-
 @ semisol
2025-05-03 04:42:13
@ semisol
2025-05-03 04:42:13Introduction
Me and Fishcake have been working on infrastructure for Noswhere and Nostr.build. Part of this involves processing a large amount of Nostr events for features such as search, analytics, and feeds.
I have been recently developing
nosdexv3, a newer version of the Noswhere scraper that is designed for maximum performance and fault tolerance using FoundationDB (FDB).Fishcake has been working on a processing system for Nostr events to use with NB, based off of Cloudflare (CF) Pipelines, which is a relatively new beta product. This evening, we put it all to the test.
First preparations
We set up a new CF Pipelines endpoint, and I implemented a basic importer that took data from the
nosdexdatabase. This was quite slow, as it did HTTP requests synchronously, but worked as a good smoke test.Asynchronous indexing
I implemented a high-contention queue system designed for highly parallel indexing operations, built using FDB, that supports: - Fully customizable batch sizes - Per-index queues - Hundreds of parallel consumers - Automatic retry logic using lease expiration
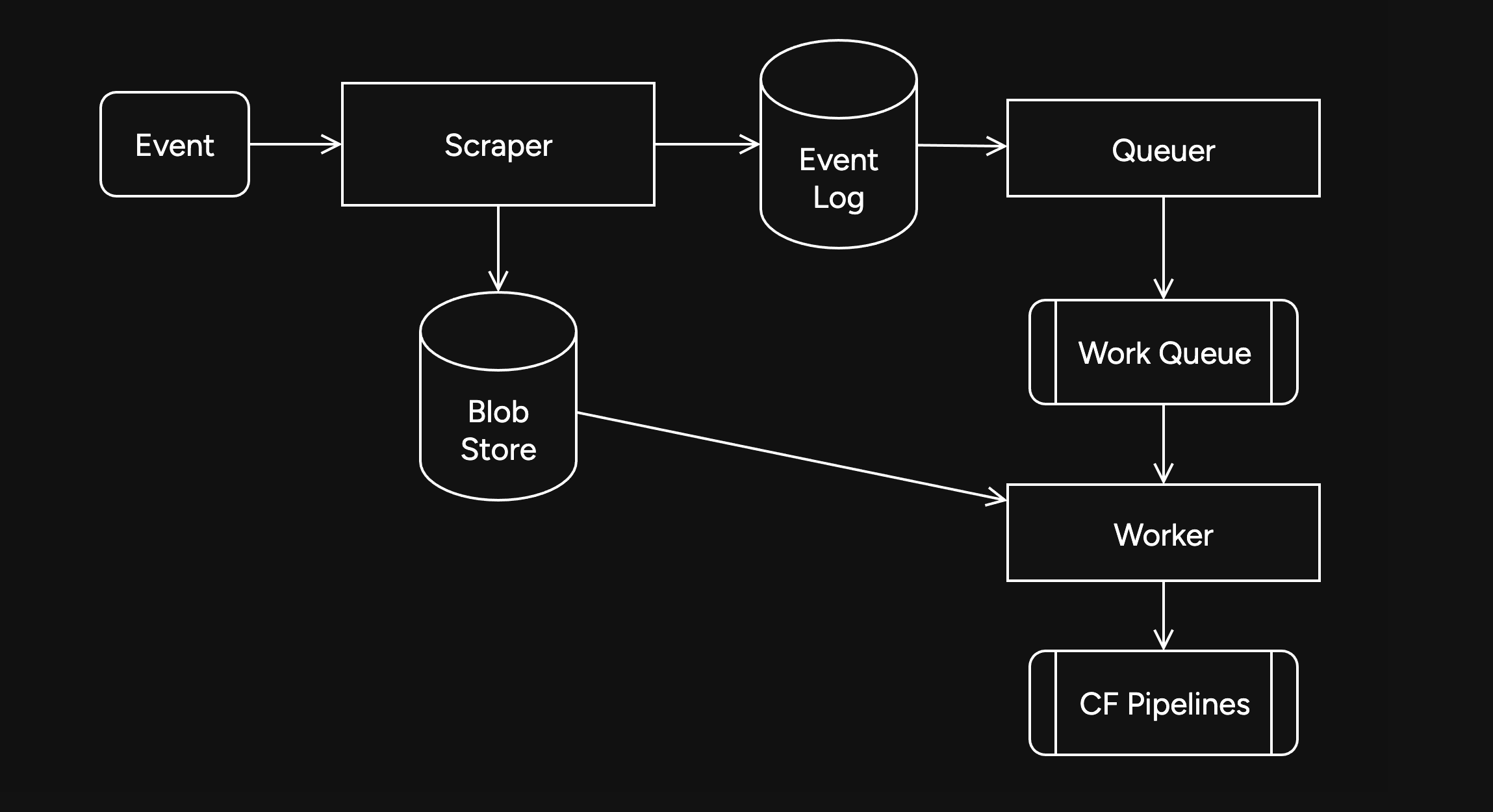
When the scraper first gets an event, it will process it and eventually write it to the blob store and FDB. Each new event is appended to the event log.
