalls auch strafrechtlich verfolgt. Doppelstandards sind dabei selbstverständlich inklusive.
In Frankreich ist diese Woche Marine Le Pen wegen der Veruntreuung von EU-Geldern von einem Gericht verurteilt worden. Als Teil der Strafe wurde sie für fünf Jahre vom passiven Wahlrecht ausgeschlossen. Obwohl das Urteil nicht rechtskräftig ist – Le Pen kann in Berufung gehen –, haben die Richter das Verbot, bei Wahlen anzutreten, mit sofortiger Wirkung verhängt. Die Vorsitzende des rechtsnationalen Rassemblement National (RN) galt als aussichtsreiche Kandidatin für die Präsidentschaftswahl 2027.
Das ist in diesem Jahr bereits der zweite gravierende Fall von Wahlbeeinflussung durch die Justiz in einem EU-Staat. In Rumänien hatte Călin Georgescu im November die erste Runde der Präsidentenwahl überraschend gewonnen. Das Ergebnis wurde später annulliert, die behauptete «russische Wahlmanipulation» konnte jedoch nicht bewiesen werden. Die Kandidatur für die Wahlwiederholung im Mai wurde Georgescu kürzlich durch das Verfassungsgericht untersagt.
Die Veruntreuung öffentlicher Gelder muss untersucht und geahndet werden, das steht außer Frage. Diese Anforderung darf nicht selektiv angewendet werden. Hingegen mussten wir in der Vergangenheit bei ungleich schwerwiegenderen Fällen von (mutmaßlichem) Missbrauch ganz andere Vorgehensweisen erleben, etwa im Fall der heutigen EZB-Chefin Christine Lagarde oder im «Pfizergate»-Skandal um die Präsidentin der EU-Kommission Ursula von der Leyen.
Wenngleich derartige Angelegenheiten formal auf einer rechtsstaatlichen Grundlage beruhen mögen, so bleibt ein bitterer Beigeschmack. Es stellt sich die Frage, ob und inwieweit die Justiz politisch instrumentalisiert wird. Dies ist umso interessanter, als die Gewaltenteilung einen essenziellen Teil jeder demokratischen Ordnung darstellt, während die Bekämpfung des politischen Gegners mit juristischen Mitteln gerade bei den am lautesten rufenden Verteidigern «unserer Demokratie» populär zu sein scheint.
Die Delegationen von CDU/CSU und SPD haben bei ihren Verhandlungen über eine Regierungskoalition genau solche Maßnahmen diskutiert. «Im Namen der Wahrheit und der Demokratie» möchte man noch härter gegen «Desinformation» vorgehen und dafür zum Beispiel den Digital Services Act der EU erweitern. Auch soll der Tatbestand der Volksverhetzung verschärft werden – und im Entzug des passiven Wahlrechts münden können. Auf europäischer Ebene würde Friedrich Merz wohl gerne Ungarn das Stimmrecht entziehen.
Der Pegel an Unzufriedenheit und Frustration wächst in großen Teilen der Bevölkerung kontinuierlich. Arroganz, Machtmissbrauch und immer abstrusere Ausreden für offensichtlich willkürliche Maßnahmen werden kaum verhindern, dass den etablierten Parteien die Unterstützung entschwindet. In Deutschland sind die Umfrageergebnisse der AfD ein guter Gradmesser dafür.
[Vorlage Titelbild: Pixabay]
Dieser Beitrag wurde mit dem Pareto-Client geschrieben und ist zuerst auf Transition News erschienen.
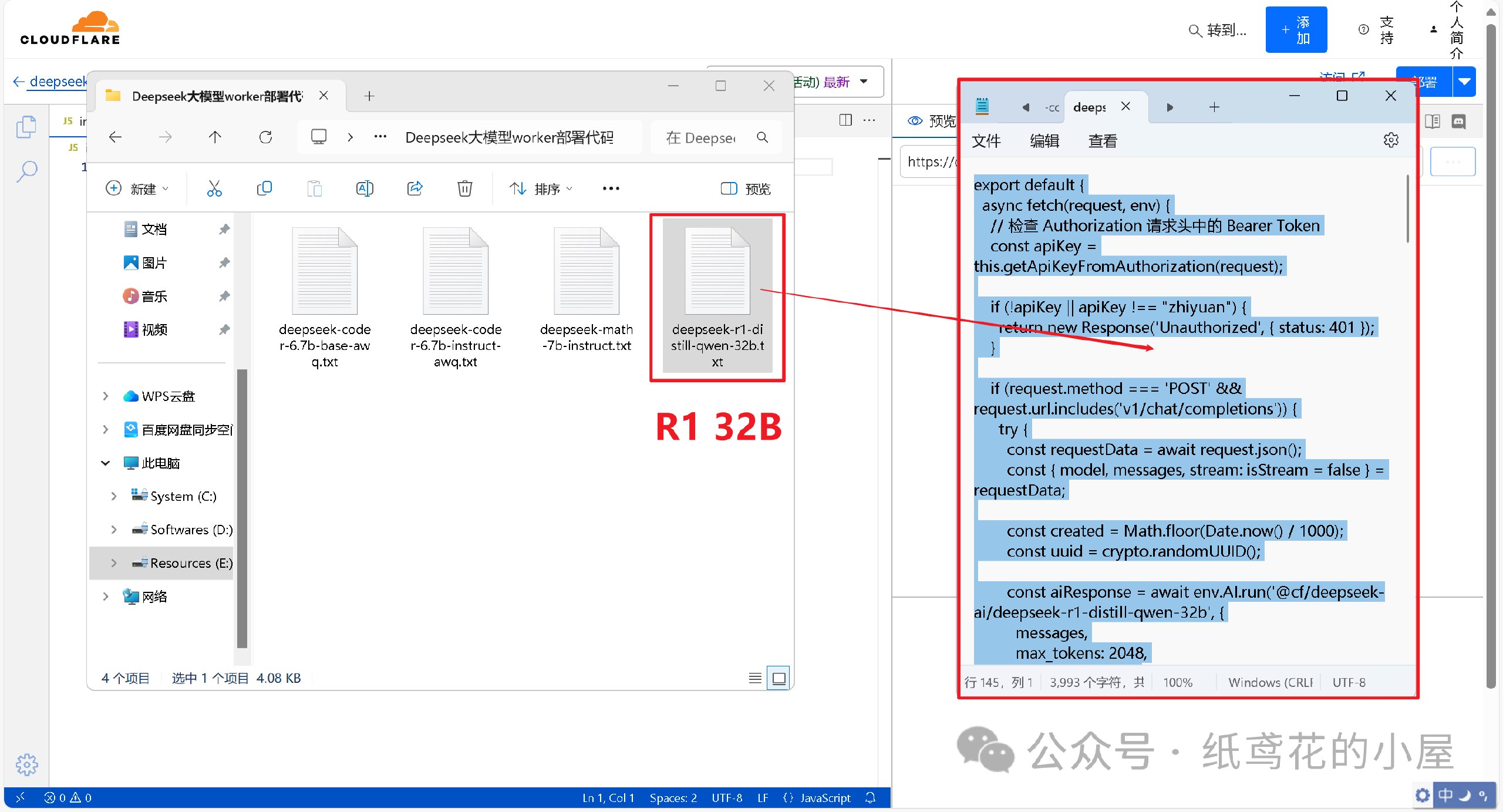



{kind=link}