On the indexing side, a
Queuerwill read the event log, and batch events (usually 2K-5K events) into one work job. This work job contains: - A range in the log to index - Which target this job is intended for - The size of the job and some other metadataEach job has an associated leasing state, which is used to handle retries and prioritization, and ensure no duplication of work.
Several
Workers monitor the index queue (up to 128) and wait for new jobs that are available to lease.Once a suitable job is found, the worker acquires a lease on the job and reads the relevant events from FDB and the blob store.
Depending on the indexing type, the job will be processed in one of a number of ways, and then marked as completed or returned for retries.
In this case, the event is also forwarded to CF Pipelines.
Trying it out
The first attempt did not go well. I found a bug in the high-contention indexer that led to frequent transaction conflicts. This was easily solved by correcting an incorrectly set parameter.
We also found there were other issues in the indexer, such as an insufficient amount of threads, and a suspicious decrease in the speed of the
Queuerduring processing of queued jobs.Along with fixing these issues, I also implemented other optimizations, such as deprioritizing
WorkerDB accesses, and increasing the batch size.To fix the degraded
Queuerperformance, I ran the backfill job by itself, and then started indexing after it had completed.Bottlenecks, bottlenecks everywhere

After implementing these fixes, there was an interesting problem: The DB couldn't go over 80K reads per second. I had encountered this limit during load testing for the scraper and other FDB benchmarks.
As I suspected, this was a client thread limitation, as one thread seemed to be using high amounts of CPU. To overcome this, I created a new client instance for each
Worker.After investigating, I discovered that the Go FoundationDB client cached the database connection. This meant all attempts to create separate DB connections ended up being useless.
Using
OpenWithConnectionStringpartially resolved this issue. (This also had benefits for service-discovery based connection configuration.)To be able to fully support multi-threading, I needed to enabled the FDB multi-client feature. Enabling it also allowed easier upgrades across DB versions, as FDB clients are incompatible across versions:
FDB_NETWORK_OPTION_EXTERNAL_CLIENT_LIBRARY="/lib/libfdb_c.so"FDB_NETWORK_OPTION_CLIENT_THREADS_PER_VERSION="16"Breaking the 100K/s reads barrier
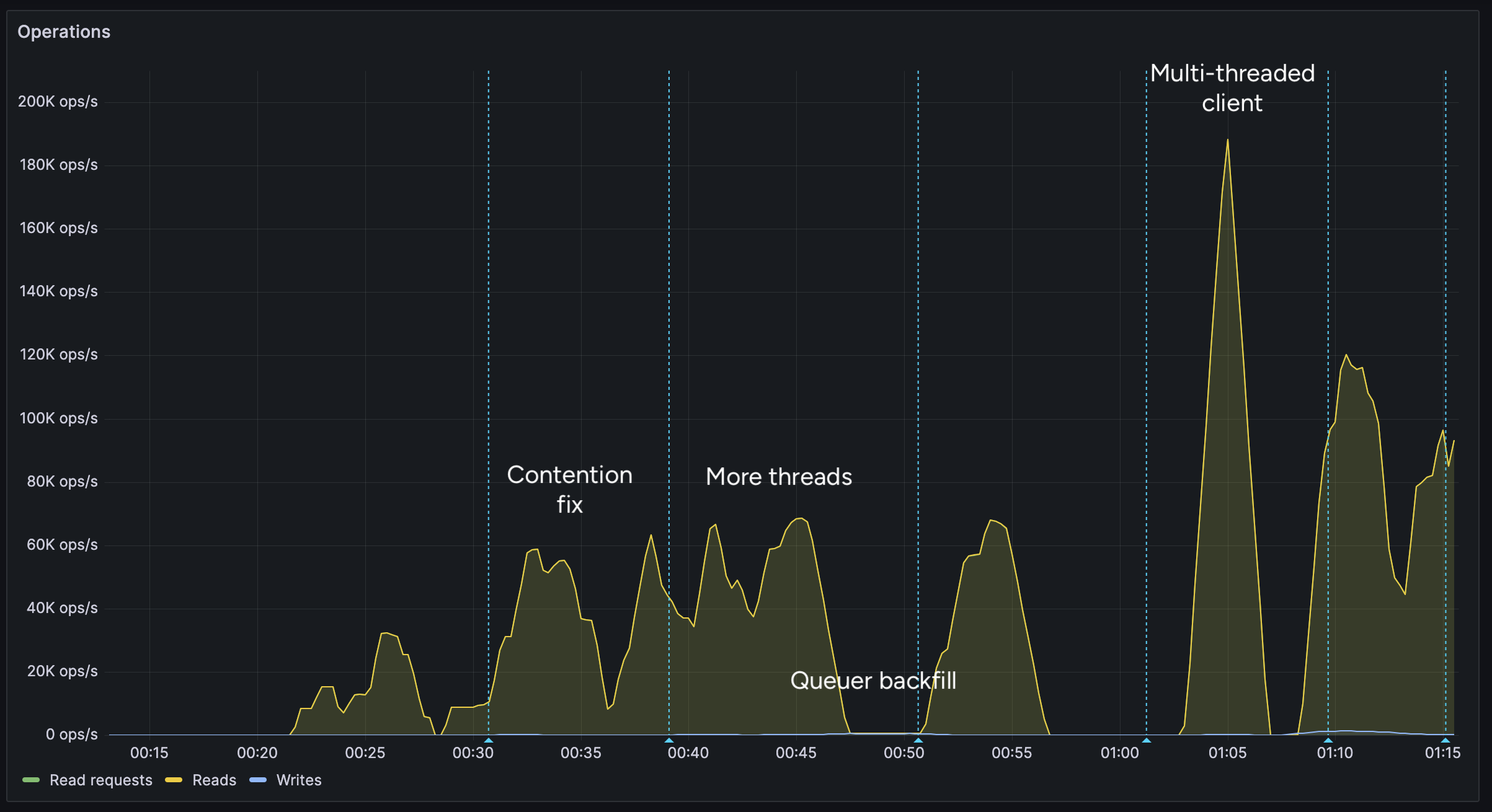
After implementing support for the multi-threaded client, we were able to get over 100K reads per second.
You may notice after the restart (gap) the performance dropped. This was caused by several bugs: 1. When creating the CF Pipelines endpoint, we did not specify a region. The automatically selected region was far away from the server. 2. The amount of shards were not sufficient, so we increased them. 3. The client overloaded a few HTTP/2 connections with too many requests.
I implemented a feature to assign each
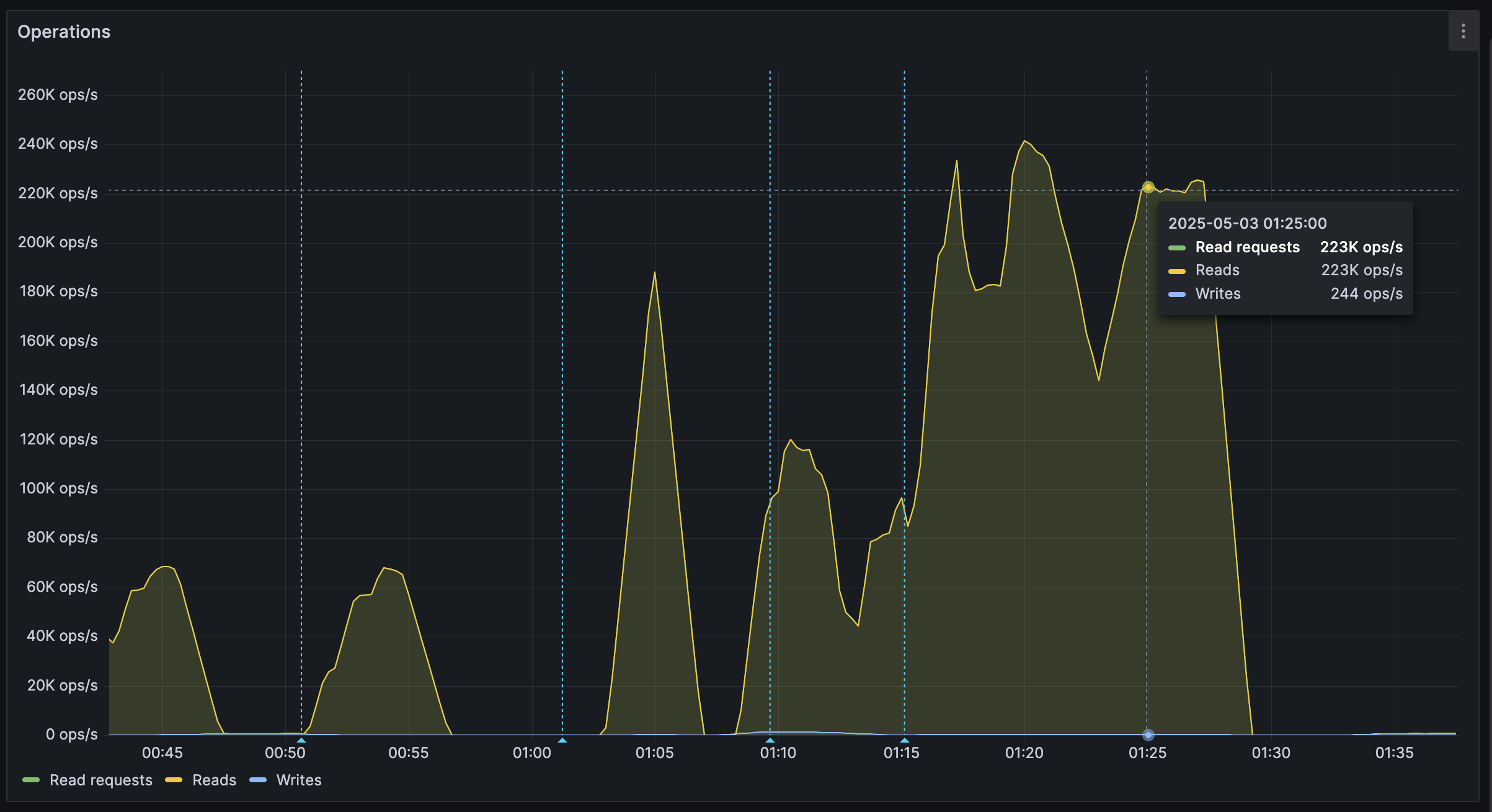
Workerits own HTTP client, fixing the 3rd issue. We also moved the entire storage region to West Europe to be closer to the servers.After these changes, we were able to easily push over 200K reads/s, mostly limited by missing optimizations:
It's shards all the way down
While testing, we also noticed another issue: At certain times, a pipeline would get overloaded, stalling requests for seconds at a time. This prevented all forward progress on the
Workers.We solved this by having multiple pipelines: A primary pipeline meant to be for standard load, with moderate batching duration and less shards, and high-throughput pipelines with more shards.
Each
Workeris assigned a pipeline on startup, and if one pipeline stalls, other workers can continue making progress and saturate the DB.The stress test
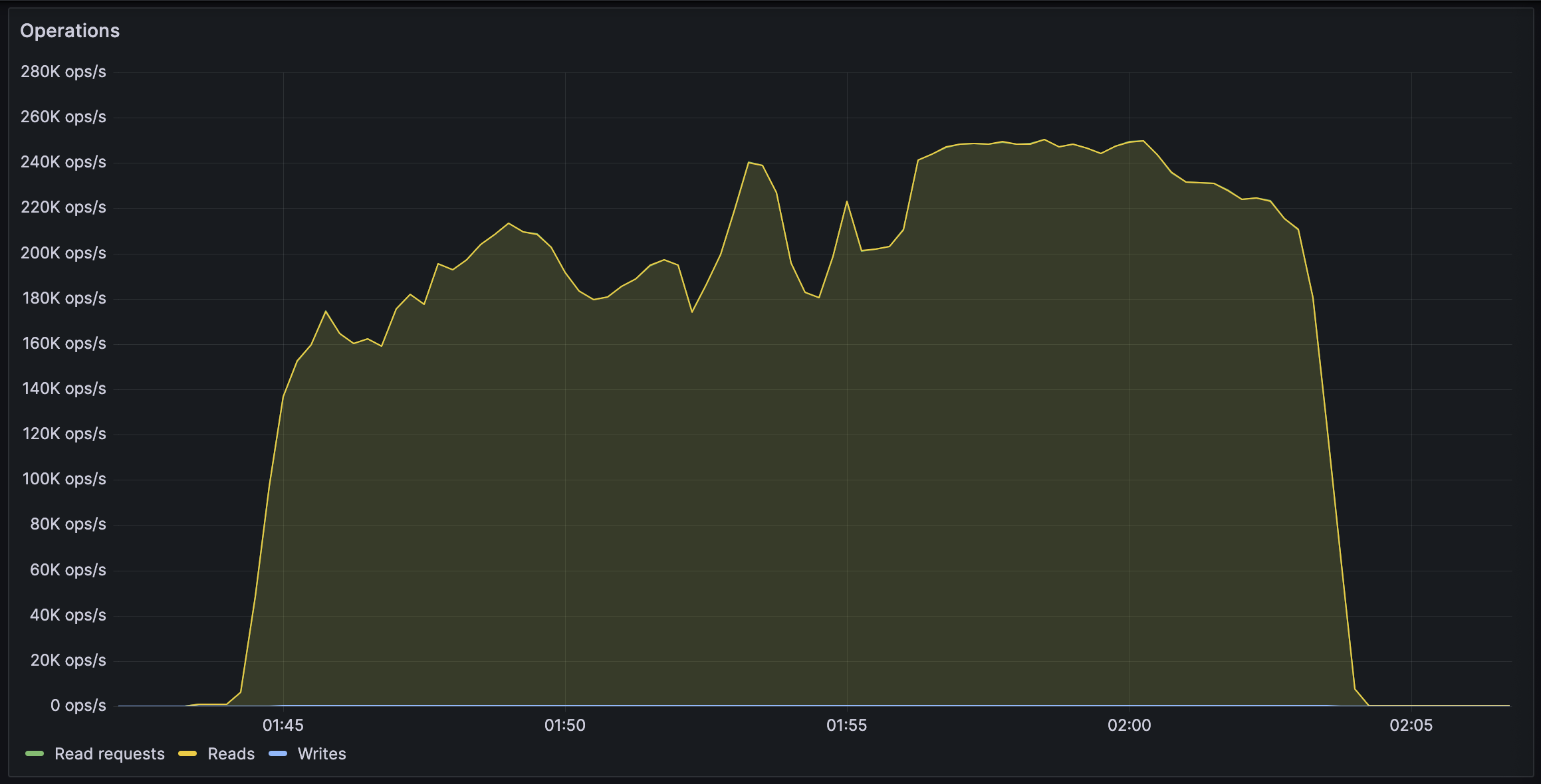
After making sure everything was ready for the import, we cleared all data, and started the import.
The entire import lasted 20 minutes between 01:44 UTC and 02:04 UTC, reaching a peak of: - 0.25M requests per second - 0.6M keys read per second - 140MB/s reads from DB - 2Gbps of network throughput
FoundationDB ran smoothly during this test, with: - Read times under 2ms - Zero conflicting transactions - No overloaded servers
CF Pipelines held up well, delivering batches to R2 without any issues, while reaching its maximum possible throughput.
Finishing notes
Me and Fishcake have been building infrastructure around scaling Nostr, from media, to relays, to content indexing. We consistently work on improving scalability, resiliency and stability, even outside these posts.
Many things, including what you see here, are already a part of Nostr.build, Noswhere and NFDB, and many other changes are being implemented every day.
If you like what you are seeing, and want to integrate it, get in touch. :)
If you want to support our work, you can zap this post, or register for nostr.land and nostr.build today.